It's June 2022, and we've just released IBM MQ 9.3, the latest long term support release for IBM MQ. Many of you will know that this is two years on from 9.2 LTS, and in that time we’ve introduced an amazing set of updates and innovation.
Many of these features we've been talking about for a while, as they have become available through the continuous delivery (CD) path over the last two years. With that constant, incremental, delivery it can sometimes be hard to see the bigger picture of what we’ve been working on. An LTS release is that perfect point to step back and take stock of the many features the team has added over the last couple of years. They're all documented individually here, but I think that misses the full impact, so instead, let's see what they look like as a whole...
 That’s a lot of improvements! And each is critical to many of you. However, I thought it would be worth singling out just a few of the more significant additions as they really highlight the work going into MQ today and how it is continuously evolving and, most importantly, innovating to match your needs…
That’s a lot of improvements! And each is critical to many of you. However, I thought it would be worth singling out just a few of the more significant additions as they really highlight the work going into MQ today and how it is continuously evolving and, most importantly, innovating to match your needs…
Native HA, Raft-based data replication and consensus
This one is genuinely a huge step forward for MQ container deployments, and MQ in general. 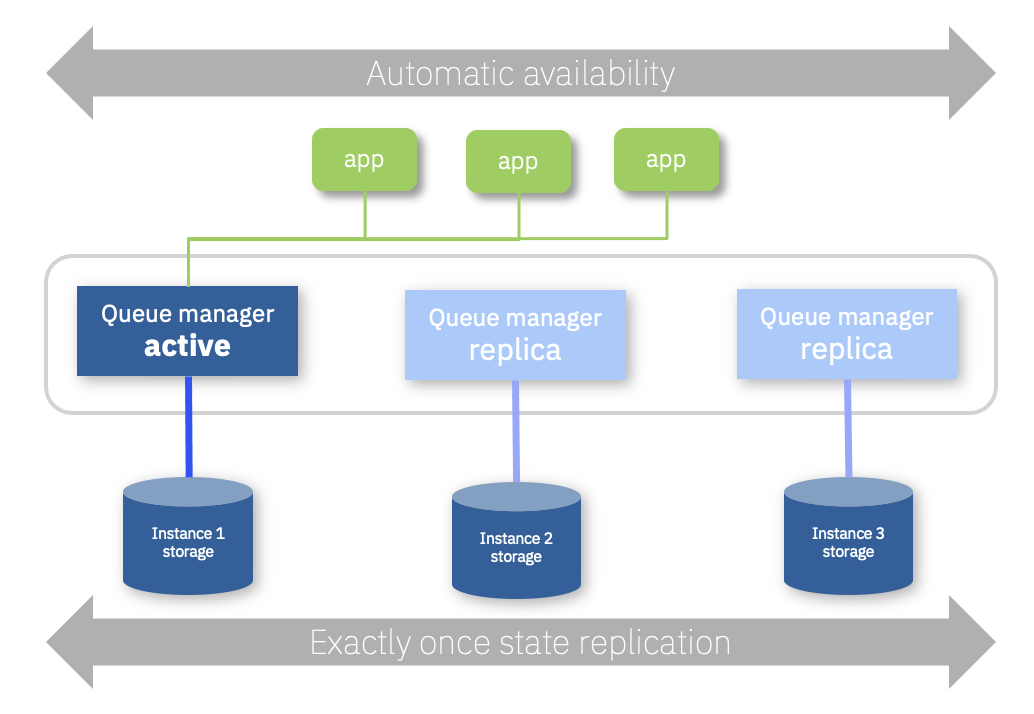
We’ve had data replication and recovery for many years in MQ, with RDQM in Linux and the MQ Appliance. However, these solutions build in the storage-based components necessary to support MQ’s needs. These don’t transition particularly well to MQ in Kubernetes and OpenShift environments, where we wanted a very simple deployment of a queue manager that provided cross-AZ replication and availability based on very simple sets of storage. So for that we went back to the drawing board and decided to, once and for all, open up the core of the queue manager and implement our own replication and recovery logic. Now, this was no simple piece of work, but the great thing was that we could build on top of many existing building blocks in MQ, coupled with the Raft consensus algorithm to give us a truly integrated, efficient and responsive HA answer. And critically, maintaining MQ’s proven resiliency for each and every messaging operation, giving you the same exactly once delivery assurances that many depend on. So Native HA in every sense of the term. We’ve then packaged this up in OpenShift with MQ’s Operator to make deployment as simple as setting a single property. Simple.
