Co-authored by @Girish Venkatesh
This blog contains the checklist and steps that can be followed regularly as proactive and precautionary measures to maintain system health and to avoid future system issues. Please note that this is not an exhaustive list of steps but a continuously evolving repository depending on multiple scenarios such as new components added or removed to IBM Sterling Integrator (B2Bi) and new use cases implemented. Against each checklist item, we have also mentioned the optimal frequency of implementation in brackets () as weekly/daily/during deployment etc.
Please note that all information provided in this blog is generic . The need and frequency at which it is implemented will further depend on specific project requirements. This blog pertains to findings in B2Bi v6.0.3.2.
This checklist can be used by customers’ in-house teams, Sterling B2B consultants working on client projects as well as those tasked with auditing the health of the system.
1. Ensure all the out-of-box (OOB) schedules are enabled and that they are running at their scheduled increments including External Purge if (daily)
The screenshot below shows the schedules that are enabled (for illustration purposes). Each project can have different sets of OOB schedules that need to be kept active. Please perform due diligence and confirm the schedules to be enabled with Sterling consultants/IBM support.


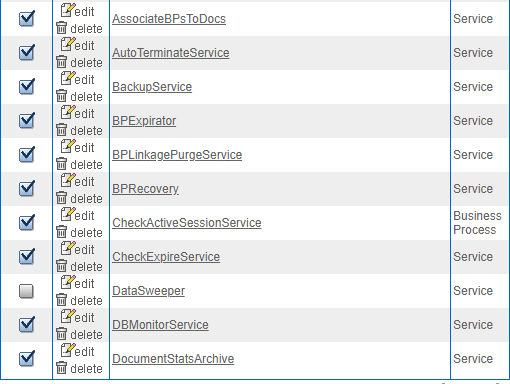
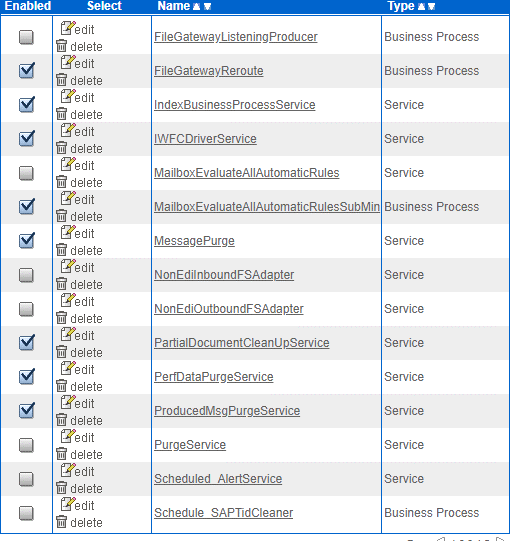
2. Check for external purge: Only one external purge should be running in the cluster on the designated node (The designated node condition is optional and is solution dependent). If you need to shut down the hardware that is running the external purge, then you must run the external purge on a different node. To check if only one node is running the external purge:
-
- First, check for the existence of hpp.purge in the Lock Manager page in the SBI dashboard: Click Operations > Lock Manager >>Search for the purge (hpp.Purge,PURGE_SERVICE)
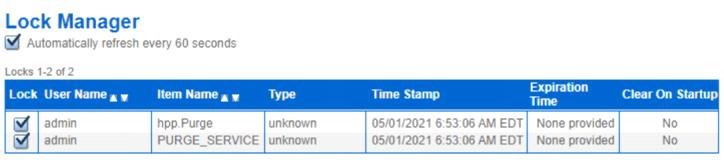
- The above screenshot confirms there is a lock on the purge. To confirm if the external purge process has started, list the operating system processes/services. Look for the external purge process id. Please note that existence of PID does not confirm that external purge is running so all these steps need to be done
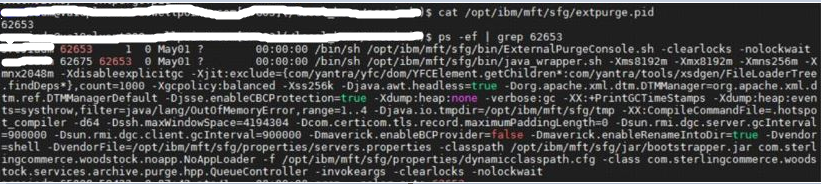
- Look for the external purge log INSTALL/logs/PURGE/extpurge.log and delete SQL statements
-
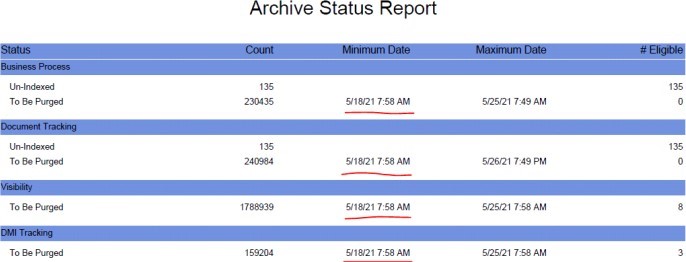
If all the above steps are followed, then you can finally check the DBstats report. Under Archive Status Report, the MIN_ARCHIVEDATE for records eligible for purge should be a recent date based on the archive manager configuration.(The report generation process is resource intensive, so avoid it if the system is already slow or under high load, or if you’re sure (after following the steps above) that the external purge is running)
3. Determine increase in the load (daily)
We can look at the total number of files transferred in the present hour and compare it to what has been observed on an average at the same hour in the past to determine the approximate increase in load.
