IBM Storage Ceph Object Storage Multisite Replication Series. Part Three
In the previous episode of the series, we went through an example of configuring IBM Storage Ceph Object Storage multisite replication with the help of the RGW manager module; if you missed it, here is the link for Part Two.
Multisite Replication Dedicated RGWs
We have set up two RGWs for each Ceph cluster. By default, the RGW services manage the S3 requests that are facing the public and the replication requests between the sites. The RGW services share their resources and processing time between both tasks. To improve this configuration, we can assign a specific group of RGWs to manage the S3 public requests and another group of RGWs to manage the multisite replication requests between the two Ceph clusters.
Using this approach is not mandatory but will provide as an example some of the following benefits:
-
Because we have a dedicated set of resources for public and multisite replication, we can scale the public-facing or replication RGWs independently depending on where we need higher performance, like increased throughput.
-
Segregated RGWs can avoid blocking sync replication because the RGWs are busy with client-facing tasks or vice-versa.
-
Improved troubleshooting: having dedicated sets of RGWs can improve the troubleshooting experience as we can target the RGWs to investigate depending on our problem. Also, when reading through the debug log of the RGW services, replication messages don’t get in the middle of client logs and vice versa.
-
Because we are using different sets of RGWs, we could use other networks with different security levels, firewall rules, OS security, etc. For example:
When configuring a multisite deployment, it is common practice to dedicate specific RGW services to the client IO and other RGW services to take care of the multisite replication.
By default, all RGWs participate in multisite replication; two steps are needed to remove an RGW from participating in the multisite replication sync.
-
Set the ceph parameter on the RGW client: ceph config set ${KEY_ID} rgw_run_sync_thread false, when false, prevents this object store's gateways from transmitting multisite replication data
-
The previous parameter only tells the RGW not to SEND replication data, but it can keep receiving; also, to avoid receiving, we need to remove the RGWs from the zone group and zone replication endpoints.
Configure dedicated RGW services for Public and Replication requests.
In the previous chapter, we configured two RGWs per Ceph cluster, which are currently serving client S3 requests and replication request traffic. In the following steps, we will configure two additional RGWs per cluster to end up with four RGWs on each cluster. Out of these four RGWs, two will be dedicated to serving public requests, and the other two will be dedicated to serving multisite replication. The diagram below illustrates what we are aiming to achieve.
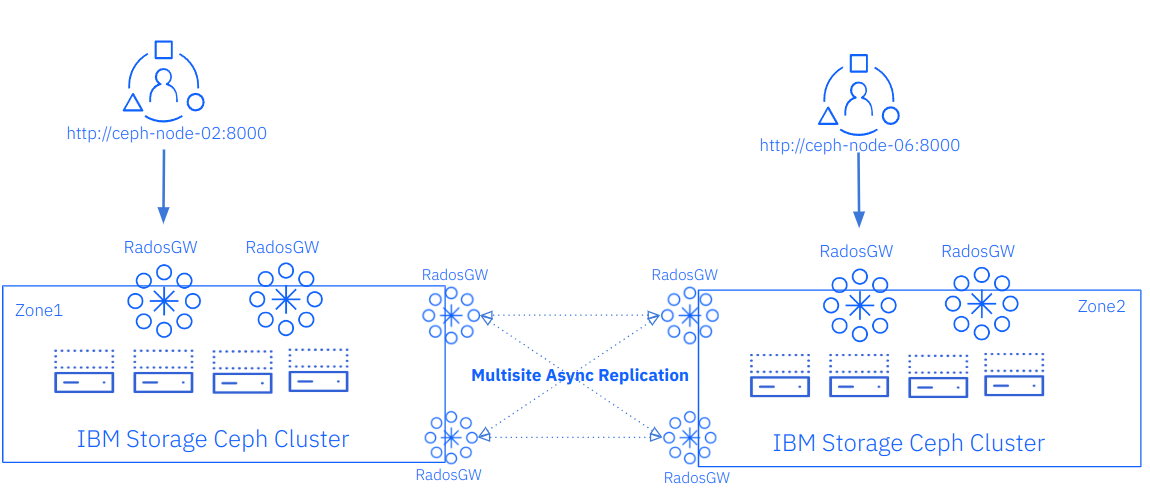
We will keep using labels to control the scheduling and placement of the RGW services; in this case, the label we will use for the public-facing RGWs is called `rgw`.
