Push IBM i beyond the limits – table partitioning
One of the less knew (and consequently less used) feature of DB2 for i is the possibility of table partitioning. In many other databases this is a need as a partitioned table allow data process in parallel which improve the performance. This is not the case for IBM i. It is able to use parallel processing, through the optional Db2 Symmetrical Multiprocessing (SMP) feature, in non-partitioned table. Nevertheless, there are some areas where a partitioned table can be useful:
- Overcoming database limits (size/rows number) – up to 256 partitions by table, so 256 x size
- Mass operations over data (reorganize, save/restore)
- With good planification even query performance can be improved
- Archive old data
Table partitioned is enabled through the optional feature Db2 for i Multisystem. The good news is that, starting from June 2022, this feature is free of charge. You have to go through your Business Partner an obtain the entitlement.
From the IBM i perspective each partition is viewed as a physical file member. For SQL operations this is totally transparent but for native database operation (like RPG) we have to precise which member will be used (through OVRDBF command).
The most important aspect of table partitioning is the planification phase – we have to carefully choose the partitioning key as it will determine how well our application will run. Some examples of partitioning key:
- Year – normally most queries are run over the recent data. Also, this will allow to archive data (another feature of Db2 for i Multisystem).
- State/province - many users just want to know information from their geographic area.
The configuration process is not complicated and the migration process, from non-partitioned to partitioned, is not difficult – see the reference documentation.
Let’s see a configuration example.
The table structure that I use is:
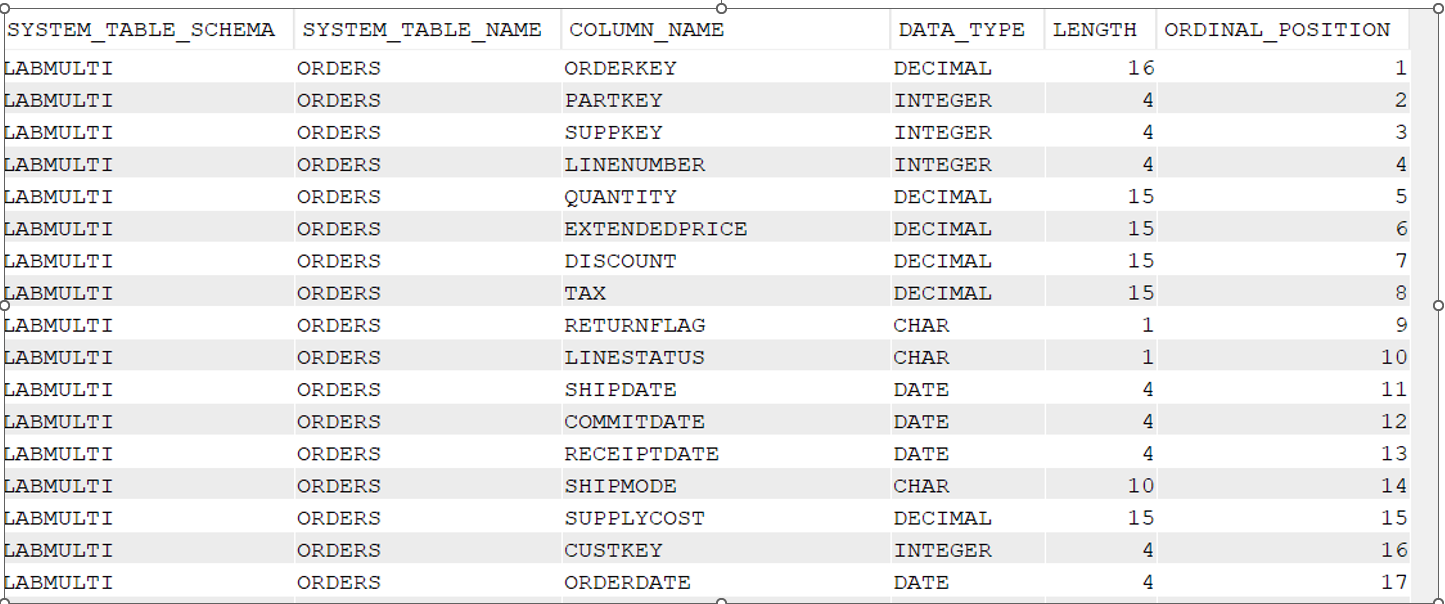
And the index that I have over the table are:

Yes, I have a derived index over the column ORDERDATE.
