Purpose:
This article discusses a specific scenario to pay attention to in terms of object identifier best practices.
Its importance is mostly related to performance implications (both pre-calc time during dev/stage calcs, and real-time when working on config in dev).
Additional information about identifiers and allocation best practices can be found here:
Performance Review – Effective Use Of An Identifier in R12
Create a custom table identifier
Identifiers
Use Case:
The most common use case is having a modeled object that has multiple outgoing and/or incoming allocations.
It is common that each of those in/outbound allocations has a data relationship and/or filtering set based on different columns in the modeled object’s data.
Problem:
When a subset of rows requires an additional level of granularity for their allocation in/out, the natural tendency is to simply include this additional level of granularity in the object identifier. That is very easy to do simply by checking the box for the required column in the object identifier settings screen.
However, this may result in increased data volumes on the identifier level, leading to bigger AR tables for allocations and drills. This is because the data relationship for the allocations that don't require that additional granularity will be weakened, meaning that for each row in the destination object (for an outbound allocation) there will be more rows in our table that match it.
Ultimately this will result in longer calculation times for dev/stage builds and poorer real-time performance when working on the config in dev and when navigating to some of the reports affected by this table.
For a "pivotal" modeled object, meaning one which is important for various drills and/or reports, the performance impact may be great, so setting the identifier as efficiently as possible is crucial.
Recommended Solution:
The recommended solution is to use a flag or a re-evaluation of the extra granular level(s), and use that in the identifier instead of the actual column(s) in order to group the dataset down as much as possible.
E.g., consider the following example:
The Labor object below has multiple incoming and outgoing allocations: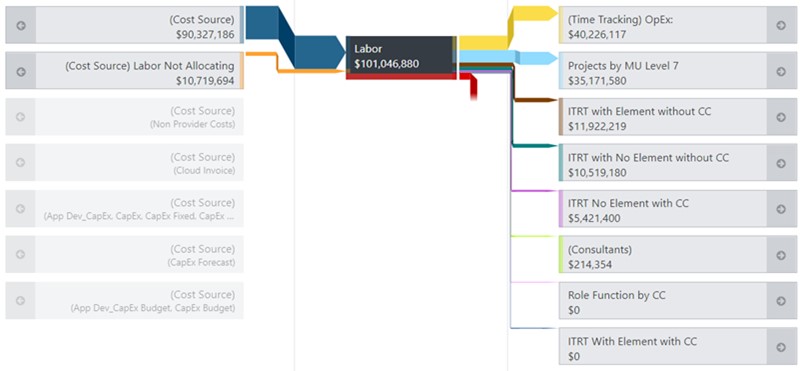