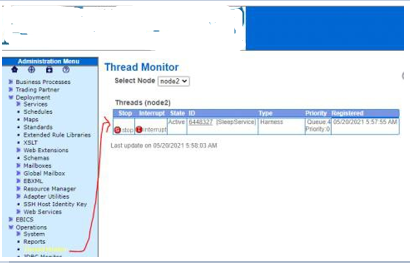
4. Identify long running business processes - Dashboard-> Operations-> Thread Monitor (daily)
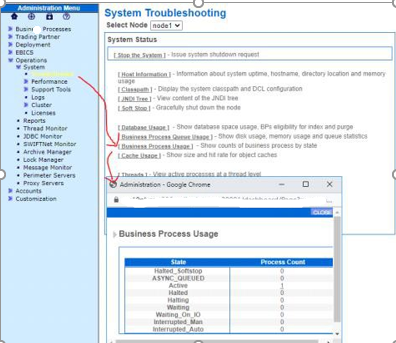
5. Ensure all business processes are moved out and recovered. Review the state of your business processes (daily):
Active,Halted,Halting,Waiting,Waiting On IO, Interrupted Man, Interrupted Auto
Navigate to Administration Menu > Operations > System > Troubleshooter. Select Business Process Usage:
6. Ensure business process life spans are set correctly as per the requirements (during deployment)

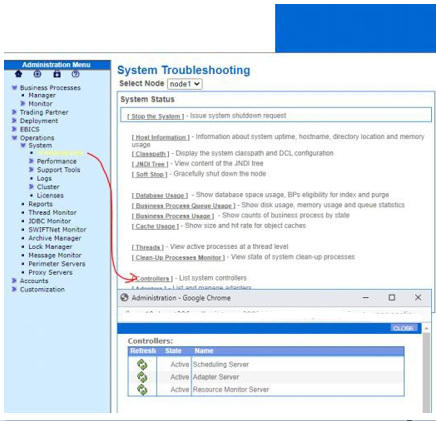
7. Ensure all the necessary controllers are active. (daily)
Navigate to Administration Menu > Operations > System > Troubleshooter. Select Controllers
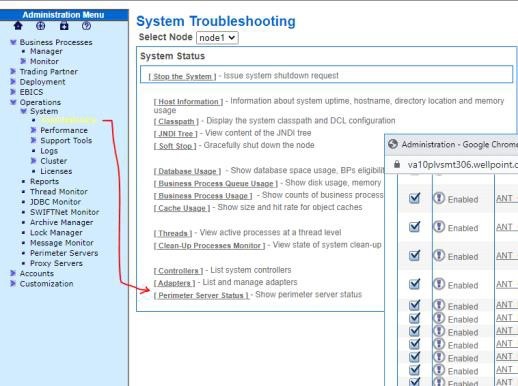
8. Ensure that your adapters are enabled. (daily)
Navigate to Administration Menu > Operations > System > Troubleshooter. Select Adapters.
9. Review the system for a spike in load and ensure that no backlog occurs. Navigate to https://server:port/queueWatcher. (daily)
10. Review logs to check for issues by looking for any of the following: NullPointerException and OutOfMemory (daily)
No specific documentation.
