
Introduction
IT and network management tools have to strike a balance between being flexible or not. Flexibility allows management tools to adapt to unpredictable data sources and requirements whereas less flexible tools are more rigid and can find it hard to adapt. The price of being highly flexible tends to be that a tool is more complex and can be harder to upgrade, configure and maintain.
IBM Cloud Pak for AIOps' Topology Manager solves the complex problem of managing multi-vendor, multi-technology environments and applications. We took the decision to take the middle-ground on flexibility with Topology Manager as we wanted it to be highly capable and adaptive but not so flexible as to be a potential issue for us and our customers. For example, high-level language support is great for flexibility but it can mean we don't know how the product is being used and customised. Instead, we chose to hide many complex functions while providing a small set of data processing types to the user via a common administration experience. The configuration of these data processing capabilities is expressed as JSON records known as rules.
In this article, we explore Topology Manager's data processing primitives, the principles of rules and how they work. We hold short of deep diving into the different data processing types and how to build a topology in this article as they warrant their own articles. Also check out Kilian's latest article at the following link:- https://community.ibm.com/community/user/aiops/blogs/kilian-collender/2024/11/27/unleash-topology-manager?CommunityKey=6e6a9ff2-b532-4fde-8011-92c922b61214.
Topology Manager's Data Model
Before discussing data processing types and their associated rules, we need to look at what we're trying to achieve. Topology Manager uses a time-series graph and relational database in parallel to model the environment being managed as a topology of resources (vertices), their properties, state and relationships (edges) between resources. A resource in Topology Manager can be anything that the user needs to manage with common examples being servers, Kubernetes deployments, applications, routers, switches and network ports. This data can come from many sources with differing models and lifecycles that we need to derive a consistent model from.
Resources and relationships have extensible properties that help provide context to the user and help with data processing, visualisation and filtering. Check out the documentation for more information at https://www.ibm.com/docs/en/cloud-paks/cloud-pak-aiops/4.7.1?topic=apis-topology-api-reference
Let's say you were building a topology model of the classic sci-fi film "The Matrix" and you want to model that Neo knows Morpheus and Trinity, that they're the crew of the Nebuchadnezzar and that Morpheus battles Agent Smith and has state. Each character and concept is a resource in Topology Manager and the following diagram depicts the key concepts used - the main takeaways being:-
- Resources have properties, some of which such as 'uniqueId', 'name', 'mergeTokens', 'matchTokens' and 'tags' are reserved. Otherwise, Topology Manager is very flexible regarding what it can model - resources can have array/list and map/dictionary properties no problem. Some of the reserved properties enable various data processing types.
- Relationships have an 'edgeLabel' (family) value from a fixed set, such as 'association' and 'dataFlow'. The 'edgeType' property represents the type of relationship within its family, such as 'knows' isa association relationship. Edges can also have properties but not as flexibly as resources.
- Resources and relationships have timestamps for historical tracking purposes (not shown in the diagram, but they're reserved properties).
- Resources have an optional state model that is automatically driven by the topology integrations and/or by correlating events to resources.
- Resources can be arbitrarily related to each other but there are prescriptive models for devices, resource groups, connectivity and application/service models. See the examples at this link:- https://www.ibm.com/docs/en/cloud-paks/cloud-pak-aiops/4.7.1?topic=reference-topology-examples.
- Resources can be members of 0..n resource groups.

Given that Topology Manager obtains data from many sources, a natural question to ask is "what is the model we're looking to build"? The target model is a function of the data sources used and target use-cases with prescriptive recipes for device, connectivity, grouping and applications or services. The promise of Topology Manager is to provide a model that spans beyond what any one source can provide. For example, APM tools tend not to have good visibility of the network infrastructure that supports application communications. Similarly, network management tools tend not to have good visibility application-level communications between processes. It is apparent from the diagram that the target model is only derivable if taking a manager-of-managers approach and by taking advantage of any intersect points between different data sources, such as commonly seen IP addresses. If a natural intersect points do not exist, then it is necessary to add them.

