This article is part of a series. For the whole series list see here
In the initial "moving MQ integrations to containers" blog post, a single MQ queue was used in place of an actual MQ-based back-end system used by an HTTP Input/Reply flow, which allowed for a clean example of moving from local MQ connections to remote client connections. In this blog post, we will look at what happens when an actual back-end is used with multiple client containers and explore solutions to the key challenge: how do we ensure that reply messages return to the correct server when all the containers have identical starting configurations? [TLDR: Use MQ correlation IDs; see Correlation ID solution below]
Issues with multiple containers and reply messages
Consider the following scenario, which involves an HTTP-based flow that calls an MQ back-end service using one queue for requests and another for replies (some nodes not shown):

The HTTP input message is sent to the MQ service by the top branch of the flow using the input queue, and the other branch of the flow receives the replies and sends them back to the HTTP client.
The picture is complicated slightly by HTTPReply nodes requiring a “reply identifier” in order to know which HTTP client should receive a reply (there could be many clients connected simultaneously), with the identifier being provided by the HTTPInput node. The reply identifier can be saved in the flow (using ESQL shared variables or Java static variables) in the outbound branch and restored in the reply branch based on MQ-assigned message IDs, or else sent to the MQ service as a message or correlation ID to be passed back to the reply branch, or possibly sent as part of the message body; various solutions will work in this case.
This behaves well with only one copy of the flow running, as all replies go through one server and back to the calling client. If the ACE container is scaled up, then there will be a second copy of the flow running with an identical configuration, and it might inadvertently pick up a message intended for the original server. At that point, it will attempt to reply, but discover that that the TCPIP socket is connected to the original server:
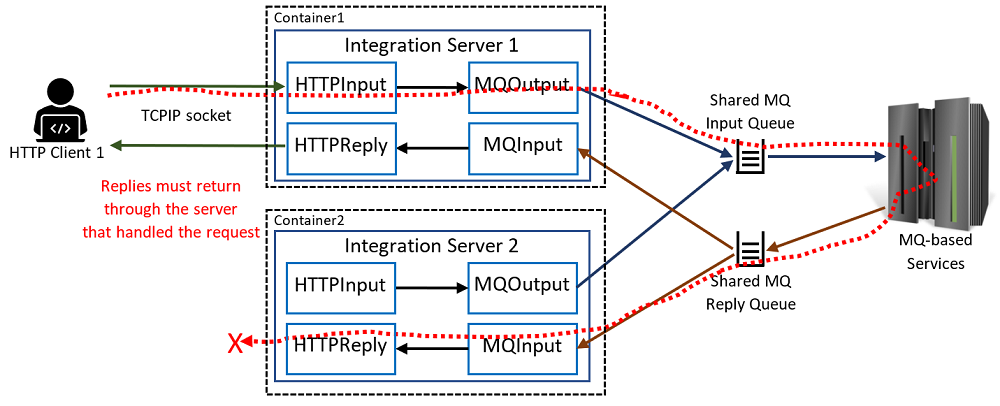
This situation can arise even with only a single copy of the container deployed: a Kubernetes rolling update will create the new container before stopping the old one, leading to the situation shown above due to both containers running at the same time. While Kubernetes does have a “Recreate” deploy strategy that eliminates the overlap, it would clearly be better to solve the problem itself rather than restricting solutions to only one container.
Containers present extra challenges when migrating from on-prem integration nodes: the scaling and restarts in the container world are often automated and not directly performed by administrators, and all of the replica containers have the same flows with the same nodes and options. There is also no “per-broker listener” in the container case, as each server has a separate listener.
Solutions
The underlying problem comes down to MQInput nodes picking up messages intended for other servers, and the solutions come in two general categories:
1. Use
correlation IDs for reply messages so that the MQInput nodes only get the messages for their server

Each server has a specific correlation ID, and the messages sent from the MQOutput node specific that correlation ID, and the back-end service copies the correlation ID into the response message. The MQInput node only listens for messages with that ID, and so no messages for other servers will be picked up. This solution requires some way of preserving the HTTP reply identifier, which can be achieved in various ways.
2. Create a separate queue for each server and configure the MQInput nodes for each container to use a separate queue
In this case, there is no danger of messages going back to the wrong server, as each server has a distinct queue for replies. These queues need to be created and the flows configured for this to work with ACE.