The idea is to split the data by the year of the order because:
- Most of the queries are run over the current year data
- The need to archive the orders older that x years.
ALTER TABLE ORDERS
ADD PARTITION BY RANGE(ORDERDATE)
(PARTITION ORDERS2019 STARTING('2019-01-01') ENDING('2019-12-31') INCLUSIVE,
PARTITION ORDERS2020 STARTING('2020-01-01') ENDING('2020-12-31') INCLUSIVE ,
PARTITION ORDERS2021 STARTING('2021-01-01') ENDING('2021-12-31') INCLUSIVE) ;
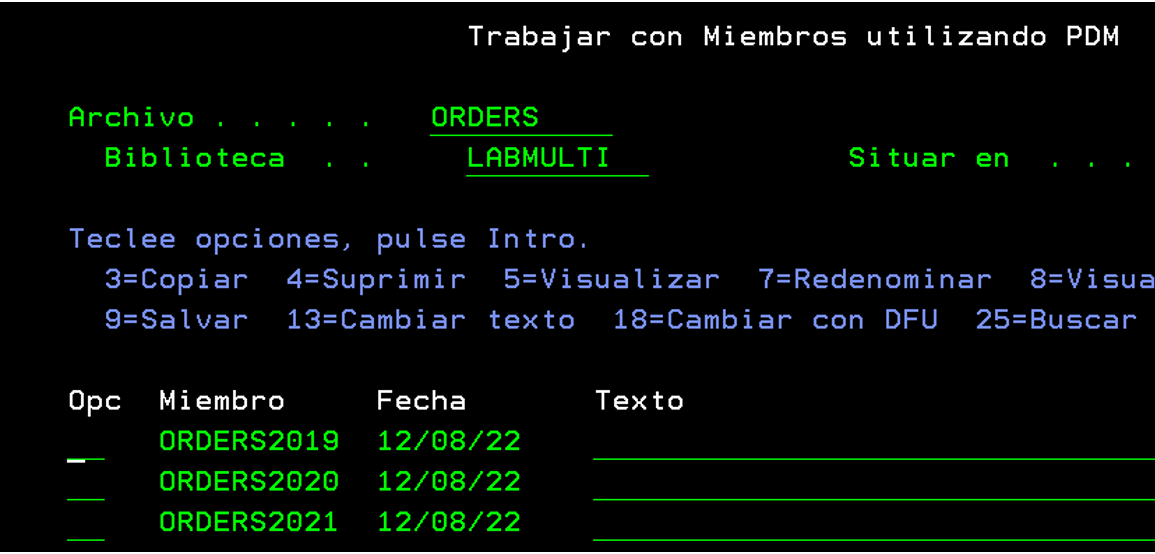
If we check through green screen, we see that our file has now 3 members:
The indexes also have changed:
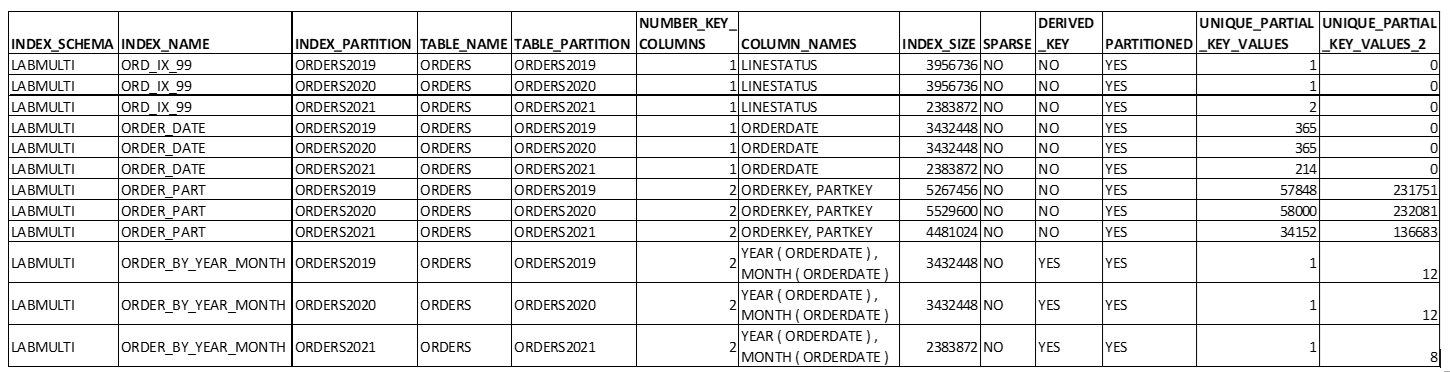
Pay attention and analize the differences beetwen pre and post partitioning.