Where does topology data come from and how is it managed?
Resources in topology manager come from micro services known as "Observers". Each Observer is dedicated to integrating with a specific source with commonly used ones being ITNM, File, ServiceNow, Dynatrace and VMware vCenter - the full list is here:- https://www.ibm.com/docs/en/cloud-paks/cloud-pak-aiops/4.7.1?topic=integrations-observer-jobs.
Each Observer type uses units of work known as a 'jobs' to get data from its source, process it and send it to the Topology micro service via Kafka as shown by the following diagram. Some Observer types, such as Kubernetes, can also automatically provide resource groups. Observer jobs either 'load' data from the source or 'listen' to data from the source. The difference is that load jobs can be considered as a batch process that can be scheduled to run frequently and/or that can be run on an ad hoc basis. Listen jobs are intended to consume a stream of data from a source to reflect changes as quickly as possible.
Load jobs typically get a snapshot of data from their source with little or no lifecycle data about the resources and relationships being retrieved, think of it in terms of running an SQL SELECT query against a database schema. Listen jobs typically see CRUD lifecycle data revealed from the source that we need to act on. Listen jobs typically need a counterpart load job to help bootstrap the model or to re-sync if the stream of data is interrupted.
Observers jobs provide data to the Topology Service in-terms of a 'provider' which serves as a namespace for the data. Everything provided by job ABC in the diagram is, in this case, provided in-terms of the provider ABC which is typically the case - an observer job instance is typically 1:1 with its provider and that is the basis of Topology Manager's lifecycle, processing and metadata management for incoming data.
Where do providers come from? Providers are typically built by the observer when creating the job but they can often be manually specified with caution. You might be asking why are providers are decoupled from observer jobs - can't the data just be provided in-terms of the job ABC? The reason they're decoupled is that some more complex integrations require two different types of job to act on each other's data, in which case a shared provider is used. Note that data from a given job's provider is considered to be unique only in-terms of that provider, as a result it's possible to see the same resource multiple times but more on that later.

You might now be thinking "how does Topology Manager manage lifecycle for load jobs if CRUD data is not revealed by the source?". It automatically keeps meta-data about what it sees or each job run and that is used to help decide whether or not a resource should be (soft) deleted or not. For example, if job ABC sees resources [alpha, beta, charlie] at time 1 and only [alpha, charlie] at time 2, then beta will automatically get deleted.
How do rules fit into this data flow? As we'll see below, in the majority of cases, rules provide the configuration necessary for Observer jobs to make their data ready for processing downstream by the services shown in the diagram. For example, the merge service is responsible for combining data from different sources but needs the appropriate data for that to happen.
Topology Data Processing Principles
Unlike other data types such as events, metrics and logs, the data and processing needed to build a topology can be highly fragmented and one can consider the challenge as being assembling a jigsaw when given a random set of pieces over long period of time. In real terms, this means that the individual resources and relationships you see in the product UI's may be sourced from many different data sources and APIs.
For example, the Kubernetes Observer is highly multi-threaded and runs many task threads in parallel to discover the topology of a nominated Kubernetes namespace. Each task obtains data about different facets of the namespace at different times, such as Pods and Deployments. Where possible, the data from these threads is processed in such a way so not to require their results to be held in Observer memory. This means that careful consideration must be given to relationships given one thread may only see pointers to records not yet returned by another thread and it's a similar story for the Topology micro-service which consumes data from Observers.
This processing is depicted by the following diagram, with the key takeaways being-
- The input data ordering and timing can be highly unpredictable and from multiple threads and sources at the same time. For example, one can may see a reference to a resource via a relationship without having the full payload for the referenced resource until a considerable time later. Topology Manager is able to reassemble data about resources, their relationships and state regardless of the order it is received in.
- The source providing data to a given Observer job may or may not have any lifecycle information about the resources, relationships and state it is providing, i.e. a snapshot. As a result, Topology Manager needs to automatically determine what should happen to the topology model in any scenario.
- Observer jobs are an ideal point from which to distribute data processing and enforce any specific data massaging activities that make sense.
- One may see references to the same resource from multiple perspectives, such as server1's IP address from both Network Manager and VMWare and Topology Manager needs a way of establishing whether or not this is indeed the case and, if so, model that appropriately.
- Topology Manager must attempt to unambiguously correlate events form event manager to topology resources whilst consuming topology data.
- There is no one-valid lifecycle model to apply to a topology constructed of multiple sources, each with their own opinion on resource lifecycle. As a result, Topology Manager reflects the lifecycle inherent in the Observer integration and source that provided the data, driving its history models for deletion, property, relationship and state changes as necessary. For example, VMware may consider a resource deleted before we see a corresponding update from the Network Manager integration. Topology Manager considers all integrations equal and so does not prefer one integrations' view of the world over another. As a result, if combining data from multiple sources, both of their perspectives as provided by the Observer's interpretation and modelling choices for a given source are respected.