Path for log files:
Sterling B2B integrator/SFG - <sfg install location>/logs
Global mailbox - <sfg install location>/wlp/usr/servers/mailboxui/logs
zookeeper - <Global mailbox pre-requisite install location>/zookeeper/logs
cassandra - <Global mailbox pre-requisite install location>/apache-cassandra/logs
seas - <seas install location>/logs
sspcm - <sspcm install location>/logs
icc - <icc install location>/log
ssp engine - <ssp engine install location>/logs
perimeter server log - <install location of each perimeter server>/ - the log files are of the format PSLogger.*
11. Review logs to check for issues by looking for any of the following: ERROR and other Exceptions. (daily)
This section can be updated as more log messages are identified for different kinds of failures.
No specific documentation but here are some examples:
B2BI's GM component issues can be identified by looking for following in <sfg install>/wlp/usr/servers/mailboxui/logs/messages.log
b. CBXRN0005E: An error occurred while replicating file from replication server ... errorDesc=Source: No such file or directory. Storage bucket could not be found for: payloadId=[...] segmentId=[...] segmentFileName=...]. Check storage
Failure - A storage failure occurred.
c.The following message is logged into log on the Global Mailbox Admin and in MEGLogging.log and globalmailbox.log on Sterling B2B Integrator:
Caused by: com.datastax.driver.core.exceptions.UnavailableException: Not enough replicas available for query at consistency EACH_QUORUM.
Failure - Less than two Cassandra nodes are operating within one of the data centers.
12. Review the system for thread dumps and heap dumps. On Red Hat Linux routinely check for the existence of thread dumps and heap dumps. The presence of these files indicates that there is an issue. If the following files are found, they will need investigation. (daily)
- check for javacore* and hprof*.* files in the <sfg install location>/noapp/bin directory.

