API management shares much at a high level with the newer concept of a service mesh. How are they different from one another? What are each of their use cases, and how might they work in combination?
Why the comparison?
In recent years, as microservices architecture has started to mature, we have seen a need for increasingly sophisticated mechanisms for inter-communication between microservice components. Requirements include service discovery, routing, traffic management, security and more. To this end a capability that has come to be known as a “service mesh” has been introduced to enable us to do these things consistently. However, we already have API management that appears to tackle that very same range of problems – routing, traffic management, security and so on. What is the difference between the role of the service mesh, and that of API management? In this post we will clearly articulate the different roles of each, to help clarify when you should use which. We’ll then also go on to consider how the two can work in a complementary fashion to achieve even more interesting use cases.
API management in relation to microservices
In a recent
post we discussed the role that API management plays in relation to microservices applications. Microservice components rarely if ever exist alone. They are normally grouped together to make up what we might previously have called an “application”.
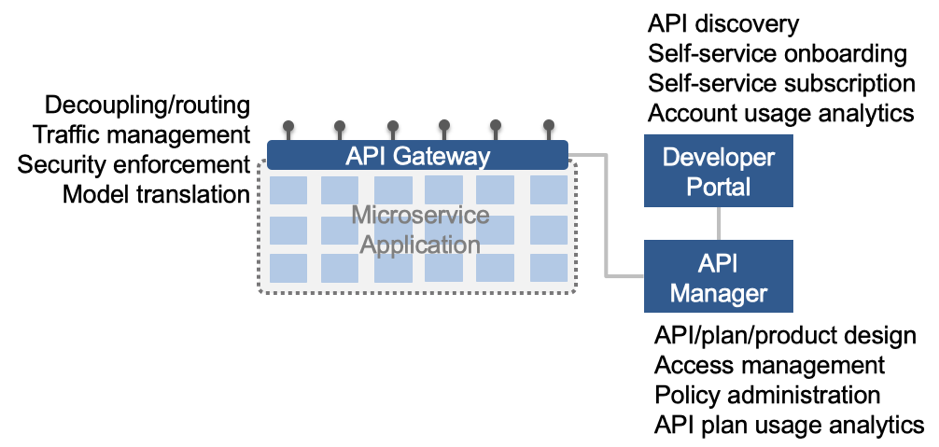
API management guards the boundary of the application, controlling how the application makes itself available to other applications within and beyond the enterprise. It allows consumers to explore the APIs available via a straightforward portal, and subscribe to an appropriate plan of use for the ones they want to use. Then, at runtime, it enables us to recognize, control and perhaps even bill differing types of consumers of the APIs. It ensures that all consumers are identifiable, and can be managed separately in terms of traffic, access control, and more. It also ensures that the underlying implementations remain abstracted from the way that the APIs are ultimately exposed, performing any necessary routing and translation along the way.
In short, an API management capability such as
IBM API Connect protects and controls the external boundary of a group of microservice components; the boundary of a microservice “application”.
What is a service mesh?
Now that we have a clear definition of the role of API management on the boundary of a microservices application we can take a look at what a service mesh might then provide on the inside of that boundary.