Rule-Based Data Processing
Topology Manager needs to perform a number of data processing tasks to meet users' needs and to enable various product capabilities. Topology Manager aims to provide a simple and highly consistent experience for managing and configuring the various data processing types provided. See the documentation at the following link for more information:- https://www.ibm.com/docs/en/cloud-paks/cloud-pak-aiops/4.7.1?topic=elements-configuring-rules.
With the exception of file enrichment and event filtering, each data processing type enables further processing downstream of the Observer job sending data to the Topology micro-service via Kafka. The following screenshot shows the available data types when creating a new rule.
Does rules-based data processing work with relationships? No.
TOP TIP: You only need to use the data processing types below to meet a specific business goal.

Business Criticality Processing
Enables users to differentiate from otherwise similar resources and any associated state and incidents in terms of their importance to the business using their own terminology. For example, one may treat resources supporting a specific customer as being of 'Gold' business criticality because of their SLA with the AIOps user. Resources subject to this processing are given a businessCriticality property with a single value derived from a token expression. Business criticality is used in Topology Manager and can also be used in alert and incident processing and filtering.
TOP TIP: Business criticality should typically be assigned to resources that may require additional classification for incident management and planning use-cases, i.e. they're typically event-correlatable, subject to configuration changes or are field-replaceable units.
TOP TIP: You can use your own terminology for business criticality values, each also being assigned a numeric weight out of 100 which is used by alert manager to help prioritise. Common terminology examples include Gold, Silver, Platinum to reflect an SLA but you can 'bend' the terminology to other use cases too.

Event Filter Processing
Enables users to prevent status on specific resource types from being stored in Topology Manager and then generating AIOps alerts. For example, one may wish to prevent any state associated with servers from network manager from generating events into AIOps. Resources subject to this processing do not include any state the Observer saw about a resource or any events generated on its behalf in AIOps lifecycle (alert) manager.

TOP TIP: Event filter processing is useful if you don't want state from an Observer to participate in incident management and alert processing. Observers don't know what state data is downstream of them and as a result, they'll by default provide their state if available, from which alerts are generated. However, in some scenarios, you may not want state provided by (for example) the Kubernetes Observer, instead preferring an alert or metric-derived alert.
File Enrichment Processing
Enables users to enrich data from any source with their own data held in text files containing JSON records. For example, one may wish to enrich devices from network manager with data about the customers and services using those devices. Resources subject to this processing are enriched with JSON data from a record in a file based property value matches, for example switch2 in the above diagram may have a UUID as a 'uniqueId' that has a corresponding entry in a file enrichment file.

TOP TIP: File Enrichment processing is great if you want to enrich resources with your own data, including geographical locations. They serve as a good replacement for older style 'overlay' use case that used File or REST Observer jobs and merge processing. This is because they're more efficient as the Observer job acts on its data-in-motion to do the enrichment, rather than more expensive processing done by the merge service. They also don't need the meta-data tracking associated with Observer jobs by the Topology micro-service.
History Processing
Enables users to suppress the tracking of changes to generate history for nominated properties on specific resource types and instances from a given source, and creating a more efficient and targeted topology model. For example, one may wish to not track history of changes to property values that are expected to frequently change and don't provide a great deal of business value, such as a device uptime. Resources subject to this processing are given a historyExcludeTokens property with a set of property names to suppress history tracking of for the owning resource..