13. Review the JDBC pool sizes to ensuring the database does not exceed the maximum size defined in jdbc.properties or system_overrides.propeties (if pool values overriden in performance tuning dashboard) by the *.maxsize setting. (daily)
Navigate to Administration Menu > Operations > System > Troubleshooter. Select Database Usage.

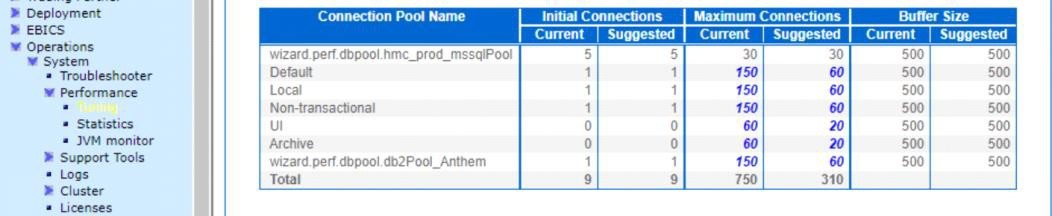
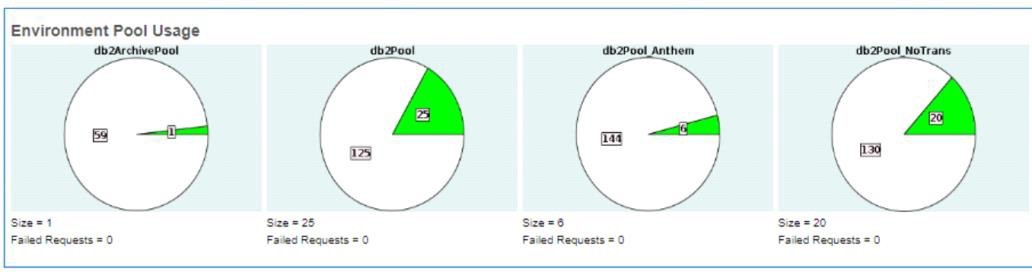
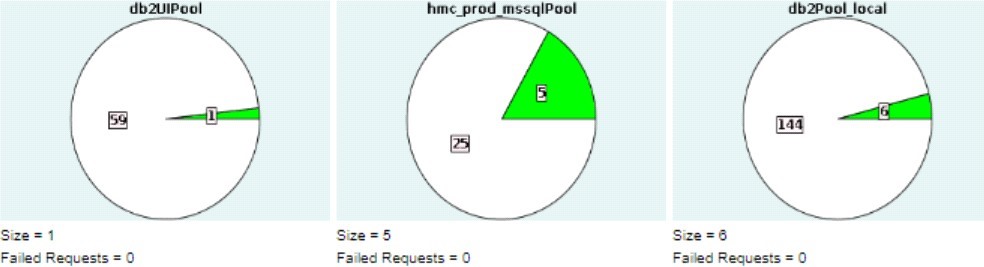
14. Determine potential problems using the Health Check Report. (weekly)
Navigate to http://server:port/healthCheck
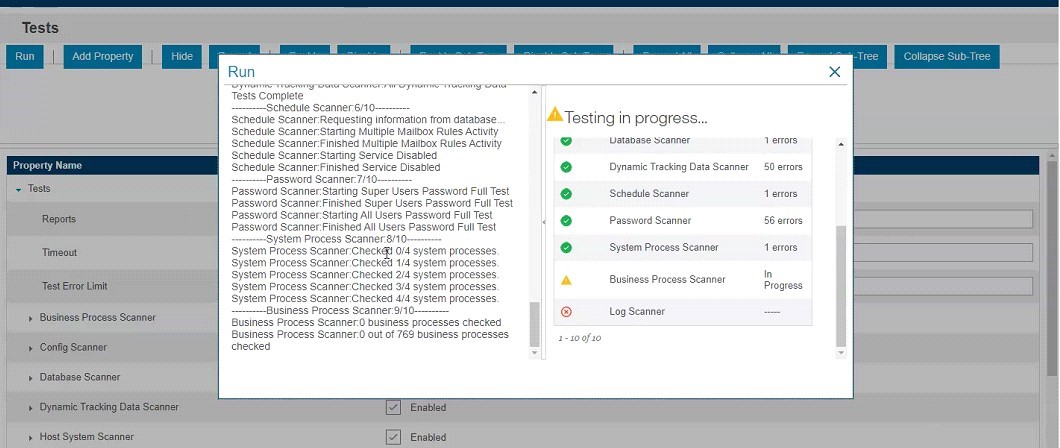
15. Monitor table row counts through DBStats report (with increased load, increased counts are expected) (weekly)
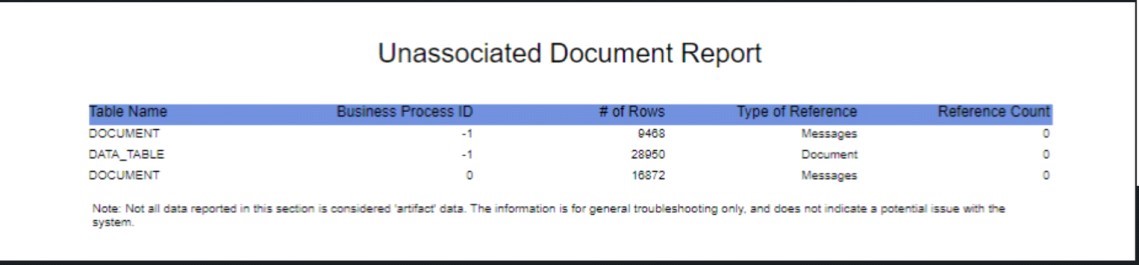
Note: Efficient working of B2Bi is also dependent on the health of the associated database, network, operation system modules and hardware. This blog does not discuss these elements, but it is advisable to keep a check on these components external to B2Bi with the help of cross functional teams.
Therefore, by following the steps listed above at the right time, we can avert major application issues to a great extent.
References:
- IBM Sterling B2B Integrator 6.0.3 - https://www.ibm.com/docs/en/b2b-integrator/6.0.3
- Scheduling - https://www.ibm.com/docs/en/b2b-integrator/6.0.3?topic=integrator-scheduling
- External Purge - https://www.ibm.com/docs/en/b2b-integrator/6.0.3?topic=purge-external
- Monitoring a Business Process Thread - https://www.ibm.com/docs/en/b2b-integrator/6.0.3?topic=operations-monitoring-business-process-thread
- Reviewing System Information - https://www.ibm.com/docs/en/b2b-integrator/6.0.3?topic=operations-reviewing-system-information
- Monitoring Queues using Queue Watcher - https://www.ibm.com/docs/en/b2b-integrator/6.0.3?topic=tuning-monitoring-queues-using-queue-watcher
- HealthCheck Reference - https://www.ibm.com/docs/en/b2b-integrator/6.0.3?topic=reference-healthcheck
#Featured-area-2
#Featured-area-2-home
#DataExchange
#IBMSterlingB2BIntegratorandIBMSterlingFileGatewayDevelopers