Dear Ujwala
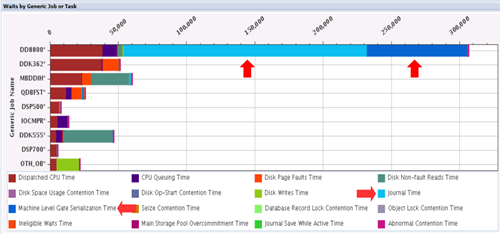
Is Azure running on Intel/Windows server? If so, in such a multi-tier workload environment, you need first to check HW resource utilization and wait time accounting on both intel/Windows and IBM i. For the latter, use Performance Data Investigator (PDI) tool and focus on the charts named Wait Overview and Wait by Generic Job or Task and Wait by Subsystem to check if there is any prominent wait time during the time frame the problem happens and, if so, address that wait issue. (Post the charts here if you can.) You need to also analyse this performance data on Windows server as well but I have no suggestion on how to do it.
Here are also additional performance factors I learned from my past experience for such similar cases to be important in alleviating the seriousness of the issue you are facing. The following TCP/IP factors need to be adjusted and impolemented :
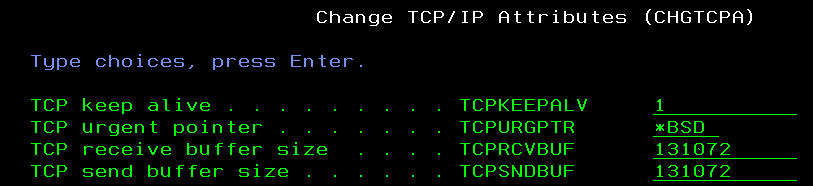
1) On both Intel/Windows and IBM i servers, set TCP/IP Send and Receive Buffer size (TCPRCVBUF and TCPSNDBUF) at around 300 KB with CHGTCPA command. IBM i default size of 64 KB is too small for high workload period. On Windows side, you need to find someone who knows how to change these parameters. Keep in mind that this change takes effect ONLY FOR new TCPIP connections that come up AFTER the change. If all you connections are in persistent connection pool, you need to restart the entire connection pool for the new buffer size to take effect.
2. I assume Azure on Windows server always initiates connection to IBM i. If this is the case, you should tell Windows expert to implement a "persistent connection pool" from Azure to IBM i and also set TCPIP Keep Alive timer (say, at 10 minutes) in Windows server. (This part is done on Intel server only. Nothing to do on IBM i side.) Not using persistent connection pool incurs excessive TCPIP connection workload due to repetitive connect+disconnect for all transaction between Windows and IBM i servers. Persistent connection pool can dramatically reduce this excessive communication overhead at peak workload when there are peak numbers of connection and you need someone with experience to help you implement the connection pool.
Please read this article of mine that discusses this same recommendation: IBM i Experience Sharing, Case 3 – When Performance Issues Come From Without (read the 2nd case on the latter half of the article - beginning at the sentence "Here is one more case study of external source of performance problem in a complex IT universe.") at https://www.itjungle.com/author/satid-singkorapoom/
Let me know when you have further question.
------------------------------
Satid S
------------------------------
Original Message:
Sent: Wed March 27, 2024 10:04 PM
From: Ujwala Kavathekar
Subject: Performance degradation on system while webservice calls
Hello,
We are calling SOAP Webservice deployed on the server from Azure using azure function. When there are too many requests received from azure to system, we are facing performance degradation and error received is 'Client connection was closed unexpectedly'. Then all other services which are deployed on that Application server in WebSphere also impacted and stopped responding.
Can you please let me know how to handle such thing in IBM i. Is there any way to handle large number of requests simultaneously.
Thank you!
------------------------------
Ujwala Kavathekar
------------------------------