TOP TIP: Topology manager automatically tracks history of any resource property, relationship and state changes but some integrations can generate significant amounts of historical churn that can mask the really interesting changes. For example, if a source is providing high precision floating point values and you run it every ten minutes, then those values will contribute to the history charts and may make it tricky to find more important changes, such as a firmware update.
Match Processing
Enables users to enable event-to-resource correlation by specifying values that should be examined by the status service when trying to find a resource that unambiguously corresponds to an event. For example, one may wish to nominate device IP addresses as something to attempt correlation with. Resources subject to this processing are given a matchTokens property that contains a set of values to use used for event correlation.

TOP TIP: Event-to-resource correlation is enabled by resources holding values in their matchTokens set property. Best-practice is to make these as unique as possible so that Topology Manager can unambiguously correlate events to resources. However, as you'll see in another article, Topology Manager doesn't just use matchTokens on resources to try and unambiguously correlate events. Examples of high quality values that are likely to be unique include MAC addresses, UUIDs and public IP addresses.
Merge Processing
Enables users to merge resources from multiple sources that actually refer to the same thing. For example, one may wish to combine server data from Network Manager with the corresponding data from VMware if they share the same IP address, thus unifying the network and IT data from those sources. Resources subject to this processing are given a mergeTokens property that contains a set of values to attempt merging with.

TOP TIP: Merge processing can be summarised as supporting the following use-cases, although note that the File Enrichment rule may be a better way of doing the overlay use-case if you don't need to combine relationships.
TOP TIP: Merge processing doesn't require the resources to be merged to be of the same type or use the same properties to drive mergeTokens.

TOP TIP: Merging of resources is limited to a maximum of 20 different instances being combined. You want merge tokens to be as unique as possible to avoid over-merging and ambiguity and it's therefore best-practice to tightly scope merge rules. An example of a poor quality merge token value is a loopback IP address such as 127.0.0.1 whereas public IP addresses, MAC addresses and UUIDs are likely to be unique and so are considered to be high quality.
Tag Processing
Enables users to tag resources with data to improve visibility, search and filtering capabilities. For instance, one may wish to tag all resources coming from a DNS Observer job with a literal string containing the FQDN of the DNS name associated with that data. Alternatively, one may wish to tag routers from Network Manager with whatever the value of their sysContact property contains. Resources subject to this processing are given a tags property that contains a set of values.

TOP TIP: Tags are likely to use their meaning when set and so it's best-practice to qualify what a tag means by using a token expression that includes a literal. Consider the case where you use the value of a version property to tag resources and the value is an integer. If version=5 in the resource, by nominating version as the token property, you'd end up with a tag value of 5 which means what? If your token uses an expression to include version as part of it, then the tag of version:5 is instantly meaningful.
Group Token Processing
Enables users to group resources that share a token value. This enables the property-based equivalent of Dynamic Templates for groups but is used by Token Templates. For example, you have a property that denotes which cluster each device is part of and a device may be in more than one cluster. The use of Group Token Processing facilitates the creation of groups for each cluster. Resources subject to this processing will have a groupTokens set property.
See my article about groups and templates at the following link:- https://community.ibm.com/community/user/aiops/blogs/matthew-duggan/2024/11/17/aiops-from-the-source-groups.

