IBM Storage Ceph Object Storage Multisite Replication Series. Part Four
In the previous episode of the series, we discussed configuring dedicated RGW services for public and replication requests. Additionally, we explored the performance enhancements the sync fairness feature offers; if you missed it, here is the link for Part Three. In the fourth article on the series, we will be talking about Load Balancing our freshly deployed RGW S3 endpoints to provide high-availability and increased performance by load balancing the requests among the different RGW services available.
Load-Balancing the RGW S3 endpoints
Introduction
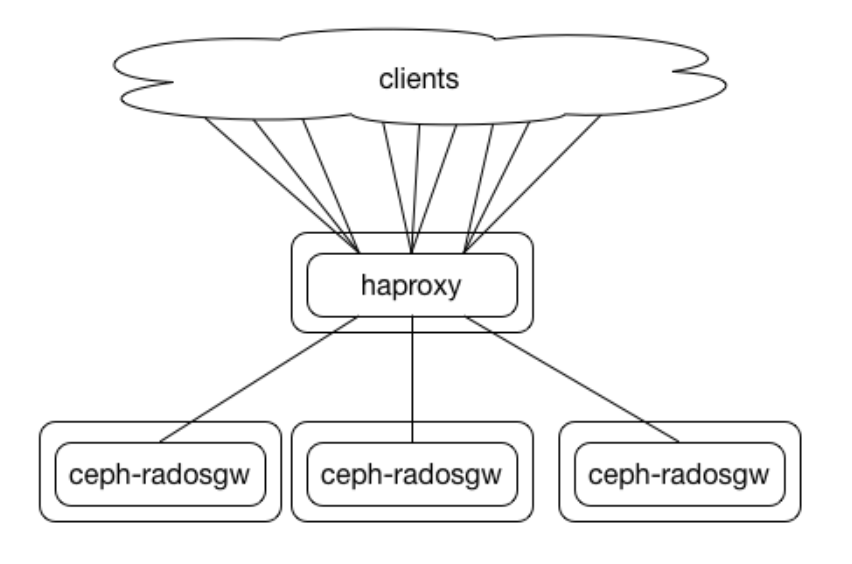
In the previous blog, we configured four RGW services, two dedicated to the client S3 API requests and the rest for the multisite replication requests. With this configuration, clients can connect to each RGW endpoint individually to use the HTTP restful S3 API, so they could, for example, run and S3 call like a list using as an endpoint the IP/FQDN of one of the nodes running and RGW service, example with the AWS s3 client: `$ aws –endpoint https://ceph-node02 s3 ls` They will be able to access their buckets and data.
The problem is, what happens if ceph-node02 goes down? The user will start getting error messages and failed requests, even if the rest of the RGW services are running fine on the rest of the nodes. To avoid this behaviour, providing High Availability and increased performance, we need to configure a load balancer in front of our RGW services. Because the RGW endpoints are using the HTTP protocol, we have many well-known solutions to load balance HTTP requests, which we can use, from hardware-based commercial solutions to open-source software-based load balancers. We need to find a solution that will cover our performance needs depending on the size of our deployment and specific requirements; there are some great examples of different RadosGW load-balancing mechanisms in this repo from Kyle Bader.
Inter-Site Replication Network
Each site's network infrastructure must offer ample bisectional bandwidth to support the de-clustered reading and writing of replicated objects or erasure-coded object shards. It is advisable to ensure that the network fabric of each site has either zero (1:1) or minimal oversubscription (e.g., 2:1). One of the most used network topologies for Ceph cluster deployments is Leaf and Spine as it can provide, if required the needed scalability.
Networking between zones participating in the same zone group will be utilised for asynchronous replication traffic. The intersite bandwidth must be equal to or greater than ingest throughput to prevent synchronisation lag from growing and increasing data loss risks. Intersite networking will not be relied on for read traffic or reconstitution of objects because all objects are locally durable. Path diversity is recommended for intersite networking, as we generally speak of WAN connections; the intersite networks should be routed(L3) instead of switched(L2 Extended Vlans) to provide isolated networking stacks at each site. Finally, even if we are not doing it in our lab example, Ceph object gateway synchronisation should be configured to use the HTTPS endpoints to encrypt replication traffic with SSL/TLS in production.
