This blog is part of a series. For the whole series list see here
IBM App Connect Enterprise was originally created at a time when much integration was performed using messaging, and specifically IBM MQ. Indeed, despite the popularity of more recent protocols such as RESTful APIs, there are still many integration challenges that are better suited to messaging. IBM App Connect Enterprise today is now used to mediate a vast array of protocols, but nearly all existing customers will have some MQ based integration in their landscape.
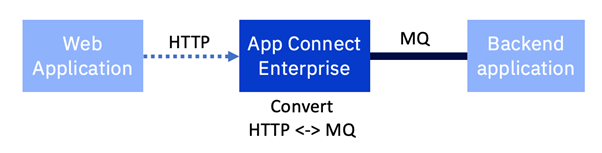
This article looks at the very common scenario of an existing back end system that has only an MQ interface, but needs to be exposed as an HTTP based API. IBM App Connect Enterprise performs the protocol transformation from HTTP to MQ and back again.
The move to remote MQ connections
Existing interfaces based on older versions of IBM App Connect Enterprise will most likely have a local IBM MQ server running on the same machine as IBM App Connect Enterprise. This was a mandatory part of the installation up to and including v9 (at that time called IBM Integration Bus), and integrations would primarily use local bindings to connect to the local MQ server, which would then be distributed onto the broader MQ network.

The starting point for this example will be an integration built using local bindings to a co-installed MQ server. We will explore what changes we should consider to bring that integration into containers, and for this example, on OpenShift.
Since v9 the local MQ server became optional. Networks had become more consistent and reliable and so the use of “remote bindings” to MQ became more prevalent. Today, IBM App Connect Enterprise (v12 at the time of writing) no longer mandates a local MQ server for any of the nodes on the toolkit palette. For a more detailed information on this topic, take a look at the following article.
https://community.ibm.com/community/user/integration/viewdocument/when-does-ace-need-a-local-mq-serve

As we will see shortly, many integrations can be switched from local to remote bindings with minor configuration changes.
There are several advantages in switching to remote MQ communication.
- Simplicity: The architecture is simpler as it has fewer moving parts. The installation and operation of IBM App Connect Enterprise no longer requires any knowledge of IBM MQ. Only the MQ Client software is required.
- Stateless: IBM App Connect Enterprise becomes “stateless”. It no longer requires a persistent storage. This significantly simplifies architecting for high availability and disaster recovery. Conveniently, it also makes it much better suited to cloud native deployment in containers. For example, it makes it possible for a container platform like Kubernetes to add or replace instances of IBM App Connect Enterprise wherever it likes for scalability or availability without having to worry about whether they will have access to the same storage.
- Single purpose per container: Containers should aim to perform a single activity. This creates clarity both architecturally and operationally. It means the platform (Kubernetes in our case) can look after them based on role specific policies around availability, replication, security, persistence and more. IBM App Connect Enterprise is a stateless integration engine. IBM MQ is a persistent messaging layer. They have very different needs, and should be looked after independently by the platform.
For the back end too there are the same benefits of simplification and statelessness if we were to change that to use remote MQ connections. Indeed many applications have already moved to this pattern.
With both IBM App Connect Enterprise and the backend using remote connections, MQ is no longer a local dependency and becomes more like an independent remote persistence store. This means that it could effectively be run on any platform as the MQ clients just see it as a component available over the network. We could move MQ to run for example on a separate virtual machine, or we could use the IBM MQ Appliance, or we might even consider using the IBM MQ on Cloud managed service, or we could simply run it in a separate container within our platform.
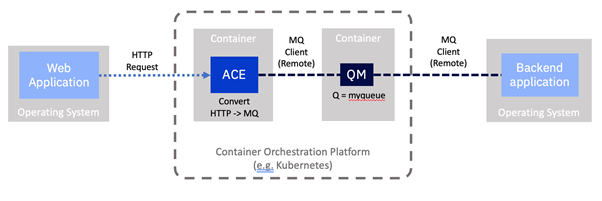
In line with our focus on containers in this series, for this example we’re going to run MQ in a container since we have already explored how to achieve this in a previous article.