Tag Group Processing
Enables users to group resources that share a tag value and is used by Tag Templates. For example, you have a tag that is a Kubernetes label that you want to group resources by. The use of Tag Group Processing facilitates the creation of a single group for the specified tags. Resources subject to this processing will have a groupTokens set property.
See my article about groups and templates at the following link:- https://community.ibm.com/community/user/aiops/blogs/matthew-duggan/2024/11/17/aiops-from-the-source-groups.
Topology Manager Rules
Rules provide the configuration necessary to enable a data processing type to be performed on resources that match their scope criteria. This done by Observer jobs that firstly determine whether or not a rule applies to a given resource and, if so, updating it or suppressing data being added to the resource depending on the rule type.
TOP TIP: You might be thinking "why do I need rules if I'm using the File or REST Observer as I control the data with those?". It's best-practice to use rules because they're configurable, flexible and you can enable and disable them as needed.
TOP TIP: Your rules and other configuration data can be backed-up and restored using the process described at the following link:- https://www.ibm.com/docs/en/nasm/1.1.22?topic=recovery-backing-up-restoring-ui-configuration-data-ocp.
Topology Manager uses the following terminology to describe rules.

Rules can be enabled and disabled - what happens if I disable a rule after it's been used? The next time the associated Observer job(s) run, any resources that were previously subject to rules would not be subject to them, i.e. a tag rule that previously applied would not then tag the same resource. Resources that are deleted in this situation by the new job run would be deleted and not honour any rules.
Do I get any rules out-of-the box? Yes. The Instana, SevOne, VMware vCenter, NewRelic, Kubernetes, Jenkins, HP NFVD, OpenStack, GitLab, Rancher, VMware NSX, BigFix Inventory, ALM, IBM Cloud, Docker, TADDM, App Dynamics, NetDisco, DataDog, AppDisco, Juniper CSO, Contrail, Ciena Blue Planet, Dynatrace, AWS, Cisco ACI, ServiceNow, Zabbix, GCP and Ansible AWX Observers all provide some rules out-of-the-box. Best-practice is to load your data incrementally and assess whether the processing is sufficient for your use-cases as some rules may need modifying, disabling or new rules created. The following screenshot shows what the rules look like in the admin UI page.

Why tokens and not values or variables?! Because this reflects the use of the data in the processing associated with the rule. They're not variables and they're not values, i.e. the result of the processing may be a value added to a resource property but the specific nature of the value depends on the token expression which itself is a value of the set of tokens property.
The following screenshot shows what the new tag rule UI page looks like.
What does a rule actually look like? The following JSON record shows a sample tag rule and the key properties. Note that it has fields that correspond to the UI and table above. In this case, the enabled rule uses the value of the customer property if set to tag hosts and it applies to any Observer type and any provider.
{
"name": "tag customer",
"_id": "awZTPL1USHO9jb6tnBxNcw",
"_createdAt": "2024-11-28T10:10:11.011Z",
"ruleType": "tagsRule",
"entityTypes": [
"host"
],
"tokens": [
"customer"
],
"ruleStatus": "enabled",
"observers": [
"*"
],
"providers": [
"*"
]
}
How do rules get associated with resources?
By the time a resource reaches the point at which rules are evaluated against it, an Observer job will have processed the resource so it will have a mix of mandatory and optional properties. It's these properties and associated logic that determines whether a given rule should be applied to a specific resource. Rule scope can be any combination of Observer type, Provider, resource entityTypes and matches against resource property values. For example, it's possible to define a rule that applies to every host's IP address property or to be very tightly scoped and apply only to hosts where their name matches a regular expression when loading a File Observer job for a specific file.
TOP TIP: It's best-practice to tightly scope rules to the resources you expect them to act on by choosing the appropriate characteristics when defining a rule. Typically, you should scope rules to at-least their entityType and Observer type that provides them because it gives you sufficiently fine-grained control over when a rule will apply to a resource and without affecting other Observer jobs. As you'll see, more advanced use-cases may require finer-grained scope control to target specific providers and specific resource instances.
The data processing performed is depicted by the following diagram with key takeaways being:-
- Topology Manager stores a library of rules.
- Topology Manager broadcasts rules to Observers and Observers choose the rules that are applicable to them based on the configuration of each rule. Observers can make use of the same rules and/or have very targeted and specific rules assigned to them. Many rules of the same type can apply to an individual resource.
- The data processing of in-scope rules is distributed and performed by Observer jobs on data-in-motion when they run. As a result, any new or modified rules may only be represented in the Topology Manager data after the Observe job(s) have run again.
- If a rule is applicable to a given Observer and it corresponds to a resource flowing through it, the Observer typically updates the resource or suppresses the addition of data to it.
TOP TIP: It's best-practice to configure and assess rules in a development environment before putting them into production.