Streaming queues
I really like this one, it’s something we’ve wanted to get into MQ for a long time and has proved to be instantly popular.
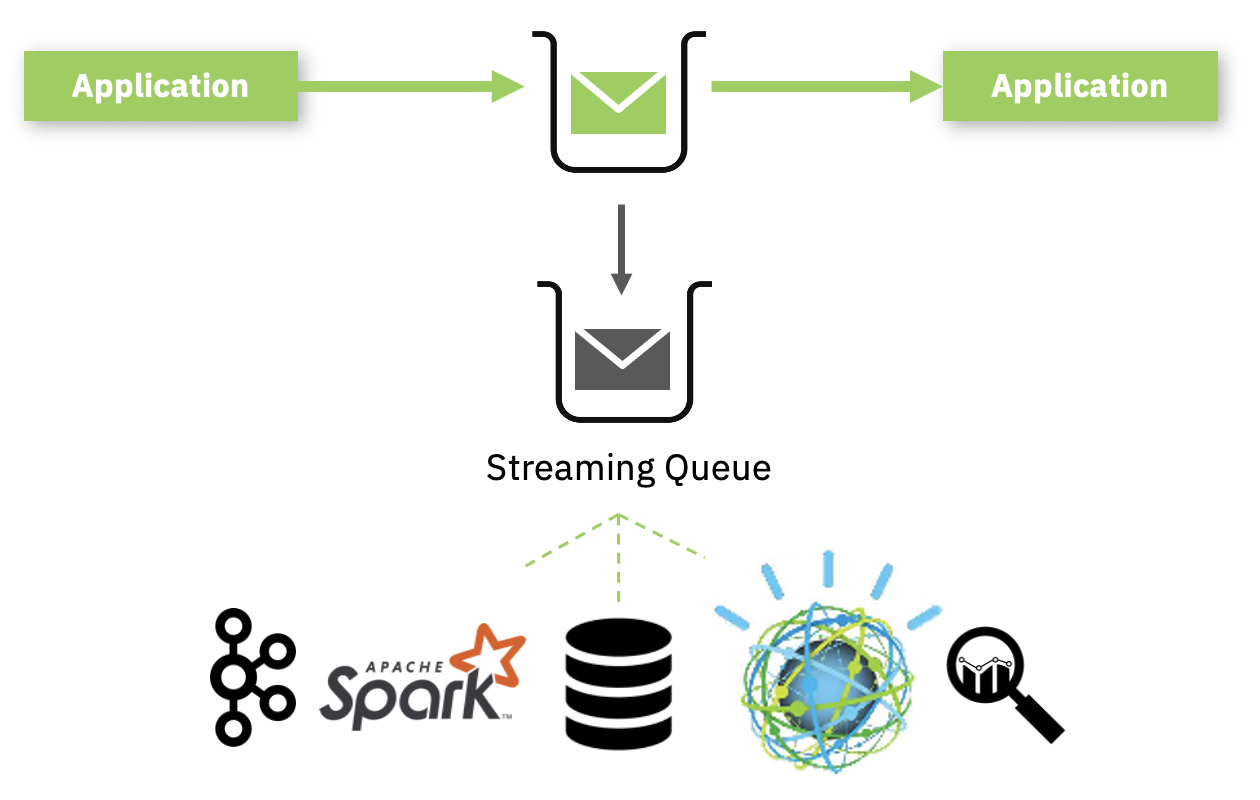
What is a streaming queue? At its heart, you can now configure a queue so that for every message that lands on it, another copy is sent off to another queue. So what’s the point of that? Well, now you can tap into streams of messages, without the original application needing to be aware or changing its behaviour, and start putting those extra copies of messages to a wide range of other uses. Our initial ideas were to enable further analysis of the data by systems Apache Kafka Streams, or simply to offload to a DB as an audit trail. But you’ve come up with some other great use cases. One has been to collect a stream of real production data that can test out a new cloud deployment. Another is to aid application development and debugging by making even the consumed messages visible to you. Others have coupled Streaming Queues with automatic message expiry, this opens up many more interesting uses, such as the ability to keep a rolling history of production data that can be replayed if needed, just in case your application accidentally drops it, or even to stream off to another queue manager in another region as a selective DR solution. As you can see, the options seem endless.