Do you have to use remote MQ connections when moving to containers?
It is worth noting that it is not mandatory to move to remote connections when moving to containers, but as we will see, it is strongly recommended.
Whilst it is technically possible to run your existing flow with no changes and have a local MQ server running alongside IBM App Connect Enterprise in a single container, it should not be considered the preferred path. It goes against cloud native and container deployment principles on a number of levels and you would not gain the benefits noted above.
For this reason, remote queues are the recommended adoption path and IBM has made many enhancements specifically to enable and simplify remote MQ connectivity.
- IBM App Connect has no hard dependency on an MQ local server as it did in the past and all of the nodes in the flow assembly can now work with remote MQ servers.
- The IBM App Connect Certified Container that we have been using in our examples so far does not have a local MQ server, but instead, it has the MQ Client.
- IBM MQ has been significantly enhanced to adopt cloud native principles. Examples including native HA and uniform clusters.
Exploring our HTTP to MQ integration flow
Let’s look at our existing example flow in a little detail.
IBM App Connect Enterprise receives an incoming request over HTTP. This is handled by an integration that is in fact composed of two separate flows.
The first receives the request over HTTP and converts it to an MQ message, embedding the correlation id required to enable us to match up the response. It then places it on a queue on the local MQ server which will ultimately be propagated over an MQ channel to a queue manager on the backend system.
The second flow awaits a response message with the correct correlation from the backend system that is delivered via the MQ channel onto the local MQ server. It then turns this into an HTTP message. The correlation id is used to match it with the original HTTP request and the response is sent back to the caller.
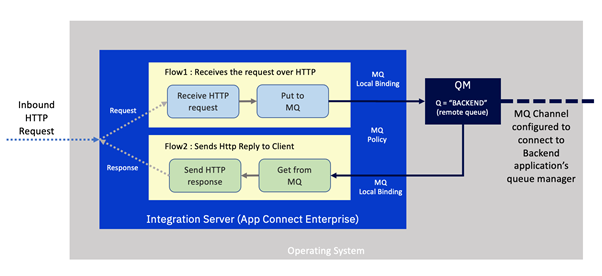
This is a very common pattern since it is a highly efficient way of handling the switch from a synchronous (HTTP) protocol to an asynchronous one (IBM MQ). The separation of request and response flows enables the integration server to handle greater concurrency, since the integration flow’s resources are not held up whilst awaiting a response from the backend server.
Notice also that the local queue manager has a “channel” configured to enable it to talk to the backend's queue manager and a remote queue is present to reflect the queue on the back end.
How will our flow change when it moves to containers?
Let's consider what this integration would look like if we moved it to a containerized environment.
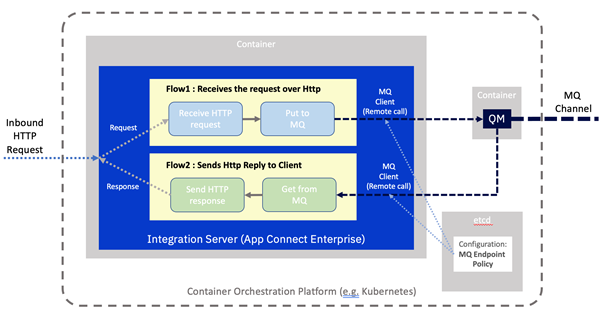
There are really only two changes.
- MQ is now running in a separate container rather than locally alongside IBM App Connect.
- ACE has been configured to use a remote connection to separate the MQ server.
This means our Integration Server will need to know where to find the MQ server on the network. This information could well be different per deployment, such as per environment (e.g. development, test, production), so we would not want it to be baked into the container image. As such it will be loaded in from a “configuration” stored by the container platform. In this case, an MQ Endpoint policy. Configuration objects were described in one of our earlier examples.
Deploying an MQ Queue Manager in a container
We will build on a previous example. Please follow the instructions from the following in order to deploy a queue manager on OpenShift using the user interface or command line.
