When faced with the need to pass information asynchronously between components, there are two main technology choices: messaging and event streaming. We have chosen to have both of these technologies in the IBM integration portfolio in the form of IBM MQ and IBM Event Streams. While they share many common features, there are fundamental differences that make it crucial to choose correctly between the two, and indeed understand how the can complement one another.
Messaging grew from the need for assured, decoupled delivery of data items across heterogeneous platforms and challenging networks. In contrast, event streaming provides a historical record of events for subscribers to peruse. The most common event streaming platform is the open-source Apache Kafka.
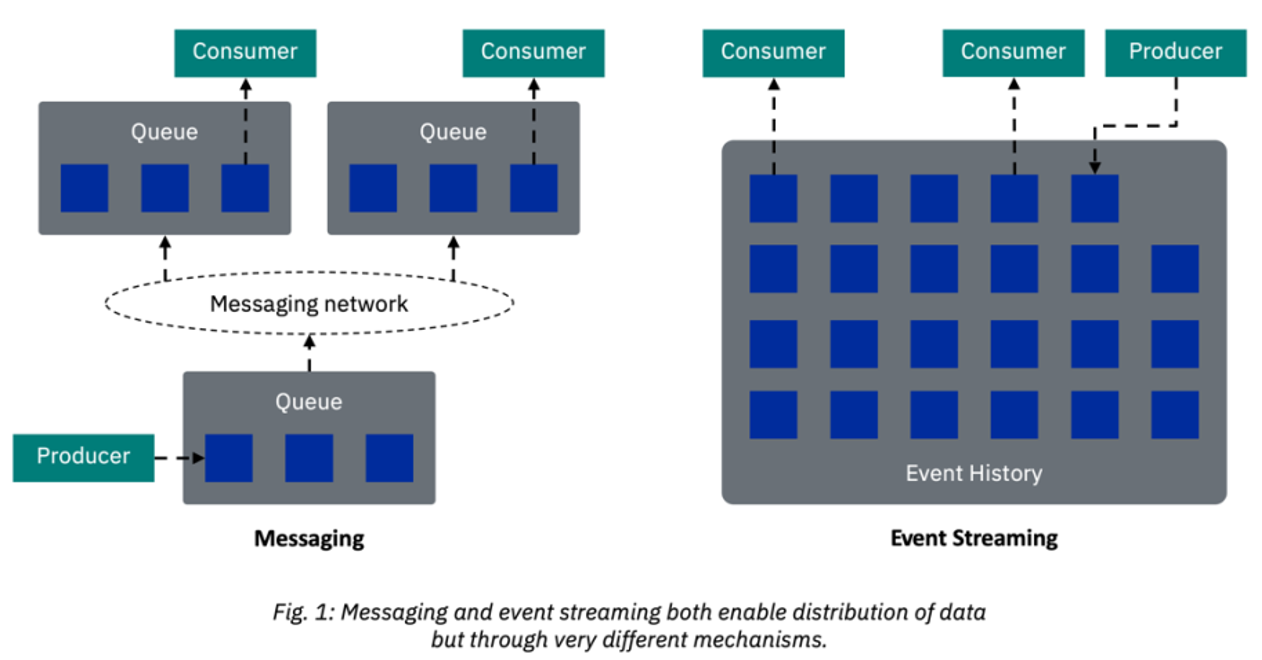 A core difference between messaging and event streaming is that messages are destroyed when read, whereas event streaming retains an event history. But while this may help us understand the technical difference, we’ll need to dig a bit deeper to understand the usage difference.
A core difference between messaging and event streaming is that messages are destroyed when read, whereas event streaming retains an event history. But while this may help us understand the technical difference, we’ll need to dig a bit deeper to understand the usage difference.
Publish/subscribe implementations are subtly different, and the differences matter.
Messaging excels with dynamically changing and scalable consumer groups (a set of consumers that work together to read a topic/queue), and enables fine-grained, hierarchical, and dynamic topics. Publish/subscribe over topics is just one of multiple interaction patterns that can be achieved with messaging. Kafka is focused on the publish/subscribe pattern only, and excels when there are large numbers of subscribers to all events on the topic, since it works from one, unchanging copy of the data (the event history) and partitions topic data across disks to enable parallelism. However, you need to be at very high volumes of events and very large numbers of consumers (100+) for this to actually matter. Note that Kafka always uses a publish/subscribe interaction pattern.
Don’t use publish/subscribe to perform request/response patterns.
Messaging enables multiple interaction patterns beyond publish/subscribe and is often used for request/response. Since Kafka only performs the publish/subscribe interaction pattern, it should not be used for request/response. While it may be technically possible to use publish/subscribe for request/response, it tends to lead to unnecessary complexity and/or poor performance at scale.
Message queuing offers granular deployment, whereas the event stream history requires a significant minimum infrastructure.
Messaging can be deployed on independent compute resources, as small as a fraction of a CPU. As such, it can be deployed alongside an application and in low infrastructure landscapes, such as retail stores, or even directly on devices. Kafka, due to its stream history, is a multi-component, storage- focused infrastructure. As a result, Kafka is typically deployed as a shared capacity with a significant minimum footprint and more complex operational needs.
The overhead of Kafka’s stream history is worth accommodating if you have the right use case.
Kafka’s stream history enables three key interaction patterns that do not come out of the box with messaging. The first is ‘replay,’ which is able to replay events for testing, reinflation of a cache, or data projection. This underpins application patterns such as event sourcing and CQRS. The second is ‘stream processing,’ which is the ability to continuously analyze all or part of the stream at once, discovering patterns within it. The third is ‘persisted audit log.’ Since the event history is immutable, the event data cannot be changed and can only be deleted via archiving.
Individual message delivery and mass event transmission are opposing use cases.
Messaging uses queues to store pieces of data (i.e., messages) that are to be discretely consumed by the target system, known variously as fire/forget, point to point, or the command pattern. As such, messaging is a good fit when it’s important to know whether you have consumed each individual message. It excels at “exactly once” delivery, which makes it very strong for transactional integrity. Kafka, on the other hand, provides events as a log shared by all consumers who consume such events. It provides “at least once” delivery and is at its most efficient when consumers poll for arrays of records to process together. This makes Kafka a good choice for enabling a large number of consumers to consume events at high rates.
Consider where and how data integrity is handled.
Messaging enables transactional delivery of each message such that they appear to the consumer as a single ACID (atomicity, consistency, isolation, durability) interaction. Kafka pushes integrity concerns to the consumer (and provider to some extent), requiring a more complex interaction to ensure integrity. This is less of a concern where target systems are inherently idempotent (i.e., have an ability to ignore duplicate requests).
Wrapping it up
In reality, we often see these technologies used in combination, each fulfilling the patterns they are designed for. (For a deeper dive into event driven architecture, see The resurgence of event driven architecture.) It may help to distinguish between messaging and event streaming by considering that, whereas queue-based messaging provides an asynchronous transport, Kafka is more of an alternative type of datastore. There are clearly limitations in that analogy, but it does help to separate the primary purpose of each technology.
Messaging ensures that messages are eventually delivered to their target applications (regardless of the reliability of the intervening network), whereas event streaming provides a historical record of the events that have occurred. Despite their superficial similarities, the unique characteristics and requirements of each technology make them each important to an enterprise integration strategy.
#IBMEventStreams