The Ingress Service Overview
Since the Ceph 5.1 downstream version, Ceph provides a cephadm service called ingress, which provides an easily deployable HA and load-balancing stack based on keepalive and HAproxy.
The ingress service allows you to create a high-availability endpoint for RGW with minimum configuration options. The orchestrator will deploy and manage a combination of HAproxy and keepalived to balance the load on the different configured floating virtual IPs.
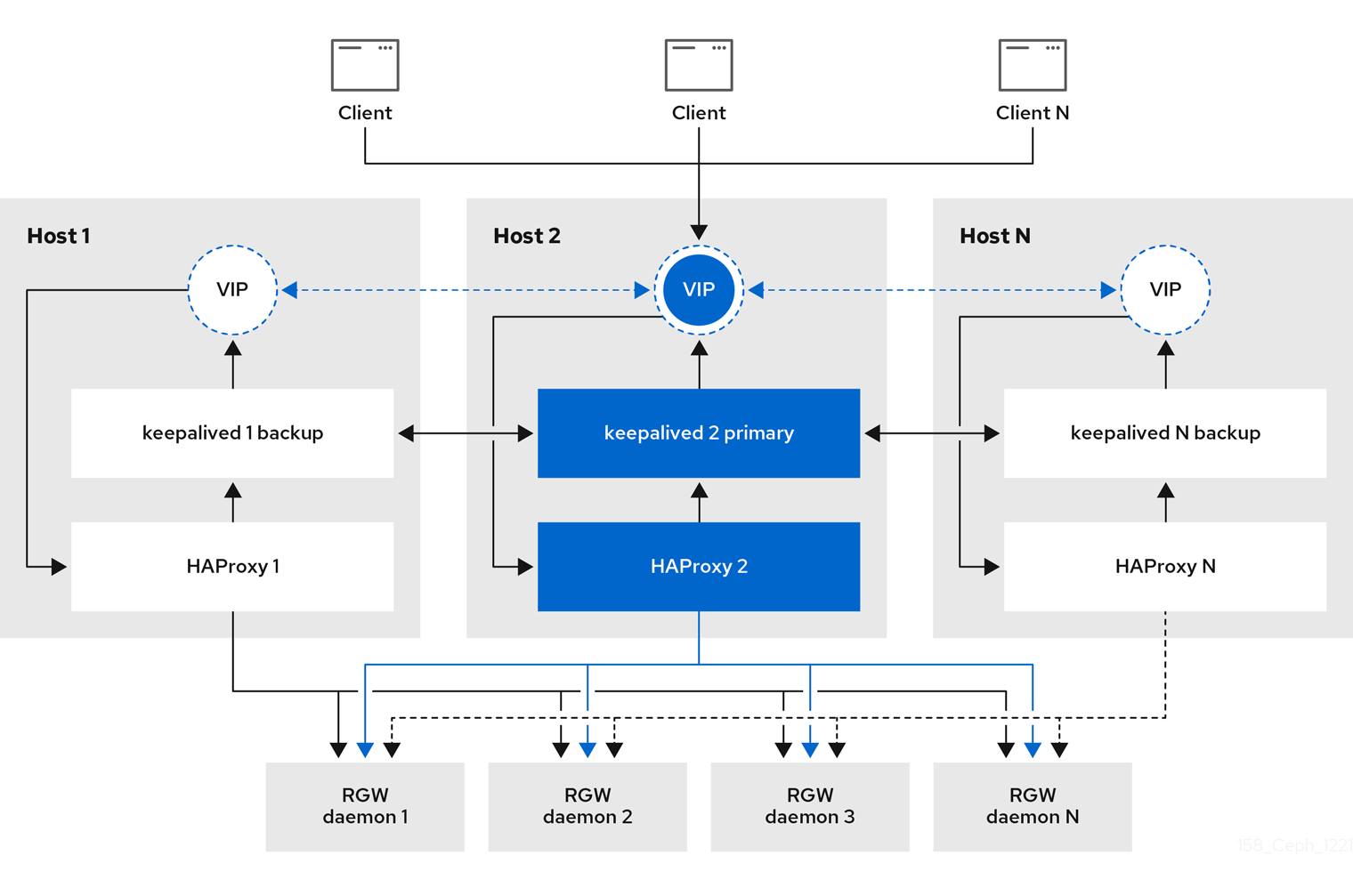
There are N hosts where the ingress service is deployed. Each host has an HAproxy daemon and a keepalived daemon.