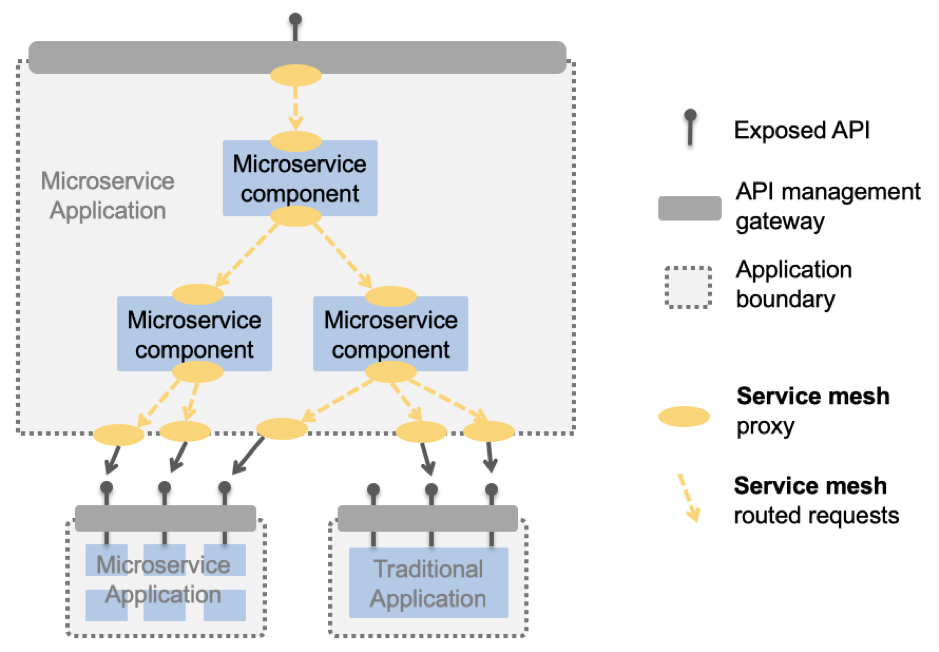
The core benefit of breaking a complex application into a number of smaller microservice components is that each component is fully decoupled from the others. It can be maintained, or even replaced completely independently of the rest of the application. This is after all what enables the greater agility, scalability and resilience benefits that microservices architecture provides. However, few microservice components are completely isolated. Most have a role that involves communication with other microservices in the application. It is here where fragility can easily creep back into the application, reducing its agility and resilience.
Many libraries and frameworks have evolved to help reduce the coupling effects of direct interactions between microservice components. For example, standardized ways of performing sophisticated load balancing, and version-based routing. Another common example would be implementations of the circuit breaker pattern to reduce the effect of a struggling downstream system on the caller. These capabilities had to be embedded in each microservice component, increasing the complexity of its code, and coupling it to the libraries and frameworks.
The industry has begun to standardize on container orchestration platforms such as Kubernetes to administer microservice components at scale. It therefore became logical to try to provide some of these inter-microservice communication capabilities in a more standardized way too. More importantly, a way that was independent of the individual microservice components. Kubernetes itself provides a basic functionality, enabling, for example, discovery of other microservices at runtime. It also enables dynamic load balancing across replicated containers, but for the moment that is pretty much as far as it goes.
This is where the service mesh comes in. The mesh intercepts all intercommunication between microservices in a given scope (or application boundary). It can then introduce things such as routing, resilience and security patterns completely independently of the microservices themselves. Effectively, it extends the number of inter-connectivity patterns available to Kubernetes.
Let’s have a look at some of the challenges a service mesh can help address:
- Inter-microservice security – How do we enforce security across our microservices application? How does any given microservice ensure that the requests that are being made to it are from a valid source, and one that is allowed to make that request? How could we consistently enforce encryption on inter-communication to ensure sensitive data is never visible on the wire?
- Deployment patterns – Introducing new versions of microservices is the point where we’re most likely to break things. Being able to introduce the new version to just a small percentage of requests, or a specific type of request, enables us to ease new functionality in gently. It also allows us to quickly back it out if we see problems. This is a simplified description of “canary releases”, a common pattern in lightweight application deployment. Furthermore, what if we want to trial two different versions of a new feature simultaneously to see which works most effectively with our users. This is typically referred to as A/B testing and would be very hard without the rule based routing mechanism provided by a service mesh. These and other deployment patterns are well suited to a service mesh as they can often be done purely at the level of the inter-microservice routing logic.