Smarter application re-balancing
IBM MQ 9.2 LTS was where MQ’s Uniform Clusters went mainstream. Since then, we’ve made them even smarter.
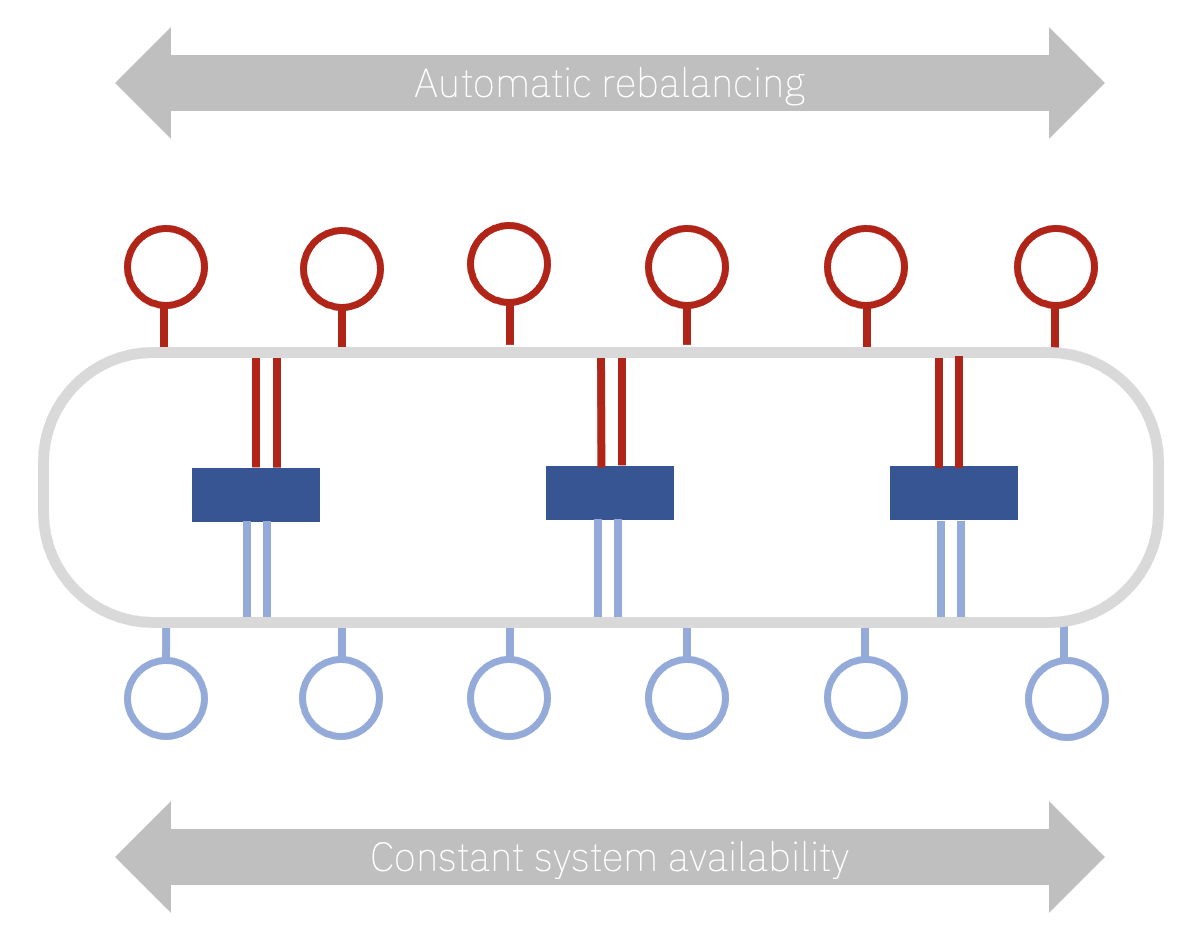 If you’re not familiar with Uniform Clusters, these give you automatic application instance rebalancing across a group of queue managers. So what does that mean? Basically, you can fire a bunch of instances of an application at the queue managers (the Uniform Cluster) and MQ will ensure that the instances stay evenly balanced. This ensures you get the best partitioning of the message data across the queue managers, even in the face of dynamically changing numbers of applications instances, failures and even dynamic changes to the number of queue managers. This gives you a truly decoupled, horizontally scaled, solution. Both for applications and queue managers.