Currently, the object identifier has ~14K rows: 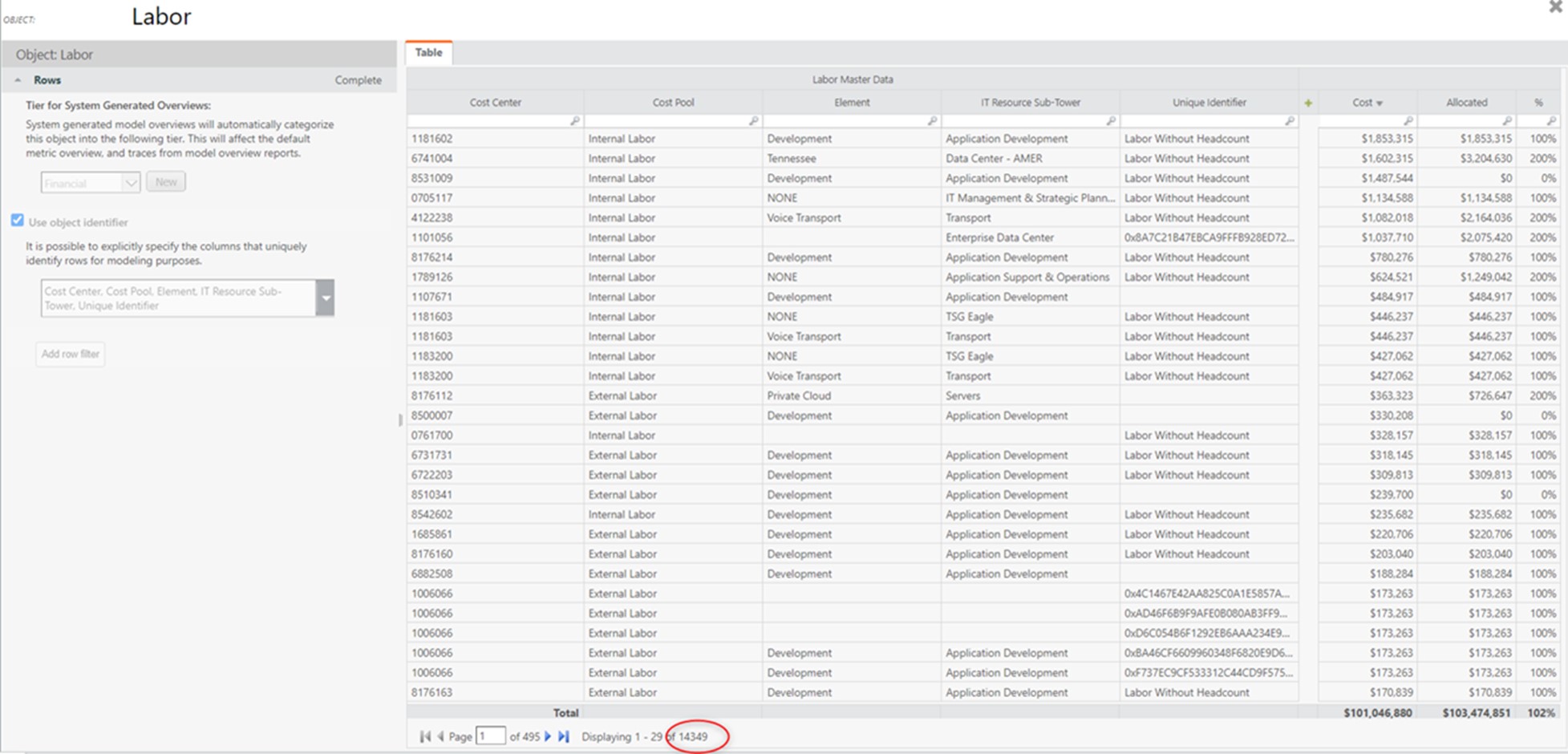
Now, let’s see what columns all the defined allocations are based on.
Both allocations into Labor are based on Cost Center and Cost Pool (this is taking into account the columns used in the “To” filters and in “Data Relationship”.
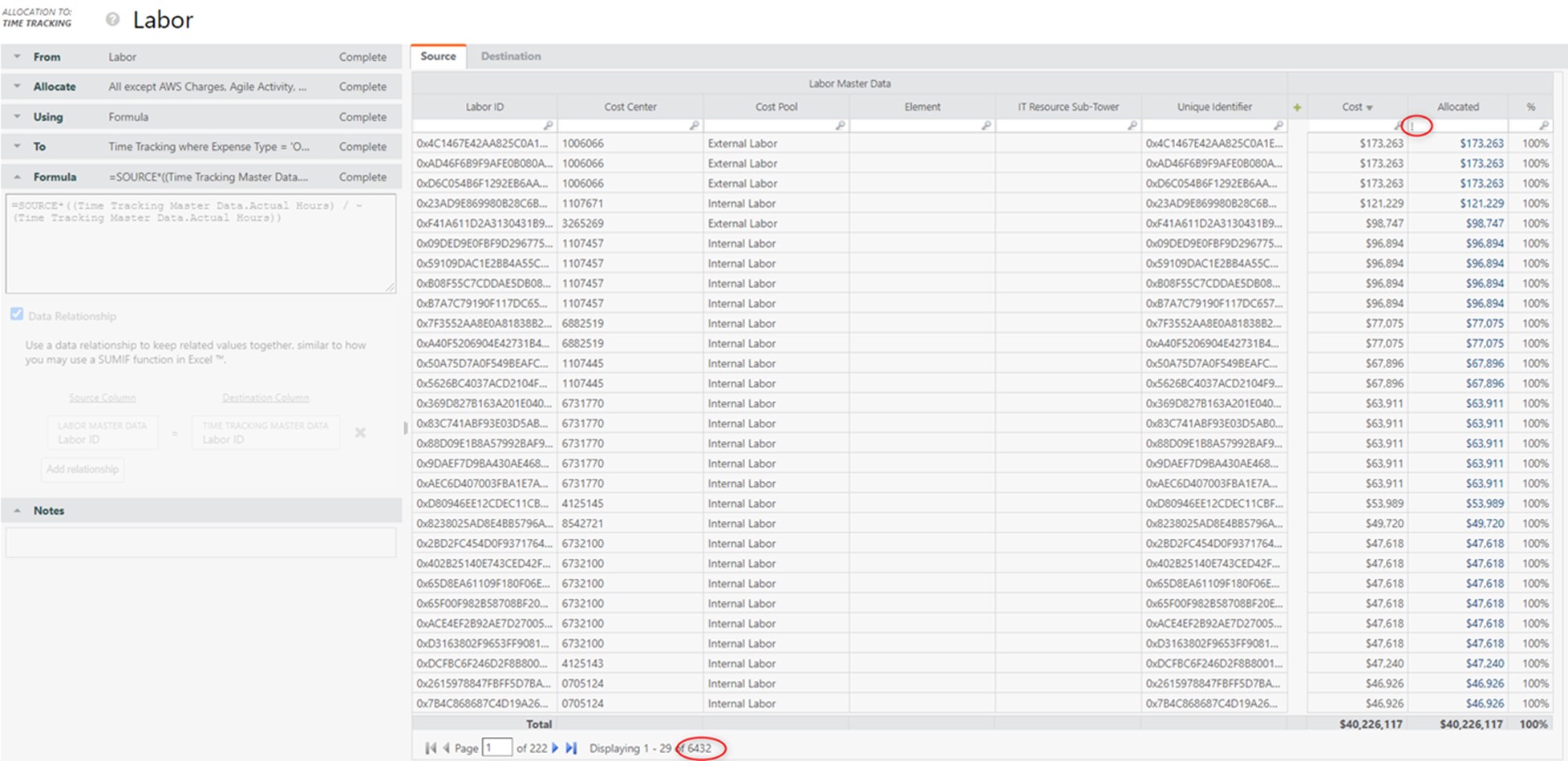
The only allocation out that is using “Labor ID”, which is part of the unique identifier column, is “Time Tracking”. This allocation affects ~6.5K rows (i.e., less than half of the total ~14K rows):
All other allocations out use some combination of Cost Center (or even a rollup level of multiple cost centers), cost pool, IT resource sub-tower, etc.
Now, let’s check how many rows we end up with in the identifier, if instead of using the “raw” Labor ID in the unique identifier column, we use “N/A” in the ~7.5K rows where we don’t need the Labor ID detail.
To do this, we need to check which rows will eventually allocate via the Time Tracking allocation ahead of time, i.e. in the Labor Master Data transform.
A simple Lookup() based on Labor ID into the Time Tracking Master Data table will give us that answer.