- Fault tolerance – Dependencies on downstream components show their ugly side as soon as those components are unavailable or running slowly. We therefore need to implement patterns to help isolate the caller from these issues. Common examples are a) to simply do retries until the call succeeds, or b) to implement a circuit breaker pattern so after a few failed attempts we don’t try to call the downstream system for a while, or c) to put rate-limiting in place to ensure we don’t overwhelm a system with known limitations. Again, all of these can be implemented via a set of rules within the inter-microservice routing logic and need not clutter the microservice implementation itself.
- Visibility – In a microservice application we clearly have an increased number of components to worry about. Worse still, they are dynamically changing as they are scaled up and down by the orchestration system. For manageability we want to have a common way to gather logs and metrics from those components, and indeed to generate and analyze detail tracing when things go wrong. Since it is intercepting all requests, the service mesh is perfectly placed to provide a consistent mechanism for collating and processing logs.
- Testing – We will need to be able to test aspects of our complex multi-microservice application in isolation. We don’t want all of our tests to be dependent on the availability of downstream systems. We also might want to explore the behavior of our components when they receive certain types of faults from downstream applications, without having to force those faults to happen in the real systems. A service mesh is clearly in an excellent position to inject these types of simulated responses without any adjustment of the microservices themselves, nor any need to introduce “stubs” for the downstream systems.
We can see the service mesh provides us with a generic mechanism for intercepting inter-microservice communications. It enables us to introduce aspects such as security, routing, monitoring, and testing capabilities with no changes to the microservice components themselves.
This is by no means meant to be an exhaustive list of the possible uses of a service mesh. Furthermore, this field is at an early stage of maturity and thereby constantly changing. For more information on the current thinking, take a look at an example of a service mesh implementation such as
Istio, which is commonly used in Kubernetes, and available in
IBM Cloud Kubernetes Service.
How is API management different from a service mesh
We’ve shown that API management and the service mesh apply to very different scopes. API management focuses to how APIs from a group of microservices are
exposed to other groups. In comparison, the service mesh provides routing
within the group. To re-enforce this difference, it is perhaps worth briefly looking at just how differently the two capabilities tackle the problem of inter-communication. This will help explain why they are so well suited to their respective scopes of use.
API management is typically performed using the gateway proxy pattern. In this discussion focused on microservices architecture, this means a gateway in front of the group of microservices that make up an application. Callers (consumers) of the APIs need no knowledge of how the APIs are implemented. For example, how they are replicated for scaling purposes, or how high availability is provided. They only need to know their way to the gateway, which will then perform the redirection on their behalf. Any interconnection patterns such as traffic management or version based routing are performed by the gateway. The configuration of the gateway can be seen to be part of the API’s implementation. If you like, the gateway belongs to the
provider side of the equation.

In comparison, a service mesh typically uses the sidecar proxy pattern. There is no gateway, and instead the caller (
consumer) has to be aware that it lives within the mesh. As such, it has client-side code that is part of the mesh. That code knows how to look up the addresses of the downstream “provider” replicas, and how calls should be balanced across those replicas. It is also responsible for knowing whether to perform retries, and even implementing patterns such as the circuit breaker mentioned above.
In a service mesh that client code no longer need be embedded into the calling component. Instead it can be implemented invisibly by what is typically termed a “sidecar” that lives alongside the calling microservice. Most of the sidecars work is to manage the downstream calls (although it does intercept incoming upstream calls too). So it is essentially still logically part of the caller. That means most of these intercommunication patterns are being performed on the client, rather than the server side as they were in API management.