Let’s now check the queries behaviors
SELECT * FROM ORDERS WHERE YEAR(ORDERDATE) = '2019' AND MONTH(ORDERDATE)='01' ;
In Visual Explain we can see thar our query is using all the partitioned index, not just the one corresponding to year 2019:

To overcome this problem, we must use alias:
CREATE ALIAS ORDERS2019 FOR ORDERS (ORDERS2019);
And run the query over the alias:
SELECT * FROM ORDERS WHERE MONTH(ORDERDATE)='01';
I don’t need to specify the year as it is limited by the partition.

So, in order to achieve some performance benefit from partitioned indexes, we need to use alias.
If we need to add a new partition we can do it through ACS:
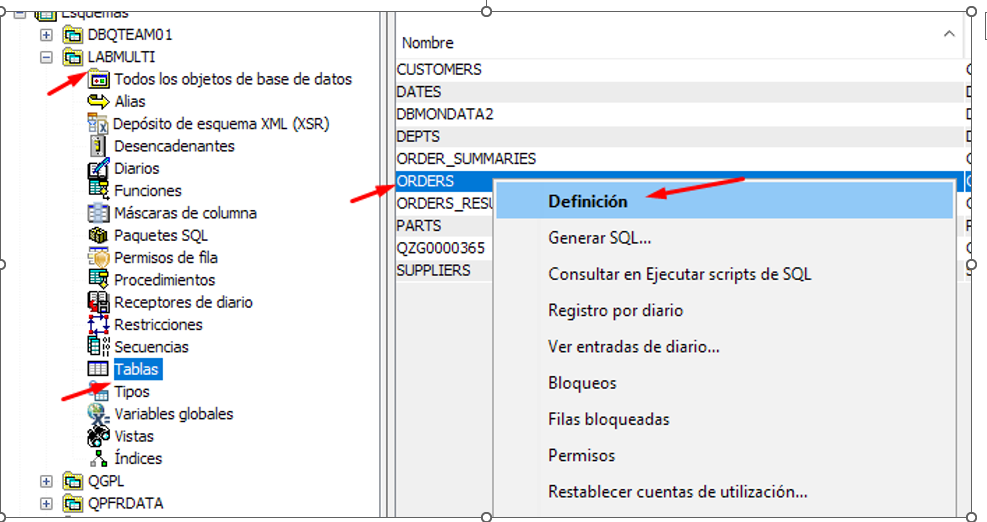
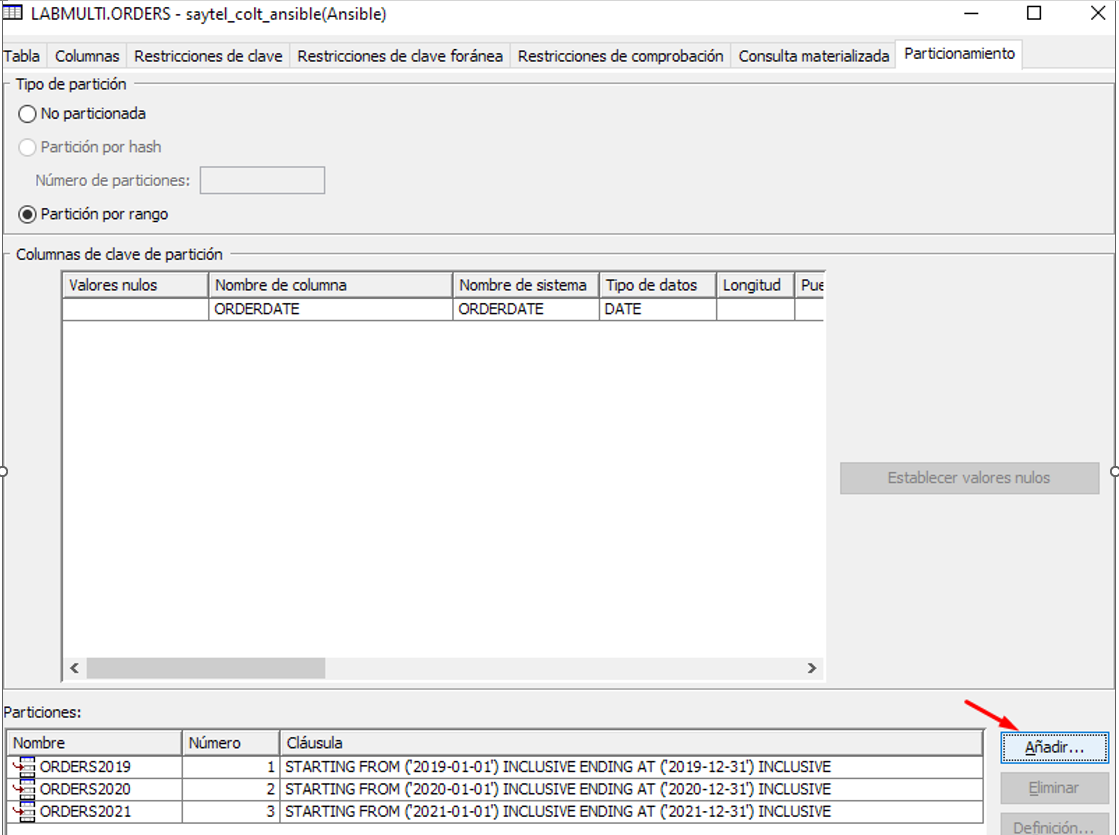
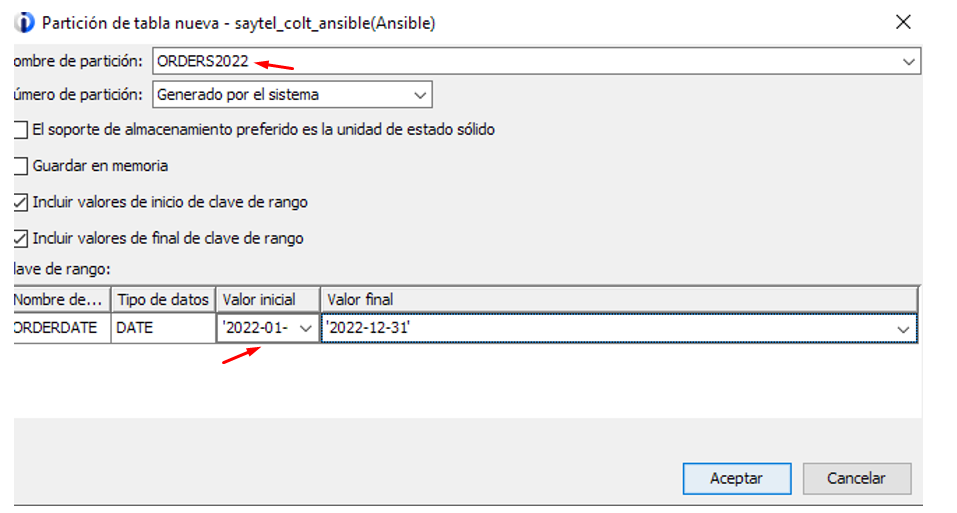
Now that we have a new partition is time to archive the oldest one – this feature was introduced in V7R3 and it is a great help to old data management:
ALTER TABLE ORDERS DETACH PARTITION ORDERS2019 INTO ARCORD2019;
This generate a new table - ARCORD2019 – with one partition:
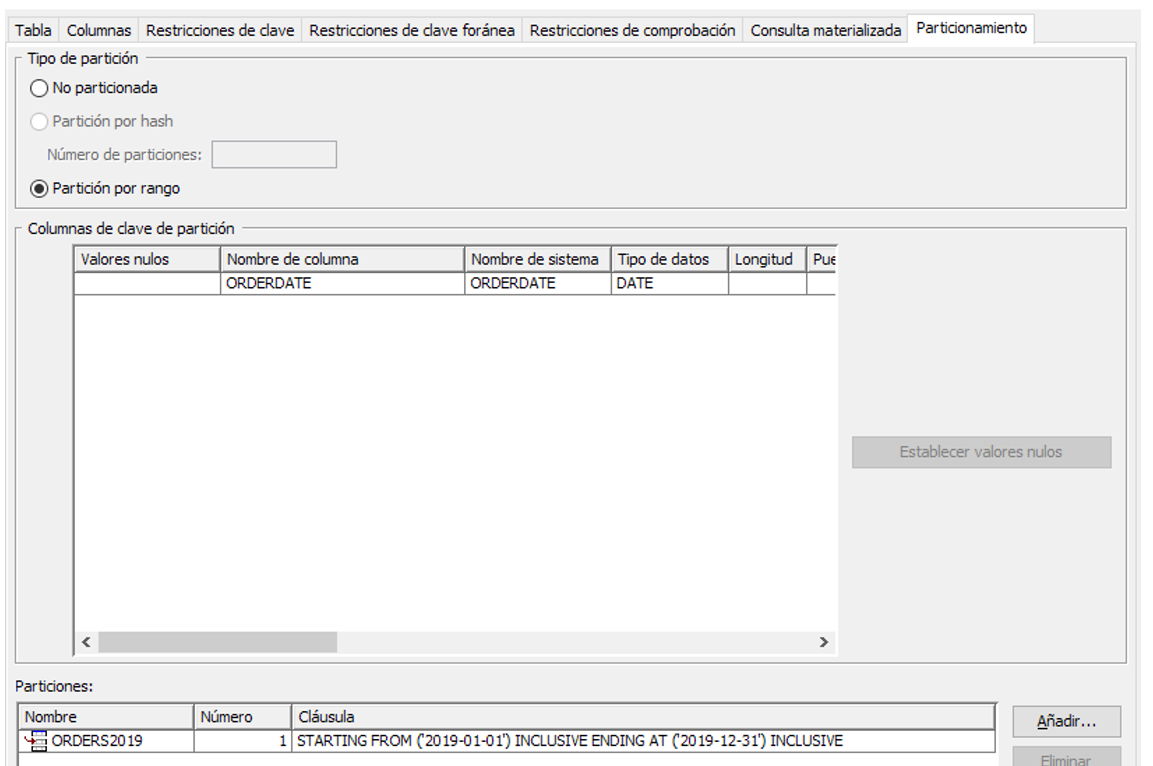
If we need to bring back the detached partition, we just need to run the opposite sentence:
ALTER TABLE ORDERS ATTACH PARTITION ORDERS2019 FROM ARCORD2019;
Conclusion
Table partitioning is a great feature that can help to solve specific problem and it’s free.
References
IBM Db2 for i table partitioning strategies https://www.ibm.com/support/pages/system/files/inline-files/Table%20Partitioning%20Strategies.pdf
IBM i doc - https://www.ibm.com/docs/en/i/7.5?topic=multisystem-partitioned-tables Partitioned tables - IBM Documentation