The second category requires custom scripting in the current ACE v12 releases and so will not be covered in this blog post, but ACE v12 does have built-in support for the first category, with several options for implementing solutions that will allow for scaling and redeploy without messages going to the wrong server. Variations on the first category include the “message ID to correlation ID” pattern and synchronous flows, but the idea is the same.
While containers show this problem (and therefore the solutions) nicely, the examples described here can be run on a local server also, and do not need to be run in containers. Scaling integration solutions to use multiple servers is much easier with containers, however, and so the examples focus on those scenarios.
Example solution scenario
Overview
Building on the previous blog post, the examples we shall be using are at https://github.com/trevor-dolby-at-ibm-com/ace-http-mq-request-reply and follow this pattern:
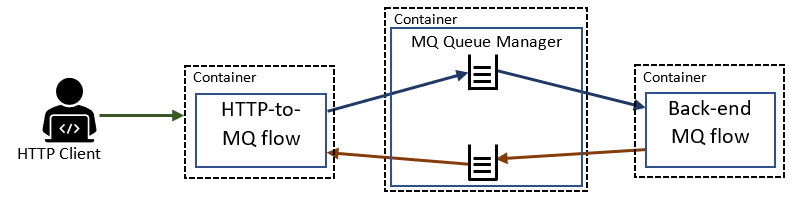
The previous blog post showed how to create the MQ container and the ACE container for the simple flow used in that example, and these examples follow the same approach but with different queues and ACE applications.
Two additional queues are needed, with backend-queues.mqsc showing the definitions:
DEFINE QLOCAL(BACKEND.SHARED.INPUT) REPLACE
DEFINE QLOCAL(BACKEND.SHARED.REPLY) REPLACE
and the MQSC ConfigMap shown in a previous MQ blog post can be adjusted to include these definitions.
The same back-end is used for all of the client flows, so it should be deployed once using the “MQBackend” application; a pre-built BAR file is available that can be used in place of the BAR file used in the previous blog post , and the IS-github-bar-MQBackend.yaml file can be used to deploy the backend service. See the README.md for details of how the flow works.
Correlation ID solution
The CorrelIdClient example shows one way to use correlation IDs:
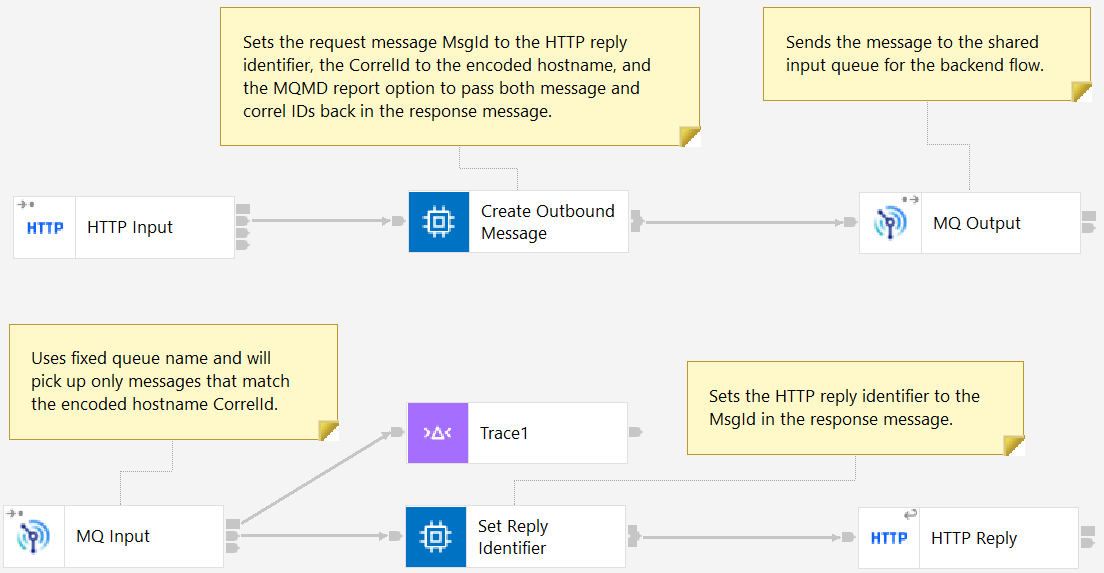
This client flow relies on
- The back-end flow honoring the MQMD Report settings.