Creating a queue manager in OpenShift
This should result in a queue manager running in a container with something like the following connection properties:
- Queue manager name : QUICKSTART
- Queues for applications to PUT and GET messages: BACKEND
- Channel for client communication with the integration server: ACEMQCLIENT
- MQ hostname and listener port: quickstart-cp4i-mq-ibm-mq/1414
Note, for simplicity, we will have no actual back end in our example, so we will simply use a single queue (“BACKEND”) to which we will put and get messages. In a real situation there would of course be send and receive queues, and channels configured for communication with the backend application.
Exploring the current integration flow
Let us first take a quick look at the actual message flows that we will be using for this scenario.
You will need an installation of the App Connect Toolkit to view the flow, and later to create the MQ Endpoint policy. Since this series is targeted at existing users of the product, we will assume you have knowledge of the Toolkit. Note that although you will be able to view the flow in older versions of the toolkit, to create the MQ Endpoint policy you will need to have a more recent version (v11/12) of the toolkit.
Sample Project Interchange and MQ policy project exports are available on GitHub at https://github.com/amarIBM/hello-world/tree/master/Samples/Scenario-5
After importing the Project Interchange file into the Toolkit, the Application project with request and response flows will appear as below
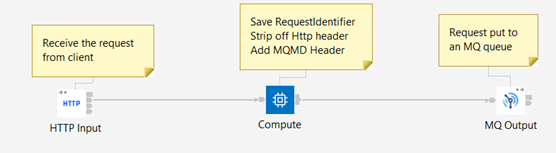
Request Flow:
- Receive the request over the HTTP protocol.
- Prepare an MQ message with the content of the HTTP request, and include the correlation information.
Put the message to the “BACKEND” MQ queue for the backend application to collect.
In a real situation, the backend application would read the message from the queue, process it, then respond into a different queue. For our simple example we do not have an actual back end system so we will simply read the original message straight back from the same queue and pretend that it is a response from the backend.
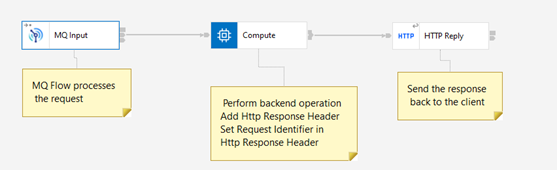
Response Flow:
- Reads the response message off the queue.
- Generates the HTTP response including the correlation data
- Sends the HTTP reply by coordinating reply with the request using Correlation id.
Re-configuring from local to remote queue managers
We will now re-configure our flow to use the new remote queue manager. First we will create an MQ Endpoint policy that specifies all the details about the remote queue manager, then create another configuration object to instruct the integration server to use the remote queue manager policy by default. Then we will embed these in configuration objects such that we can apply it to the container platform.
Create the MQ Endpoint policy containing the remote MQ connection properties
In App Connect Toolkit create a Policy project called “ACEMQEndpoint”, and under that create a policy of type MQEndpoint called "RemoteMQ".
Fill in the details in the Policy fields as shown below using the MQ connection details from our earlier queue manager deployment.
One thing to note here is the Queue manager host name. If Queue manager is running in a different namespace than the ACE Integration Server, then you need to qualify the service name using the namespace. So the queue manager host name would take the form :
<MQ service name>.<MQ namespace>.svc
Ultimately, this policy simply results in a file, which we can see in the tree structure on the filesystem:
<?xml version="1.0" encoding="UTF-8"?>
<policies>
<policy policyType="MQEndpoint" policyName="RemoteMQ" policyTemplate="MQEndpoint">
<connection>CLIENT</connection>
<destinationQueueManagerName>QUICKSTART</destinationQueueManagerName>
<queueManagerHostname>quickstart-cp4i-mq-ibm-mq.mq.svc</queueManagerHostname>
<listenerPortNumber>1414</listenerPortNumber>
<channelName>ACEMQCLIENT</channelName>
<securityIdentity></securityIdentity>
<useSSL>false</useSSL>
<SSLPeerName></SSLPeerName>
<SSLCipherSpec></SSLCipherSpec>
</policy>
</policies>
Embed the MQ Endpoint policy in a configuration object
All runtime settings for the App Connect Enterprise certified container are provided via “configuration objects”. This is a specifically formatted file with the runtime settings embedded that can then be applied to the container platform in advance of the container being deployed.