The above begins to highlight just how differently API management and the service mesh each enable interconnection between components. These differences and more are summarized in the following table:
| API Management | Service Mesh |
| Discovery | Provides a rich user portal that API consumers can visit to explore and self-subscribe to use the available APIs. | Maintains a low level service registry used by the client sidecar to find available replicas of the required microservice component. |
| Routing point | Server side | Client side |
| Routing component | Independent API gateway component, introducing an extra network hop. | Sidecar on client, which effectively becomes part of the local network stack. |
| Load balancing | The API gateway provides a single entry point (URL) then redirects to the implementation, often delegating load balancing to the underlying implementation (although most gateways can perform load balancing too). | Typically performed by client sidecar, which receives the list of replicas of the required service from the service registry, and implements the policy defined load-balancing algorithm. |
| Scope | One API gateway might expose APIs from many separate applications | Limited to a closely related set of microservice components that make up an application, such as the containers within a Kubernetes namespace. |
| Network | Sits on the boundary between the external (potentially public) network, and the internal application network. | Enables communication only within the application’s network boundary. For example, that provided by the namespace in Kubernetes. |
| Logs and metrics | Captures invocation statistics on the application boundary such as number of invocations through the gateway. | Emits cross-component tracing within the scope of the mesh. |
| Analytics | Analytics on API usage collated, analyzed and made available via a user interface to both consumers and providers of the APIs. | Enables telemetry to be published for any microservice component in the mesh. Collation/analytics is not typically part of the mesh's role. |
There are also differences in the security models used. For example, API management often uses techniques such as basic HTTP authentication, OAuth and application key/secret pairs to protect exposed APIs. A service mesh is often used to enforce mutual TLS, and introduce granular role-based access control between components within the mesh. However, the permutations and subtleties of these security models are too complex to summarize appropriately in this short blog post.
API management and the service mesh working together
How invocations flow through the service mesh is determined by policies. Those policies define how requests will propagate between one component and another. Mostly these policies are based on data about topology of the components within the mesh, and historical information about past requests. For example, which component is talking to which other component, how many requests have recently passed between them, how many have failed, or how fast they have responded. The policy rules can then determine whether requests are authorized, how to distribute them across replicas, whether the downstream components are getting overloaded and so on.
It is interesting to consider what further information could be provided to those policies to enable more sophisticated rules to be created. As invocations pass through the API management layer, a lot of potentially useful context is known. However, that information is not propagated - it is not available as it passes down through the invocation chain. An obvious example would be what product or plan the calling system was subscribed to, or the identity of the application making the request.
If this information could be passed on down the invocation chain, perhaps in a prescribed way within the HTTP headers, it could then be acted on by the policies within the mesh. A mesh routing rule could, for example, route a proportion of requests from a specific application differently. It could route callers subscribed to a particular plan to a new version of a service. So the context available from the API management gateway could have many uses within the mesh.

Whilst there are some really creative possibilities here, we should probably consider some guardrails. We are effectively enabling some
leakage between the exposure layer (API management) and the internals of the application (the service mesh). However, for agility we should be trying to keep a good separation between interface and implementation. Certainly, it would probably be unwise for the code of individual microservices to become aware of metadata passed down the invocation chain from the API gateway. However, using the metadata in service mesh policies to ensure that routing logic remains separate from the microservice code, would seem to retain a good separation of concerns.
Another way in which we might see API management and the service mesh working in concert together would be end to end tracing for diagnostics. It is certainly good to be able to see how things are flowing across the mesh. However, it is much more powerful if we can also tie that for example to statistics about the overall response time seen at the gateway by the consumer.
There’s also the question of to what extent the API gateway is knowingly an entry-point onto the service mesh. Is the API gateway separate from the technology used to control the entrypoint into the service mesh, or could these two be merged? How tightly integrated the API gateway is into the container platform’s mechanism for controlling inbound traffic (typically called an “ingress” in service mesh terminology). If you're interested in reading more there is a further post on
use of the IBM API Connect and the underlying DataPower gateway in conjunction with the Istio service mesh.
Conclusion
API management excels around socialization and self-subscription of APIs, and security
across application boundaries. A service mesh is more about the
internal routing and resilience patterns required within an application boundary.
Clearly API management and the service mesh have independent roles, and it is important that we respect the boundary between those in the way that we design our API implementations. However, that doesn’t stop them from working collaboratively with one another to achieve even more graceful solutions to end to end routing.