[root@ceph-node-00 ~]# ceph orch host label add ceph-node-02.cephlab.com rgw
Added label rgw to host ceph-node-02.cephlab.com
[root@ceph-node-00 ~]# ceph orch host label add ceph-node-03.cephlab.com rgw
Added label rgw to host ceph-node-03.cephlab.com
We create an RGW spec file for the public-facing RGWs; in this example, we use the same CIDR network for all RGW services. Still, we could configure different network CIDRs for the different sets of RGWs we deploy if needed. We use the same realm, zone group and zone as the services we already have running, as we want all the RGWs to belong to the same realm namespace.
[root@ceph-node-00 ~]# cat << EOF >> /root/rgw-client.spec
service_type: rgw
service_id: client-traffic
placement:
label: rgw
count_per_host: 1
networks:
- 192.168.122.0/24
spec:
rgw_frontend_port: 8000
rgw_realm: multisite
rgw_zone: zone1
rgw_zonegroup: multizg
EOF
We apply the spec file and check that we now have four new services running, two for multisite replication and the other for client traffic.
[root@ceph-node-00 ~]# ceph orch apply -i spec-rgw.yaml
Scheduled rgw.rgw-client-traffic update…
[root@ceph-node-00 ~]# ceph orch ps | grep rgw
rgw.multisite.zone1.ceph-node-00.mwvvel ceph-node-00.cephlab.com *:8000 running (2h) 6m ago 2h 190M - 18.2.0-131.el9cp 463bf5538482 dda6f58469e9
rgw.multisite.zone1.ceph-node-01.fwqfcc ceph-node-01.cephlab.com *:8000 running (2h) 6m ago 2h 184M - 18.2.0-131.el9cp 463bf5538482 10a45a616c44
rgw.client-traffic.ceph-node-02.ozdapg ceph-node-02.cephlab.com 192.168.122.94:8000 running (84s) 79s ago 84s 81.1M - 18.2.0-131.el9cp 463bf5538482 0bc65ad993b1
rgw.client-traffic.ceph-node-03.udxlvd ceph-node-03.cephlab.com 192.168.122.180:8000 running (82s) 79s ago 82s 18.5M - 18.2.0-131.el9cp 463bf5538482 8fc7d6b06b54
As we mentioned at the start of this section, to disable replication traffic on an RGW, we need to make sure of two things:
- The sync threads are disabled on the RGW.
- Second, the RGWs are not listed as replication endpoints in the zone group/zone configuration.
So the first thing we are going to do is disable the `rgw_run_sync_thread` using the `ceph config` command; we are going to use the service name.`client.rgw.client-traffic`, to apply the change on both of our public RGWs simultaneously. We first check the current configuration of the `rgw_run_sync_thread` and confirm that it is set by default to true.
[root@ceph-node-00 ~]# ceph config get client.rgw.client-traffic rgw_run_sync_thread
true
We will now change the parameters to false so that the sync threads will be disabled for this set of RGWs.
[root@ceph-node-00 ~]# ceph config set client.rgw.client-traffic rgw_run_sync_thread false
[root@ceph-node-00 ~]# ceph config get client.rgw.client-traffic rgw_run_sync_thread
false
The second step is ensuring the new RGWs we deployed are not listed as replication endpoints in the zone group configuration. We shouldn’t see ceph-node-02 or ceph-node-03 listed as endpoints under zone1:
[root@ceph-node-00 ~]# radosgw-admin zonegroup get | jq '.zones[]|.name,.endpoints'
"zone1"
[
"http://ceph-node-00.cephlab.com:8000",
"http://ceph-node-01.cephlab.com:8000"
]
"zone2"
[
"http://ceph-node-04.cephlab.com:8000",
"http://ceph-node-05.cephlab.com:8000"
]
After confirming this, we have finished this part of the configuration and have running in the cluster dedicated services for each type of request: Client Requests and Replication Requests.