By default, a single virtual IP is automatically configured by keepalived on one of the hosts; having a single VIP means that all traffic for the load-balancer will have to flow through a single host; this is less than ideal for configurations that will have to service a high number of client requests while maintaining high throughput, what we would recommend is configuring one VIP address per ingress node configured, we can then, for example, configure DNS round-robin among all the deployed VIP IPs, to load balance the requests among all the VIPs, this provides us with the possibility to achieve higher throughput as we are using more than one host to load-balance the client HTTP requests to our configured RGW services. Depending on the size and requirements of the deployment, the ingress service may not be adequate, and other more scalable solutions can be used to balance the requests, like BGP + ECMP.
Deploying the Ingress Service
In this post, we will configure the ingress load balancing service so we can load-balance all the S3 client HTTP requests between the public-facing RGW services we have running on nodes ceph-node-02 and ceph-node-03 in zone1, and ceph-node-06 and ceph-node-07 in zone2.
In the following diagram, we can depict at a high level the new load balancer pieces we are adding to our previously deployed architecture; in this way, we will provide HA and load balancing to our S3 client requests.
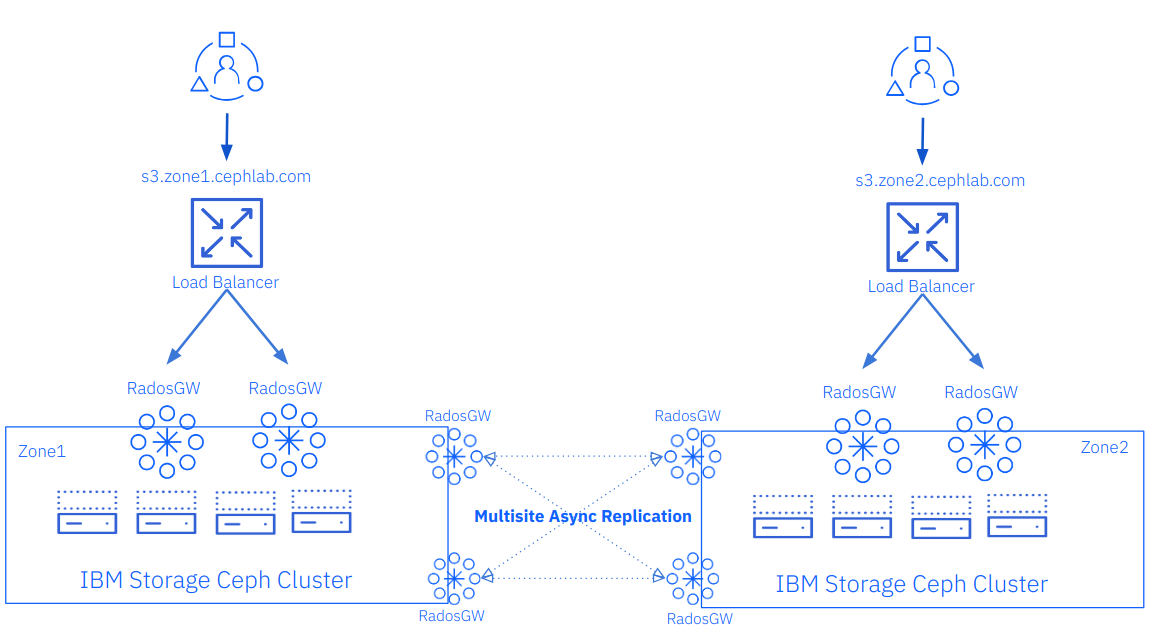
The first step is to create, as always, a cephadm service spec file; in this case, the service type will be “Ingress”, we need to use our current public RGW service name “rgw.client-traffic” to the service_id and backend_service parameters, we can get the name of the cephadm service names using the `cephadm orch ls` command.