Export the policy project from the Toolkit as “Project Interchange” zip file.
Policy projects are embedded into configuration object in base64 form. So let’s first create the base64 representation of the policy project zip file that we just exported.
# cat ACEMQPolicy.zip |base64
Copy the output of your encoded file and paste it under the spec.contents section of a configuration file as shown below.
apiVersion: appconnect.ibm.com/v1beta1
kind: Configuration
metadata:
name: ace-mq-policy
namespace: ace
spec:
type: policyproject
contents: >-
UEsDBBQACAgIAOQGb1UAAAAAAAAAAAAAAAAWAAAAQUNFTVFFbmRwb2ludC8ucHJvamVjdK1RywrCMBA8K/gP0ruJ3jzEis+boqgf0KZriTQPklT0703SqBTBg3jbmczODFkyvfGqfwVtmBSTZISGSR8ElQUT5SQ5HdeDcTJNe12itLwAtUswVDNlndqxHSIyDulssdrsV6JQkglLcOD8I5Wcg7Apwc/Js9HJBIBbKK9ZVRwUUI8iXLjVTBSBiXnODbGcI7BSVgbxs0VKVozeUc1QWAKNdoGZN+hdynlkuqx9GxMxbhMEf+T+1qSZ8n80iMzza1y4rTVEdQO+d9kGjS8RtMHybfI6Q/u8D1BLBwhcj8Ry2AAAAB0CAABQSwMEFAAICAgA5AZvVQAAAAAAAAAAAAAAACAAAABBQ0VNUUVuZHBvaW50L1JlbW90ZU1RLnBvbGljeXhtbH1SQW7CMBC8V+ofotyDi8ShB5MKpVRFJZRAeIBxFrDq2MZ2UPl9ncS0LkWVIu3uzOza6wx++qx5dAJtmBTjeDh4iCMQVFZM7MfxpnxJHuOn9P4OK8kZZWBcHkV9dY76UJ4VjOO8mIpKSSZs7PEFqR2+glpayIsLWkKtOLG/O7qpbi6VQgC17i5pNp9NFyVGAeRFFRjLBGmhooEGciLIHnR7XFpsZtnbupysXOd/Oj/qGOCv0ljRcseG0Q9jibYJVSOW1MeEbWsXBu4zJ4rRzTY/kjNjQYBeSm0XTb0FnQ5HwxFGN4jL1gfiduTdxSbZNC++dw8Ir82y53KjeYrRJfOEAdpoZs+zCoR10Sn+QF7aGFiv5+mOcAMY
+cpzLl2CfySMwupHkDF1AL1WQHtJUAci0JbtGHW/ek62wL30GvUNeTFRivtTg8LTGrwN3lXnhAp2pOEWo2uicyfqndbaFgW+/QJQSwcIq4sDzGMBAADsAgAAUEsDBBQACAgIAOQGb1UAAAAAAAAAAAAAAAAfAAAAQUNFTVFFbmRwb2ludC9wb2xpY3kuZGVzY3JpcHRvco2OQQrCMBBF94J3CLM3UVdSmnYjrl3oAdp0qpEkUzKD2NsbEQQ34v6/91/dPmJQd8zsKVnY6DUoTI4Gny4WzqfDageKpUtDFyihhRkZ2ma5qBNvq4mCd/Mx0w2d7JFd9pNQVsWZ2MJVZKqMcRS176NGIQqs4yh6+Gx13zHCm6iK80/q6xlKj1J1xhFziUc2r0Dzo7B5AlBLBwguwxv8lgAAAPgAAABQSwECFAAUAAgICADkBm9VXI/EctgAAAAdAgAAFgAAAAAAAAAAAAAAAAAAAAAAQUNFTVFFbmRwb2ludC8ucHJvamVjdFBLAQIUABQACAgIAOQGb1WriwPMYwEAAOwCAAAgAAAAAAAAAAAAAAAAABwBAABBQ0VNUUVuZHBvaW50L1JlbW90ZU1RLnBvbGljeXhtbFBLAQIUABQACAgIAOQGb1Uuwxv8lgAAAPgAAAAfAAAAAAAAAAAAAAAAAM0CAABBQ0VNUUVuZHBvaW50L3BvbGljeS5kZXNjcmlwdG9yUEsFBgAAAAADAAMA3wAAALADAAAAAA==
Save this as a file named ace-mq-policy.yaml
Refer to the MQ Endpoint policy in a server.conf.yaml configuration object
By using a remote default queue manager, you can configure integration servers to direct all MQ traffic to a remote MQ server, without configuring policy settings on each message flow node. The default queue manager property is available via server.conf.yaml. So let’s create the base64 representation of the property.