You would need to repeat the same steps to apply the same configuration to our second cluster zone2
New Performance Improvements in 7.0! Replication Sync Fairness
IBM Storage Ceph 7.0 has introduced a new improvement in Object Storage Multisite Replication known as "Replication Sync Fairness". This improvement addresses the issue faced in earlier versions of Ceph where the replication work was not distributed optimally. In those versions, one RGW would take the lock for the replication operations, and the other RGW services would find it difficult to obtain the lock. This resulted in the horizontal scalability of the multisite replication not scaling linearly when adding new RGW services. To improve the distribution of replication work, significant improvements were made in IBM Storage Ceph 6.1. However, with Sync Fairness replication in 7.0, the replication data and metadata are evenly distributed among all RGW services, enabling them to collaborate more efficiently in replication tasks.
Thanks to the IBM Storage DFG team that ran Scale testing to highlight and verify the improvements introduced thanks to the sync fairness feature. During the testing, the DGF team compared IBM Storage Ceph version 7.0 with versions 6.1 and 5.3 while ingesting objects with multisite replication configured.
The results below provided by DFG compare the degree of participation performed by each syncing RGW in each test case. The graphs plot the avgcount (number of objects and bytes fetched by data sync) polled every 15 minutes. An optimal result is one where all syncing RGWs evenly share the load. See Performance counters for multi-site Ceph Object Gateway data sync for further info on available sync counters.
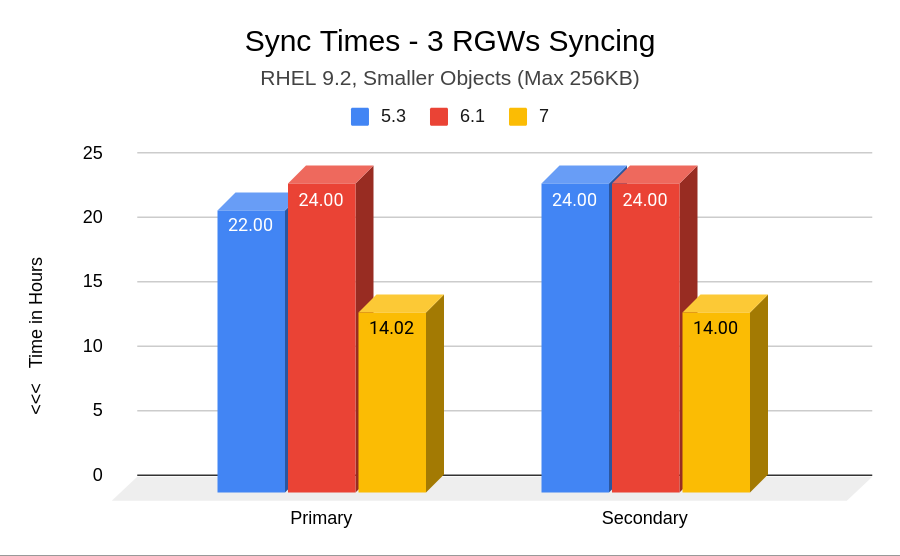
In this example, note how one of the 5.3 RGWs(Blue Line) processed objects in the 13M range (18M for secondary sync) while the other two 5.3 RGWs were doing 5 million and 1,5 million, resulting in longer sync times(More than 24 hours). The RHCS 7 RGWs, however, all stay within close range of each other; all RGWs process 5M to 7M objects, and syncing is achieved sooner, well under the 19-hour range.
The closer the lines of the same colour are in the graph, the better the sync participation is; as you can see, for Ceph 7, the green lines are very close to each other, meaning that the replication workload is being evenly distributed between the three sync RGWs configured for the test.

In the following graph, we show how much time it took for each version to sync the full workload(small objects) to the other zone; the less time, the better. We can see that IBM Storage Ceph 7.0 has substantially improved sync times.
Summary & up next
To summarize, in Part Three of this series, we discussed configuring dedicated RGW services for public and replication requests. Additionally, we have explored the performance enhancements the sync fairness feature offers. We will delve into Load Balancing our client-facing RGW endpoints in
Part Four.
Links to the rest of the blog series:
IBM Storage Ceph resources
Find out more about IBM Storage Ceph
#Featured-area-1
#Featured-area-1-home