This blog is part of a series. For the whole series list see here .
Introduction
The embedded Global Cache (GC) feature in IBM Integration Bus (IIB) and IBM App Connect Enterprise (ACE) provides an 'in-memory' caching solution which is based on WebSphere Extreme Scale (WXS) technology. Several IIB/ACE customers use this feature to store static data to minimize network/IO interactions to back-end systems which could be expensive in terms of performance.
While this works well for the traditional on-premises or VM style deployment of IIB/ACE, the WebSphere Extreme Scale does not support embedded global cache in a Kubernetes environment, which means customers looking to migrate to IBM Cloud Pak for Integration(CP4I) would need an alternate caching solution.
ACE V12.0.4 provides a new caching solution called embedded local cache based on Java HashMap. You can configure the embedded local cache to allow message flows that contain cache lookups to run within containerized environments, which do not support the embedded global cache. This capability is available in version 12.0.4.0 onwards.
When using the embedded local cache, a Java HashMap is used as the underlying storage for the map instead of a WebSphere eXtreme Scale grid, which means the embedded local cache is scoped to a single integration server. Each integration server will have its own in-memory copy of the cache, and updates made in one integration server will not be reflected in other integration servers.
The embedded local cache is API compatible with the embedded global cache. This means that message flows will continue to work as designed when switching between the local and global variants of the cache.
To configure an integration server to use the embedded local cache instead of the embedded global cache, set the env var MQSI_GLOBAL_CACHE_USE_LOCAL_CACHE in the server.conf.yaml file as follows:
EnvironmentVariables:
MQSI_GLOBAL_CACHE_USE_LOCAL_CACHE: 'true'
Note : The cacheOn property in the server.conf.yaml file controls whether to start up the WebSphere eXtreme Scale resources. Therefore, when running in container, make sure that cacheOn property is set to ‘false’ server.conf.yaml (The default is 'false').
If you are creating your own container image, you may provide this property change via the server.conf.yaml in the image. If you are using the App Connect Operator, you may choose to provide a server.conf.yaml file via a Configuration, and this is the mechanism we’ll show in this blog.
Demonstration:
We now demonstrate the migration of a simple message flow that was originally developed to use WXS based embedded Global Cache, to the containerized environment to use the embedded local cache solution based on Java Hashmap .
The artifacts discussed in this article are available here
Existing flows using WXS Global Cache APIs to read and write data to cache
1) Message flow for inserting/updating an entry in the Cache using

Sample java code that demonstrates the Global Cache APIs to interact with Cache:
MbElement Map = root.getLastChild().getFirstChild().getFirstChild();
String MapName;
MapName = Map.getFirstChild().getValueAsString();
MbGlobalMap globalMap = MbGlobalMap.getGlobalMap(MapName);
MbElement mValue = Map.getLastChild();
MbElement mKey = mValue.getPreviousSibling();
String Key = mKey.getValueAsString();
String Value = mValue.getValueAsString();
if(globalMap.containsKey(Key)){
globalMap.update(Key, Value );
} else {
globalMap.put(Key,Value);
}
Input Message :
curl -X POST -i http://localhost:7800/put --data '<Message> <map name='\''map1'\''> <key>key1</key> <value>value1</value></map></Message>'
Output Response:
<Message>
<map name="map1">
<Result>Map Successfully created</Result>
<key>key1</key>
<value>value1</value>
</map>
</Message>
2) Message flow for reading data from the Cache
The code snippet from Java Compute Node
MbElement Map = root.getLastChild().getFirstChild().getFirstChild();
String MapName;
MapName = Map.getFirstChild().getValueAsString();
MbGlobalMap globalMap = MbGlobalMap.getGlobalMap(MapName);
MbElement mKey = Map.getLastChild();
String Key = mKey.getValueAsString();
// to retrive the map data
String value = String.valueOf(globalMap.get(Key));
MbElement val = Map.createElementAsLastChild(MbElement.TYPE_NAME_VALUE, "Value", value);
Input Message :
curl -X POST -i http://localhost:7800/get --data '<Message><map name='\''map1'\''> <key>key1</key></map> </Message>'
Output Message :
<Message>
<map name="map1">
<key>key1</key>
<value>value1</value>
</map>
</Message>
Migrating the message flow to ACE Containers running in CP4I
As we mentioned in the Introduction section, The embedded local cache is API compatible with the embedded global cache. This means that message flows will continue to work as designed when switching between the local and global variants of the cache.