We will configure one VIP per Ingress service daemon; we will configure two nodes to manage the ingress service to configure two VIPs per Ceph cluster. We will enable SSL/HTTPS for the client connections terminating at the ingress service.
[root@ceph-node-00 ~]# ceph orch ls | grep rgw
rgw.client-traffic ?:8000 2/2 4m ago 3d count-per-host:1;label:rgw
rgw.multisite.zone1 ?:8000 2/2 9m ago 3d count-per-host:1;label:rgwsync
[root@ceph-node-00 ~]# cat << EOF > rgw-ingress.yaml
service_type: ingress
service_id: rgw.client-traffic
placement:
hosts:
- ceph-node-02.cephlab.com
- ceph-node-03.cephlab.com
spec:
backend_service: rgw.client-traffic
virtual_ips_list:
- 192.168.122.150/24
- 192.168.122.151/24
frontend_port: 443
monitor_port: 1967
ssl_cert: |
-----BEGIN CERTIFICATE-----
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
-----END CERTIFICATE-----
-----BEGIN PRIVATE KEY-----
-----END PRIVATE KEY-----
EOF
[root@ceph-node-00 ~]# ceph orch apply -i rgw-ingress.yaml
Scheduled ingress.rgw.client update...
NOTE: The ingress service builds from all the certs we add to ssl_cert parameter a single certificate file named HAproxy.pem; for the certificate to work, HAproxy requires that you add the certificates in the following order: cert.pem first, then the chain certificate and finally, the private key
After a minute, we can see our HAproxy and keepalived services running on ceph-node-[02/03]
[root@ceph-node-00 ~]# ceph orch ps | grep -i client
haproxy.rgw.client.ceph-node-02.icdlxn ceph-node-02.cephlab.com *:443,1967 running (3d) 9m ago 3d 8904k - 2.4.22-f8e3218 0d25561e922f 9e3bc0e21b4b
haproxy.rgw.client.ceph-node-03.rupwfe ceph-node-03.cephlab.com *:443,1967 running (3d) 9m ago 3d 9042k - 2.4.22-f8e3218 0d25561e922f 63cf75019c35
keepalived.rgw.client.ceph-node-02.wvtzsr ceph-node-02.cephlab.com running (3d) 9m ago 3d 1774k - 2.2.8 6926947c161f 031802fc4bcd
keepalived.rgw.client.ceph-node-03.rxqqio ceph-node-03.cephlab.com running (3d) 9m ago 3d 1778k - 2.2.8 6926947c161f 3d7539b1ab0f
You can check the configuration of HAproxy from inside the container; you can see it’s using static round-robin load balancing between both our public-facing RGWs configured as the backend. The frontend listens on port 443 with our certificate in the path `/var/lib/haproxy/haproxy.pem`:
[root@ceph-node-02 ~]# podman exec -it ceph-haproxy-rgw-client-ceph-node-02-jpnuri cat /var/lib/haproxy/haproxy.cfg | grep -A 15 "frontend frontend"
frontend frontend
bind *:443 ssl crt /var/lib/haproxy/haproxy.pem
default_backend backend
backend backend
option forwardfor
balance static-rr
option httpchk HEAD / HTTP/1.0
server rgw.client-traffic.ceph-node-02.yntfqb 192.168.122.94:8000 check weight 100
server rgw.client-traffic.ceph-node-03.enzkpy 192.168.122.180:8000 check weight 100
For this example, we have configured basic DNS round robin using the load balancer Coredns plugin; we are resolving s3.zone1.cephlab.com among the configured ingress VIPs. As you can see with the following ping example, each request to s3.zone1.cephlab.com gets resolved to a different Ingress VIP.
[root@ceph-node-00 ~]# ping -c 1 s3.zone1.cephlab.com
PING s3.cephlab.com (192.168.122.150) 56(84) bytes of data.
[root@ceph-node-00 ~]# ping -c 1 s3.zone1.cephlab.com
PING s3.cephlab.com (192.168.122.151) 56(84) bytes of data.