$ echo "remoteDefaultQueueManager: '{ACEMQEndpoint}:RemoteMQ'" | base64
(Insert the output of above command into the 'data:' section in below server.conf.yaml configuration object definition)
Save the below file as remote-default-qm.yaml
apiVersion: appconnect.ibm.com/v1beta1
kind: Configuration
metadata:
name: remote-mq
namespace: mynamespace
spec:
type: server.conf.yaml
description: Configuration for remote default queue manager
data: cmVtb3RlRGVmYXVsdFF1ZXVlTWFuYWdlcjogJ3tBQ0VNUUVuZHBvaW50fTpSZW1vdGVNUScK
Apply the configuration object to the container platform
Use the commands shown below to create the configuration objects in our OpenShift environment using the policy files that we just created in the previous steps.
# oc apply -f ace-mq-policy.yaml
# oc apply -f remote-default-qm.yaml
Deploy the Integration to OpenShift
We will now deploy the integration onto the OpenShift platform just as we have in previous scenarios. The only difference this time is that we will inform the deployment that there is a new MQ Endpoint policy stored in a configuration.
Create Integration Server definition file pointing to the new MQ Endpoint policy
The sample Integration server YAML definition points to the new configuration “ace-mq-policy” and "remote-mq"that we created in the previous section. For convenience, it pulls down a pre-prepared bar file from GitHub that already has the amendments to the MQ Input and MQ Output nodes to look for an MQ Endpoint just like we described in the previous sections.
Copy the following contents to a YAML file as IS-mq-backend-service.yaml
apiVersion: appconnect.ibm.com/v1beta1
kind: IntegrationServer
metadata:
name: http-mq-backend-service
namespace: ace
labels: {}
spec:
adminServerSecure: false
barURL: >-
https://github.com/amarIBM/hello-world/raw/master/Samples/Scenario-5/SimpleHttpMQBackendApp.bar
configurations:
- github-barauth
- ace-mq-policy
- remote-mq
createDashboardUsers: true
designerFlowsOperationMode: disabled
enableMetrics: true
license:
accept: true
license: L-KSBM-C37J2R
use: AppConnectEnterpriseProduction
pod:
containers:
runtime:
resources:
limits:
cpu: 300m
memory: 350Mi
requests:
cpu: 300m
memory: 300Mi
replicas: 1
router:
timeout: 120s
service:
endpointType: http
version: '12.0'
Deploy Integration Server
We now use the YAML definition file created above to deploy the Integration Server.
#oc apply -f IS-mq-backend-service.yaml
Verify the deployment
You can check the logs of Integration Server pod to verify that the deployment has been successful and that a listener has started listening for the incoming HTTP request on the service endpoint.
#oc logs <IS pod>
2021-11-26 11:50:59.255912: BIP2155I: About to 'Start' the deployed resource 'HttpMQApp' of type 'Application'.
An http endpoint was registered on port '7800', path '/BackendService'.
2021-11-26 11:50:59.332248: BIP3132I: The HTTP Listener has started listening on port '7800' for 'http' connections.
2021-11-26 11:50:59.332412: BIP1996I: Listening on HTTP URL '/BackendService'.