If you’re not familiar with Uniform Clusters, these give you automatic application instance rebalancing across a group of queue managers. So what does that mean? Basically, you can fire a bunch of instances of an application at the queue managers (the Uniform Cluster) and MQ will ensure that the instances stay evenly balanced. This ensures you get the best partitioning of the message data across the queue managers, even in the face of dynamically changing numbers of applications instances, failures and even dynamic changes to the number of queue managers. This gives you a truly decoupled, horizontally scaled, solution. Both for applications and queue managers.
So what’s the catch? Well, to take advantage of this, your apps need to play ball. By that I mean they need to be willing to act like horizontally scalable, cloud native, applications, and not have close affinity to one queue manager in particular (you know, like we did in the past). That’s easy for some applications, but not all. So that’s the problem we’ve been focusing on more recently. Now we have more smarts in MQ to detect when applications are transiently tied to a particular queue manager, for example, when half way through a transaction, or waiting for a reply to a request message. With this you can start to widen the set of applications that can take advantage of a horizontally scaled solution.
Appliance data encryption
When we introduced the first MQ physical appliance we knew having a pre-formed MQ platform was what many needed, bringing together the compute, storage, security and availability needed for many MQ users.
And since then we’ve continued to evolve the appliance, to meet your growing needs. One thing we added recently was the introduction of simple encryption at rest of the message data. So not only are all your storage needs met with the appliance, but also your security requirements for that critical message data when it lands on an appliance queue manager.
Growing MQ’s open protocols
Not everyone realizes that MQ is a multi-protocol messaging broker, where applications using different APIs and wire-protocols can exchange messages seamlessly.
 Since 9.2 we’ve been working on filling out our support. One of the biggest advances was in our AMQP 1.0 support. This is an open standard messaging protocol, supported by a number of different messaging solutions. MQ has had a limited support for this for a little while, but more recently we’ve widened it to cover both publish/subscribe and point-to-point. And importantly we’ve done this in a way that is in line with one of the most popular open source clients available, Apache Qpid JMS. This has ensured that your applications will work the same, whichever messaging solution you are connected to.
Since 9.2 we’ve been working on filling out our support. One of the biggest advances was in our AMQP 1.0 support. This is an open standard messaging protocol, supported by a number of different messaging solutions. MQ has had a limited support for this for a little while, but more recently we’ve widened it to cover both publish/subscribe and point-to-point. And importantly we’ve done this in a way that is in line with one of the most popular open source clients available, Apache Qpid JMS. This has ensured that your applications will work the same, whichever messaging solution you are connected to.
We’ve also seen a rise in use of MQ’s REST messaging API over HTTP, particularly where it’s used to exchange messages with other applications and APIs. And for this we’ve extended the REST support to expose some of the more useful message and user properties.
Finally
Like I mentioned at the start, there are many more updates in 9.3 LTS that you can all take advantage of, I’ve only picked out a handful. And remember, many of these capabilities are constantly evolving, and it’ll only be a few months until the next continuous delivery release once we have 9.3, where you’ll get to see what’s coming next.
And just in case you're wondering, this time we have a slightly staggered delivery of 9.3 LTS. It is initially coming out on the Distributed software platforms, but we fully intend to follow that up across the board, with z/OS and new Appliance firmware as soon as we can. So once that happens, you'll have LTS versions across the board.