So here are the steps:
- Package your existing flows in a BAR file. Ensure that the flow that populates the data into cache and flows that read the data from cache are packaged into the same BAR file.
- From the ACE Dashboard, create New Integration Server
- Upload the BAR file when prompted through the UI steps.
- On the ‘Configuration’ panel, create new server.conf.yaml configuration by adding an envvar as shown below
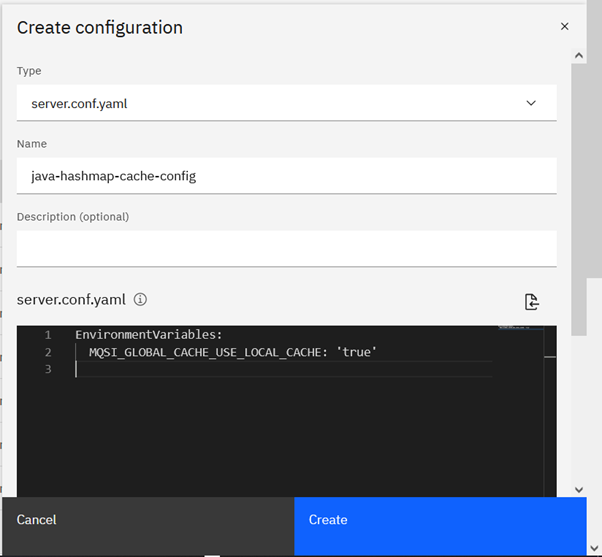
- Attach this configuration to your integration server deployment.
- Once the Integration server is up and running, check the pod log for following message.
2022-05-25 05:59:39.160696: BIP1990I: Integration server 'demo-local-cache' starting initialization; version '12.0.4.0' (64-bit)
2022-05-25 05:59:39.161224: BIP9566I: Setting environment variable 'MQSI_GLOBAL_CACHE_USE_LOCAL_CACHE'.
- This message confirms that the Local cache is in effect.
- Invoke the message flow to put some data into the cache
curl -X POST -i http://my-cp4i-cluster.ibm.com/put --data '<Message> <map name='\''map1'\''> <key>key1</key> <value>value1</value></map></Message>'
Response:
<Message>
<map name="map1">
<Result>Map Successfully created</Result>
<key>key1</key>
<value>value1</value>
</map>
</Message>
- Invoke another flow that reads data from the cache.
curl -X POST -i http://my-cp4i-cluster.ibm.com/get --data '<Message><map name='\''map1'\''> <key>key1</key></map> </Message>'
Response :
<Message>
<map name="map1">
<key>key1</key>
<value>value1</value>
</map>
</Message>
The value 'value1' inserted using the first flow has been successfully retrieved by second flow by passing the key name and map name through input message.
Note that although we used the App Connect Dashboard in the example above, this can all of course be done from the command line or Kubernetes API to enable deployment automation via pipelines. This is done by creating custom resource files for Integration Servers and Configurations, and applying them to the Kubernetes environment using the kubectl command. There are many examples of this in the other blogs in this series.
Conclusion
As you can see from above demonstration that you can reuse your existing flows 'as-is' when moving from WXS based caching solution to Java HashMap based caching solution in container environment. You can switch to using Java HashMap based caching solution by just setting an env variable in server.conf.yaml when you deploy the BAR file to IntegrationServer.
If your existing IIB/ACE Global Cache is setup such that several integration servers share the same cache hosted on a common grid, then while moving to Java Hashmap based local cache in containers, you will need to refactor the BAR file and grouping of flows such that the flows that act (insert/update/read) on the same cache data are deployed to same integration server as embedded local cache is scoped to a single integration server. Each integration server will have its own in-memory copy of the cache, and updates made in one integration server will not be reflected in other integration servers.