Let's look at a worked example of the processing that's performed as shown by the following diagram which shows our enabled tag rule and three resources flowing through an Observer Job. The rule criteria and action are depicted in blue and green text and can be read as an if statement for scope and a then for the action if the scope is true.
Here's what happens:-
- uniqueId 1 is not a host as defined by the rule entityTypes property and so it is not subject to the rule.
- uniqueId 2 is a host and it has a non-null customer property value and so that value is copied to the tags set on this resource.
- uniqueId 3 is a host but it does not have a customer property and so it is not subject to the rule, i.e. an attempt is made to satisfy the rule.

Example Rule Scope Scenarios
The following examples show some typical examples for controlling rule scope. The admin UI for adding rules typically look like the following screenshot but we'll use the JSON payloads for brevity in the following examples.

Targeting specific resource entityTypes
You want to apply a rule to multiple entityTypes regardless of their Observer type and provider. For example, you want a scope that lets you use an accessIPAddress property in a match or merge rule for any host, router, server or switch seen that has that property.
{
"name": "Targeting specific resource entityTypes",
"keyIndexName": "Targeting specific resource entityTypes",
"_id": "BeX_FpC6TmielQsR8zVIkQ",
"_createdAt": "2024-12-01T22:18:02.378Z",
"ruleType": "mergeRule",
"entityTypes": [
"host",
"router",
"server",
"switch"
],
"tokens": [
"accessIPAddress"
],
"ruleStatus": "enabled",
"observers": [
"*"
],
"providers": [
"*"
]
},
Targeting a specific Observer and Provider
You want to apply a rule to a specific Observer job and any resources it provides that have an accessIPAddress or contact property regardless of their type. For example, you want to use accessIPAddress and/or contact values as a tag.
{
"name": "Targeting a specific Observer and Provider",
"keyIndexName": "Targeting a specific Observer and Provider",
"_id": "jWdVaUY3RBKb6eKu1YUKoA",
"_createdAt": "2024-12-01T22:24:51.570Z",
"ruleType": "tagsRule",
"entityTypes": [
"*"
],
"tokens": [
"accessIPAddress",
"contact"
],
"ruleStatus": "enabled",
"observers": [
"dns-observer"
],
"providers": [
"DNS.OBSERVER:A(1) / ibm.com / Recurse / 172.21.0.10"
]
},
Targeting a specific resource instance
You want to apply a rule to specific resource from a specific Observer job. For example, you want to use the name property as a merge token for a resource with a known name and type.
TOP TIP: You can exclude resources using an exact match expression too.
{
"name": "Targeting a specific resource instance",
"keyIndexName": "Targeting a specific resource instance",
"_id": "haNTvWB6SiquPMzFRKls_g",
"includeResource": [
"name=delaware2-rt-cs29.na.test.lab"
],
"_createdAt": "2024-12-01T22:38:02.315Z",
"ruleType": "mergeRule",
"entityTypes": [
"host"
],
"tokens": [
"name"
],
"ruleStatus": "enabled",
"observers": [
"file-observer"
],
"providers": [
"FILE.OBSERVER:itnm.txt"
]
},
Targeting resources using regular expressions
Topology Manager supports the use of regular expressions in both scope criteria and token expressions. For example, you want to target resources having a name starting with delaware so you can tag them with the services they're running.
TOP TIP: You can exclude resources using a regular expression too.
TOP TIP: You can specify multiple regular expressions but only a resource only has to satisfy one to be in-scope.
{
"name": "Targeting resources using regular expressions",
"keyIndexName": "Targeting resources using regular expressions",
"_id": "s5dMRSTcS9aky7UTMs8N2A",
"includeResource": [
"name=~/^delaware.*/"
],
"_createdAt": "2024-12-01T23:28:05.323Z",
"ruleType": "tagsRule",
"entityTypes": [
"*"
],
"tokens": [
"services"
],
"ruleStatus": "enabled",
"observers": [
"file-observer"
],
"providers": [
"FILE.OBSERVER:itnm.txt"
]
},
What do rules do to their associated resources?
Once the Observer job has determined that a rule should be applied to resource using its scope-filters, most rule types evaluate the set of specified token expressions to determine which updates should be made to the resource. In the case of file enrichment rules, the file attached to the rule is evaluated for a matching line and, if so, the JSON from the line is merged with the resource. In the case of event filter rules, state is removed. See the documentation at the following link for more details:- https://www.ibm.com/docs/en/cloud-paks/cloud-pak-aiops/4.7.1?topic=rules-reference.
Example Token Expression Scenarios
Token updates are the most frequent ones that you can expect to be performed given that tag, match and merge rules are the most commonly used at this time. Common updates performed based on the token expressions are as follows:-
Copying a property value
Copy the value of the specified property to the reserved property used by the rule. For example, if the following token expression was used in a tag rule, then a resource having an accessIPAddress property would have its value copied to the tags set.