- A unique per-server correlation ID being available as a user variable.
- The HTTP RequestIdentifier being usable as an MQ message ID.
The MQBackend application uses an MQReply node, which satisfies requirement 1, and requirement 3 is satisfied by the design of the ACE product itself: the request identifier is 24 bytes (which is the size of MQ’s MsgId and CorrelId) and are unique for a particular server.
Requirement 2 is met in this case by setting a user variable to the SHA-1 sum of the HOSTNAME environment variable. SHA-1 is not being used in this case for cryptographic purposes but rather to ensure that the user variable is a valid hex number (with only letters from A-F and numbers) that is 24 bytes or less (20 in this case). The sha1sum command is run from a server startup script (supported from ACE 12.0.5) using the following server.conf.yaml setting (note that the spaces are very important due to it being YAML):
StartupScripts:
EncodedHostScript:
command: 'export ENCODED_VAR=`echo $HOSTNAME | sha1sum | tr -d "-" | tr -d " "` && echo UserVariables: && /bin/echo -e " script-encoded-hostname: \\x27$ENCODED_VAR\\x27"'
readVariablesFromOutput: true
This server.conf.yaml setting will cause the server to run the script and output the results:
2022-11-10 13:04:57.226548: BIP9560I: Script 'EncodedHostScript' is about to run using command 'export ENCODED_VAR=`echo $HOSTNAME | sha1sum | tr -d "-" | tr -d " "` && echo UserVariables: && /bin/echo -e " script-encoded-hostname: \\x27$ENCODED_VAR\\x27"'.
UserVariables:
script-encoded-hostname: 'adc83b19e793491b1c6ea0fd8b46cd9f32e592fc'
2022-11-10 13:04:57.229552: BIP9567I: Setting user variable 'script-encoded-hostname'.
2022-11-10 13:04:57.229588: BIP9565I: Script 'EncodedHostScript' has run successfully.
Once the user variable is set, it can be used for the MQInput node (to ensure only matching messages are received) and the MQOutput node (to provide the correct ID for the outgoing message). The MQInput node can accept user variable references in the correlation ID field (ignore the red X):
The MQOutput node will send the contents of the MQMD parser from the flow, and so this is set in the “Create Outbound Message” Compute node using ESQL, converting the string in the user variable into a binary CorrelId:
-- Set the CorrelId of the outgoing message to match the MQInput node.
DECLARE encHost BLOB CAST("script-encoded-hostname" AS BLOB);
SET OutputRoot.MQMD.CorrelId = OVERLAY(X'000000000000000000000000000000000000000000000000' PLACING encHost FROM 1);
SET OutputRoot.Properties.ReplyIdentifier = OutputRoot.MQMD.CorrelId;
The ReplyIdentifier field in the Properties parser overwrites the MQMD CorrelId in some cases, so both are set to ensure the ID is picked up. The “script-encoded-hostname” reference is the name of the user variable, declared as EXTERNAL in the ESQL to cause the server to read the user variable when the ESQL is loaded:
DECLARE "script-encoded-hostname" EXTERNAL CHARACTER;
Other sections of the ESQL set the Report options, the HTTP request identifier, and the ReplyToQ:
-- Store the HTTP reply identifier in the MsgId of the outgoing message.
-- This works because HTTP reply identifiers are the same size as an MQ
-- correlation/message ID (by design).
SET OutputRoot.MQMD.MsgId = InputLocalEnvironment.Destination.HTTP.RequestIdentifier;
-- Tell the backend flow to send us the MsgId and CorrelId we send it.
SET OutputRoot.MQMD.Report = MQRO_PASS_CORREL_ID + MQRO_PASS_MSG_ID;
-- Tell the backend flow to use the queue for our MQInput node.