Then, we can create a new “Labor ID for TT” column which will be defaulted to “N/A” if no match was found:

Now we can see that the number of rows in the identifier is reduced to ~8.5K, so nearly by half from the original ~14K amount:
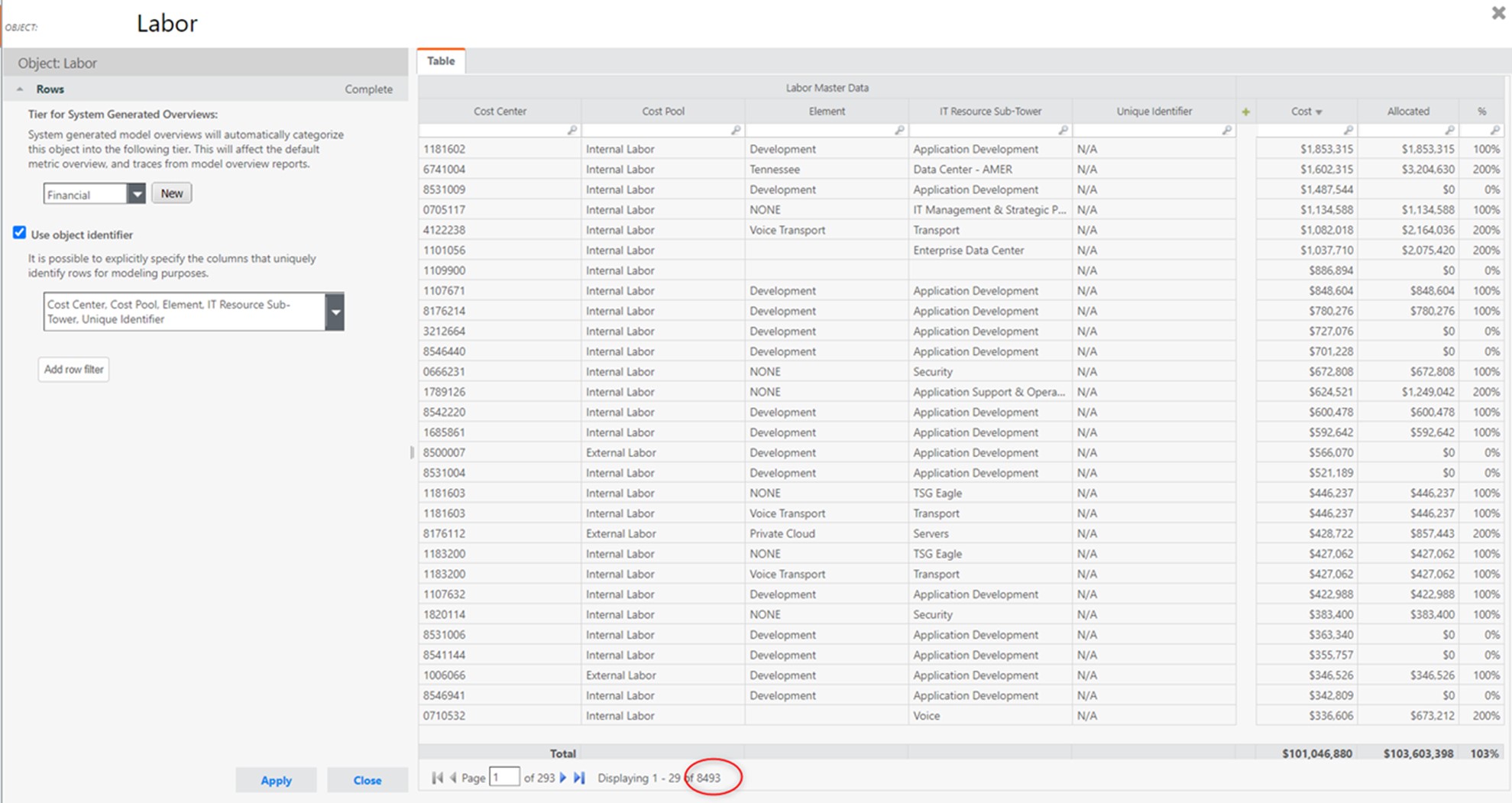
This may seem like "only" a ~40% row count improvement, but the correct way to look at it is to exclude the 6,432 records that allocate via the "Time Tracking" allocation, because those rows remain unchanged.
This means that the remaining 7,917 (= 14,349 - 6,432) rows that we previously had, have now shrunken to only 2,061 (= 8,493 - 6,432), which is a ~75% improvement, and that is very significant.