Copying multiple property values
Copy the values of multiple properties to the reserved property use by the rule. For example, if the following token expression was used in a merge rule, then an in-scope resource having any of the specified properties with a value would have its value copied to the mergeTokens set.

Concatenating a literal string with a property value and delimiter
Concatenate a literal string with a delimiter and the value of the specified property. For example, if the following token expression was used in a tag rule, then an in-scope resource having a sysContact property with a value would have its tag-set updated to include a value such as contact:someone.

Copying multiple property values with a literal string and delimiter
Concatenate two property values with a delimiter and literal string. For example, if the following token expression was used in a merge rule, then an in-scope resource having both a host and steadyId property values would have its mergeTokens set updated to include a value such as myServer/pid/55. It would also have whatever the value of the uniqueId property copied to its mergeTokens set.

Using a literal string alone
Some scenarios require the use of a specified literal string in the token expression independently of any other properties provided by an Observer job. For example, if you wanted to tag every resource from a specific Observer job and provider with a value, you could use this technique. Firstly, define the token expression to reference a property and include your literal. In this case, we want every in-scope resource to be tagged with just mytag.

Then, specify an include token filter using a regular expression. This will ensure that the name value has a property but will not be interpreted as a value because there's no capture group used in the regular expression.

Referencing a deeply nested property
Reference the value of a nested property. For example, your resource data has a complex payload comprising lists and maps and you need to extract a particular property value. If the following token expression was used in a tag rule, then an in-scope resource having this property would have its tags set updated with the value of that property.
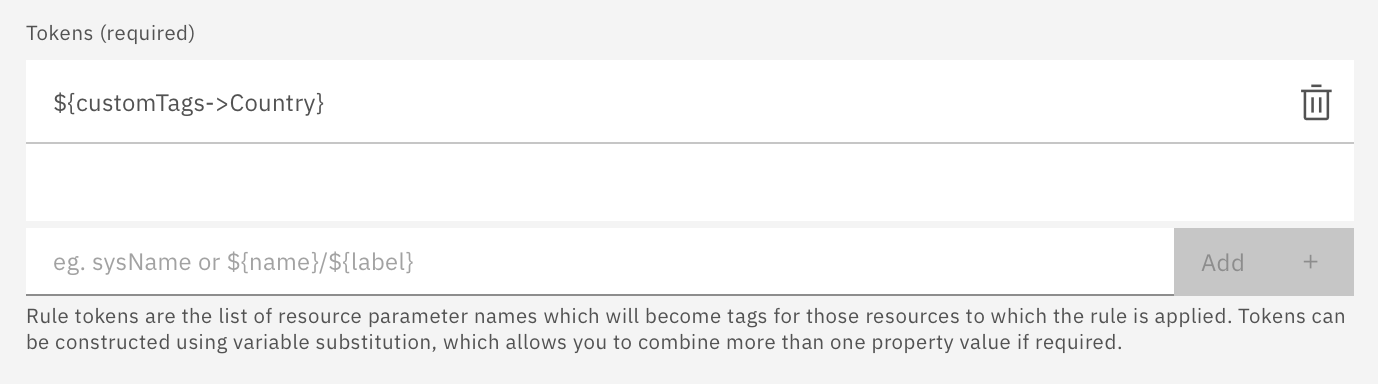
Using a regular expression
Use a regular expression to fine-tune the use of tokens in a rule. For example, you want to ensure that your match rule only applies to devices having a hostname starting with B. If the following token expression and filter was used in a match rule, then an in-scope resource having a name starting with B would have its matchTokens set updated with the value of that property. Firstly, define the token expression you want to use.
TOP TIP: Use regex capture groups in the token include filter to extract parts of a value for use in the token. For example, if you have a hostname of mydevice.ibm.com and only want to use mydevice, then a capture group that extracts that into a token is a useful way of mediating between subtle naming differences from sources when merging or matching data. If you do this, the value of the capture group will become the token referenced as ${property name}. TOP TIP: You can only use one capture group.