SET OutputRoot.MQMD.ReplyToQ = 'BACKEND.SHARED.REPLY';
Deploying the flow requires a configuration for the server.conf.yaml mentioned above, and this must include the remote default queue manager setting as well as the hostname encoding script due to only one server.conf.yaml configuration being allowed by the operator. This combined file is shown at https://github.com/trevor-dolby-at-ibm-com/ace-http-mq-request-reply/blob/main/CorrelIdClient/server.conf.yaml-with-remote-default and there is an encoded form ready for CP4i deployment at https://github.com/trevor-dolby-at-ibm-com/ace-http-mq-request-reply/blob/main/CorrelIdClient/script-and-remote-mq.yaml.
Once the configurations are in place, the flow itself can be deployed using the IS-github-bar-CorrelIdClient.yaml file to the desired namespace (“cp4i” in this case): kubectl apply -n cp4i -f IS-github-bar-CorrelIdClient.yaml (or using a direct HTTP URL to the git repo). This will create two replicas, and once the servers are running then curl can be used to verify the flows operating successfully, and the CorrelId field should alternate between requests to show both servers sending and receiving messages correctly:
$ curl http://http-mq-correlidclient-http-cp4i.apps.cp4i-domain/CorrelIdClient
{"originalMessage":{"MsgId":"X'455648540000000000000000c6700e78d900000000000000'","CorrelId":"X'20fa1e68cb59a328f559cc306aa52df3e58ffd3200000000'","ReplyToQ":"BACKEND.SHARED.REPLY ","jsonData":{"Data":{"test":"CorrelIdClient message"}}},"backendFlow":{"application":"MQBackend"}}
$ curl http://http-mq-correlidclient-http-cp4i.apps.cp4i-domain/CorrelIdClient
{"originalMessage":{"MsgId":"X'455648540000000000000000be900e78d900000000000000'","CorrelId":"X'd7cb7b30c4775d27aabbb4997020ebafd14f775700000000'","ReplyToQ":"BACKEND.SHARED.REPLY ","jsonData":{"Data":{"test":"CorrelIdClient message"}}},"backendFlow":{"application":"MQBackend"}}
$ curl http://http-mq-correlidclient-http-cp4i.apps.cp4i-domain/CorrelIdClient
{"originalMessage":{"MsgId":"X'455648540000000000000000c6700e78d900000000000000'","CorrelId":"X'20fa1e68cb59a328f559cc306aa52df3e58ffd3200000000'","ReplyToQ":"BACKEND.SHARED.REPLY ","jsonData":{"Data":{"test":"CorrelIdClient message"}}},"backendFlow":{"application":"MQBackend"}}
Variations
Other possible solutions exist:
- CorrelIdClientUsingBody shows a solution storing the HTTP reply identifier in the body of the message rather than using the MsgId field of the MQMD. This avoids a situation where the same MsgId is used twice (once for request and the second time for the reply), but requires the back-end service to copy the identifier from the request to the reply message, and not all real-life services will do this. Similar flows can be built using RFH2 headers to contain the HTTP reply identifier, with the same requirement that the back-end service copy the RFH2 information. This flow uses a separate CorrelId padding value of “11111111” instead of “00000000” used by CorrelIdClient to ensure that the flows do not collide when using the same reply queue. Like the CorrelIdClient, this solution relies on startup scripts supported in ACE 12.0.5 and later.
- Sha1HostnameClient is a variant of CorrelIdClient that uses a predefined user variable called “sha1sum-hostname” provided by the server in ACE 12.0.6 and later fixpacks; this eliminates the need for startup scripts to set user variables.
- SyncClient shows a different approach, using a single flow that waits for the reply message. No user variables are needed, and the back-end service needs only to copy the request MsgId to the CorrelId in the reply (which is the default Report option), but the client flow will block in the MQGet until the reply message is received. This is potentially a very resource-intensive way to implement request-reply messaging, as every message will block a thread for as long as it takes the back-end to reply, and each thread will consume storage while running.
Summary
Existing integration solutions using MQ request/reply patterns may work unchanged in the scalable container world if they implement mechanisms similar to those described above, but many solutions will need to be modified to ensure correct operation. This is especially true for integrations that rely on the per-broker listener to handle the matching of replies to clients, but solutions are possible as is shown in the example above.
Further conversation in the comments or elsewhere always welcome!
Acknowledgments: Thanks to Amar Shah for creating the original ACE-with-MQ blog post on which this is based, and for editorial help.