You can now point the s3 client to the s3.zone1.cephlab.com to get access to the RGW S3 API endpoint.
[root@ceph-node-00 ~]# aws --endpoint https://s3.zone1.cephlab.com:443 s3 ls
2024-01-04 13:44:00 firstbucket
At this point, you have High availability and Load balancing configured for zone 1, you could lose one server running the RGW service, and the client requests will get redirected to the remaining RGW service.
We would need to do the same steps for the second Ceph cluster that is supporting zone2, so we will end up with a load-balanced endpoint per zone:
-
s3.zone1.cephlab.com
-
s3.zone2.cephlab.com
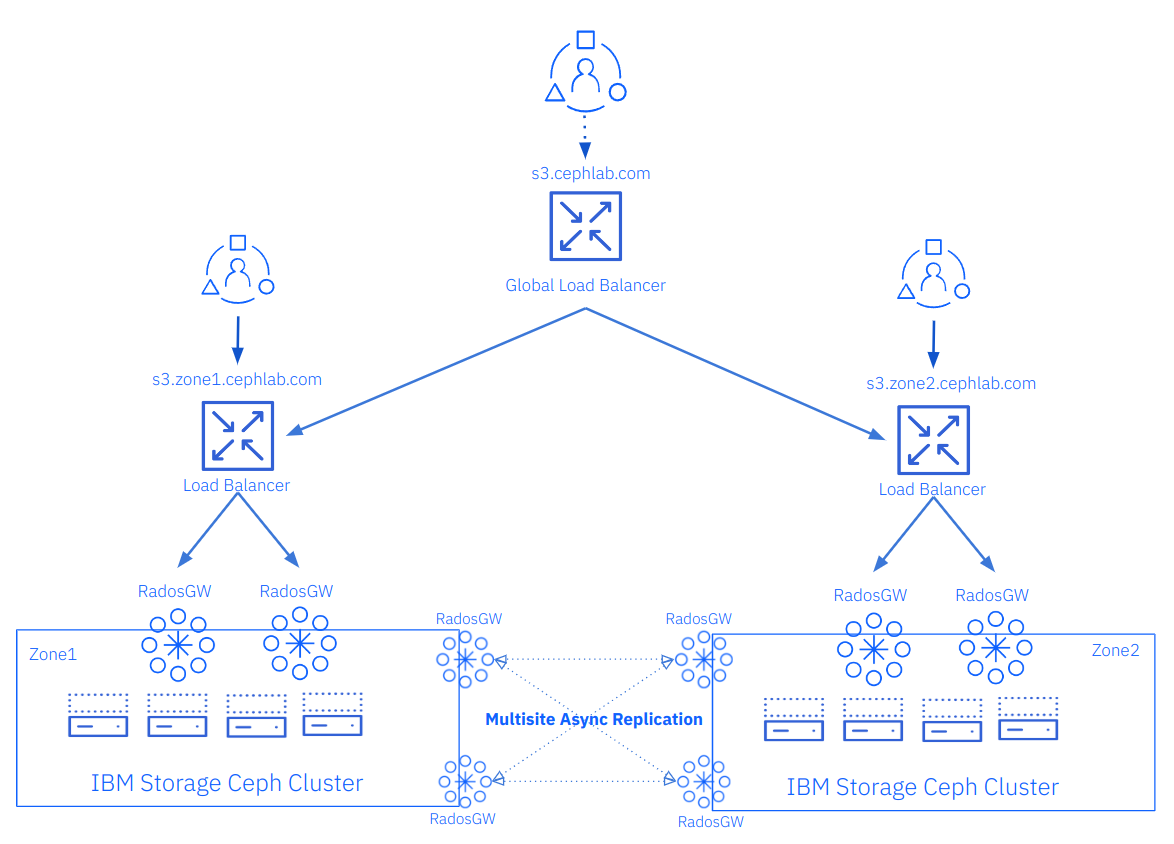
As a final step, we could include a global load balancer; this is not part of the IBM Storage Ceph solution and should be provided by a third party; there are many DNS global load balancers available that can give different load balancing policies.