Started native listener for HTTP input node on port 7800 for URL /BackendService
2021-11-26 11:50:59.332780: BIP2269I: Deployed resource 'SimpleHttpMQBackendFlow' (uuid='SimpleHttpMQBackendFlow',type='MessageFlow') started successfully.
Testing the message flow
Let us test the message flow by invoking the service url using Curl command
Request : We have already seen in previous articles on how to get the public url using ‘oc route’ command. Once you obtain the external URL, invoke the Request flow using the following command parameters.
# curl -X POST http://ace-mq-backend-service-http-ace.apps.cp4i-2021-demo.xxx.com/BackendService --data "<Request>Test Request</Request>"
Output :
You should see a response as below as a result of end to end processing by Request-Response flow.
<Response><message>This is a response from backend service</message></Response>
Common Error Scenarios :
If you encounter any errors related to remote MQ connectivity during runtime, they are usually the result of some missing configuration or incorrect configuration. A list of possible errors a user might come across and possible resolutions are compiled in the following document.
https://github.com/tdolby-at-uk-ibm-com/ace-remoteQM-policy/blob/main/README-errors.md
Advanced topics
So we have seen the simplest path for an integration involving MQ.
- We reconfigured our flow to use remote calls, and provided it with the MQ remote connection properties using a “configuration” pre-loaded onto OpenShift.
- We then deployed the reconfigured bar file to OpenShift using the IBM App Connect certified container which already containers the MQ Client.
Let’s consider some slightly more advanced scenarios and what they might entail.
What if we scale ACE integrations that use MQ request/reply (pod replica > 1)?
The example described above works well when you run single replica of your ACE containers. However, if you scale your integration with >1 replicas then the above scenario may pose some challenges. Please refer to the blog post "Scaling ACE integrations that use MQ request/reply" to understand those challenges and how to resolve them using the startup script feature available in ACE 12.0.5 onward.
What if the MQ queue manager we want to talk to isn’t running in a container in OpenShift?
The good news here is that since we’ve moved to using a remote client connection, App Connect doesn’t really care where the queue manager is running. In theory, it could connect directly to a remote queue manager that is for example running on a mainframe, so long as the integration server can see the queue manager host and port over the network. As with any networking scenario, we should consider the latency and reliability of the connection. If we know the network between the two points has high latency, or has availability issues, it might be better to introduce a nearer queue manager in a container in OpenShift, then create a server to server MQ channel to the backend’s queue manager. The inherent benefits of MQ’s mature channel management will then manage network issues as they have always done.
What if we really do need a local MQ queue manager?
As noted earlier, it is still possible to run a local MQ server in the same container as the integration server, although the circumstances where this is required are hopefully rare. If you do need a local queue manager, this does mean that the integration server becomes more stateful, which may make it harder to scale. You would need to build a custom container image with the MQ server included (although you could base that on the certified container image as a starting point). However, the good news is that in containers we can deploy in a more fine-grained style. It’s likely that not all of your integrations require local MQ servers. So, you could use the standard certified container for those integrations, and only use your custom container where necessary.
How many queue managers should I have?
If originally you had 10 integrations, all using the same local queue manager, should you create one remote queue manager, or 10? In all honesty, this probably deserves a dedicated article of its own, as there are many different possibilities to be explored here. There are a few simple statements we can make however. It really comes down to ownership. Who is going to be looking after those queue managers operationally? Who is most affected by their availability? Who is likely to be making changes to them? The main benefits for splitting out queue managers would be so that they can be operated independently, changed independently, have independently configured availability characteristics etc. If none of that independence is required, you could continue to have all the queues relating to these integrations on queue manager.
As mentioned, many of the above advanced topics may well make good candidates for a future post. If you’d be particularly interested in a particular topic (maybe even one we’ve not yet covered), feel free to let us know in the comments to this post.
Acknowledgement and thanks to Kim Clark for providing valuable technical input to this article.
#AppConnectEnterprise(ACE)
#containers
#Docker
#IntegrationBus(IIB)
#MQ