Then define the token filter to include the regular expression. NOTE: the use of an Include filter mode which will include any matching token values.

API Fun
Topology Manager provides a rich set of APIs across the product and rules are no exception. To try the APIs, follow the instructions to access the APIs and navigate to the Topology Manager merge service, the rules API are shown in the following screenshot.

As an example, here's a query to GET the configured tag rules and the corresponding result set.
curl -X 'GET' \
'https://aiops-topology-merge-cp4aiops.challenger/1.0/merge/rules?ruleType=tagsRule&_field=*&_include_count=false' \
-H 'accept: application/json' \
-H 'X-TenantID: cfd95b7e-3bc7-4006-a4a8-a73a79c71255' \
-H 'authorization: Basic ddddxxxxlpwbjZnUVFKQ2U5NXlQUFduSmErcE5JdlBjbVNBSGd1MndZRFJFPQ=='
{
"_executionTime": 45,
"_offset": 0,
"_limit": 50,
"_items": [
{
"name": "Tag Cisco devices in Colorado with their customer",
"keyIndexName": "Tag Cisco devices in Colorado with their customer",
"_id": "94SYfWkvTQmSMcAEMoxWzA",
"includeResource": [
"description=~/^Cisco.*/"
],
"_timeSinceLastUpdate": 2699322,
"createTime": 1733090477603,
"_observedAt": "2024-12-01T22:07:07.903Z",
"_createdAt": "2024-12-01T22:01:17.603Z",
"ruleType": "tagsRule",
"entityTypes": [
"host"
],
"tokens": [
"customer:${customer}"
],
"ruleStatus": "enabled",
"observedTime": 1733090827903,
"observers": [
"file-observer"
],
"providers": [
"FILE.OBSERVER:itnm.txt"
]
},
{
"name": "Targeting a specific Observer and Provider",
"keyIndexName": "Targeting a specific Observer and Provider",
"_id": "jWdVaUY3RBKb6eKu1YUKoA",
"_timeSinceLastUpdate": 1635657,
"createTime": 1733091891570,
"_observedAt": "2024-12-01T22:24:51.570Z",
"_createdAt": "2024-12-01T22:24:51.570Z",
"ruleType": "tagsRule",
"entityTypes": [
"*"
],
"tokens": [
"accessIPAddress"
],
"ruleStatus": "enabled",
"observedTime": 1733091891570,
"observers": [
"dns-observer",
"file-observer"
],
"providers": [
"DNS.OBSERVER:A(1) / ibm.com / Recurse / 172.21.0.10",
"FILE.OBSERVER:kubernetes.txt"
]
}
]
}
Final Thoughts
In this article you've learnt why Topology Manager has various types of data processing capabilities, how they work and how they're configured. You've learnt generally applicable best-practices when using rules and seen related APIs. In future articles, we'll build on this one by describing each data processing type with scenarios, tips and tricks.
What would your scenario be?