As we are using SSL/TLS in our lab per-site load balancers, if we were to configure a GLB we will need to implement TLS passthrough or re-encrypt the client connections so the connection will be encrypted from the client to the per-site load balancer. Using a GLB has some significant advantages:
-
Taking advantage of the Active/Active nature of IBM Storage Ceph Object storage replication, you can provide the users with a single S3 endpoint FQDN and then apply policy at the load balancer to send the user request to one site or the other; the load balancer could, for example, redirect the client to the s3 endpoint closest to his location.
-
Even if you need an Active/Passive DR approach, the GLB can enhance your failover; the users will only have a single S3 endpoint FQDN that they need to use; during normal operations, they will always be re-directed to the primary site, in case of site failure the GLB will detect the failure of the primary site, and re-direct the users transparently to the secondary site, enhancing user experience and reducing the failover time.
In the following diagram, we provide an example where we add a GLB with the FQDN of s3.cephlab.com; clients will only need to use s3.cephlab.com, and they will get redirected based on the applied policy at the GLB level to one site or the other:
Should we use a load balancer for the RGW replication endpoints?
In the load balancing ingress service examples we shared, we have configured load balancing for the S3 client endpoints, so the client HTTP requests get distributed among the available RGW services. Still, we haven’t mentioned anything about the RGWs serving the multisite sync requests. From our previous blog, we had configured two RGWs that we have dedicated to multisite sync requests. How are we load-balancing the sync request among the two RGWs if we don’t have an ingress service or external load balancer configured?.
RGW implements a round-robin algorithm at the zone group and zone endpoint level, by which we can enter a comma-separated list of RGW services IPs or hostnames. The RGW service code will load-balance the request among the IPs in the list:
Replication endpoints for our multizg zone group.
[root@ceph-node-00 ~]# radosgw-admin zonegroup get | jq .endpoints
[
"http://ceph-node-04.cephlab.com:8000",
"http://ceph-node-05.cephlab.com:8000"
]
Replication endpoints for our zone1 and zone2 zones.
[root@ceph-node-00 ~]# radosgw-admin zonegroup get | jq .zones[].endpoints
[
"http://ceph-node-00.cephlab.com:8000",
"http://ceph-node-01.cephlab.com:8000"
]
[
"http://ceph-node-04.cephlab.com:8000",
"http://ceph-node-05.cephlab.com:8000"
]
There is an open PR that has not yet merged into IBM Storage Ceph: rgw/multisite: maintain endpoints connectable status and retry the requests to them when appropriate, without it if there are multiple endpoints in a zone, if one of those syncing RGWs is down the sync would stall because we were distributing the operations in round-robin even to the downed RGW. This enhancement will be available on our upcoming IBM Storage Ceph releases.
We can take another approach using a load balancer, for example, a dedicated ingress service or any other HTTP load balancer, to do the load balancing for the multisite sync endpoints, if we take this approach, we would just have a single FQDN in the list of zone group and zone endpoints.
What would be the best solution, a dedicated load balancer or RGW round-robin on the provided list of endpoints?
It depends.., I would say until the previously mentioned PR is merged downstream, external load balancing could be better if the load balancer can offer at least the same throughput as the round-robin of the configured dedicated RGW services, as an example, if our external load balancer is haproxy running on a single VM with a single VIP and limited network throughput, we are better of by using the RGW round-robin replication endpoint list option. Once the PR is merged, I would say that both options are ok; you need to trade the simplicity of just setting up a list of IPs for the endpoints, which is done for us automatically with the RGW manager module, versus the more advanced features that a full-blown load-balancer can offer.
Summary & up next
In Part Four of this series, we discussed everything related to Load-balancing our RGW S3 endpoints, covering different Load-balancing techniques, including the out-of-the-box ceph provided load balancer, the `Ingress service`. In Part Five, we will detail the new `Sync Policy` feature that provides Object Multisite replication with a granular and flexible sync policy scheme.
Links to the rest of the blog series:
IBM Storage Ceph resources
Find out more about IBM Storage Ceph
#Highlights
#Highlights-home