This blog describes some basic conceptions and their relationship in IBM Storage Scale Erasure Code Edition (ECE).
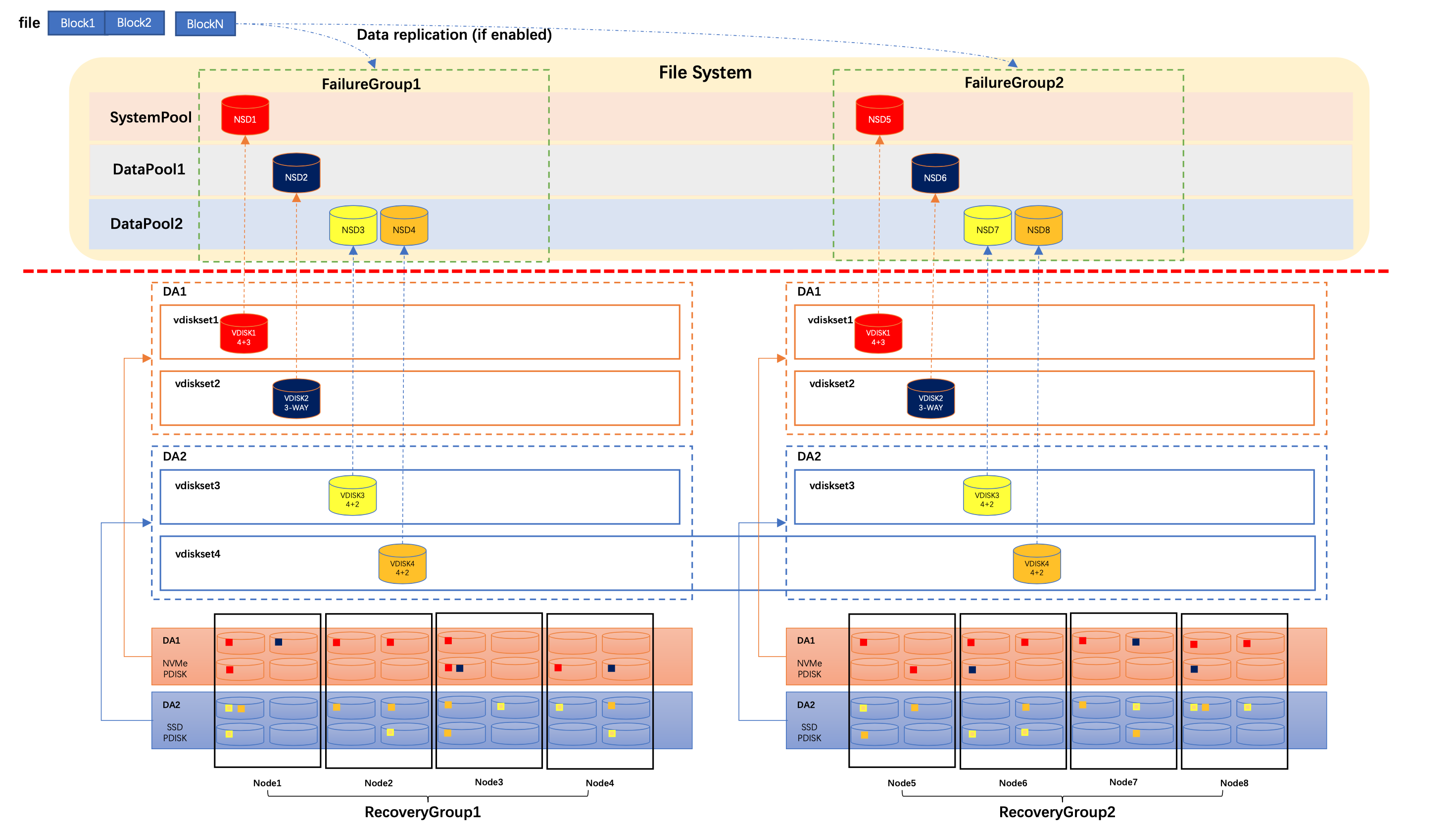
Figure 1: A Storage Scale ECE Cluster Example
This blog uses above cluster as an example to give some more detail explanations about some basic Storage Scale ECE basic conceptions and their relationship.
In this cluster, there are two recovery groups, RecoveryGroup1 and RecoveryGroup2. Each of them has 4 nodes. There are 4 NVMe disk drives and 4 HDD disk drives attached in each node. These NVMe disk drive and HDD disk drive are considered as physical disk (PDISK) in Storage Scale ECE.
When Storage Scale ECE creates recovery group in these storage nodes, it identifies NVMe disk drive and HDD disk drive as different disk type, and put them into different Disk Array (DA). As shown in above example, DA1 has been created for all NVMe disk drives and DA2 has been created for all HDD disk drives. If disk has different characteristic, such as capacity, performance (e.g RPM for HDD), and so on, Storage Scale ECE will put them into different Disk Array as well. For example, if there are two type of HDD with different capacity, 8TiB and 12TiB, in these storage node, Storage Scale ECE will put all 8TiB HDD into a Disk Array, and put 12TiB HDD into another Disk Array.
In these DAs, we can create several VDISKSET with different properties, such as erasure code, capacity and so on. In above cluster, vdiskset1 and vdiskset2 have been created from the NVMe disk array DA1. Vdiskset1 is using 4+3P erasure code and vdiskset2 is using 3Way replication erasure code. If VDISKSET properties are identical, you can also create one VDISKSET across multiple recovery groups. For example vdiskset4 has been created in DA2 across RecoveryGroup1 and RecoveryGroup2. Note that even VDISKSET has been created across multiple recovery groups, but data redundancy is still kept in each recovery group. As show in above example, the data and parity of the yellow VDISK are only saved in PDISKs in each recovery group. It has the same behavior as we create separate VDISKSET in each recovery group. The only different here is that we can use one command to create VDISKSET for multiple recovery groups which is easy for admin to maintain large Storage Scale ECE cluster.
In current implementation, Storage Scale ECE creates two VDISKs in each storage node for each VDISKSET. Due to space limitation, above picture doesn't show this detail information. Storage Scale ECE creates a NSD for each VDISK, and then create GPFS file system with these NSDs.
In GPFS file system layer, we can define storage pool properties in these NSDs. For example, we put the red NSD into GPFS system pool, and put other NSDs into different data storage pools. We can also put NSDs into different failure group, and enable data replication feature in GPFS file system layer to have more data redundancy. It's suggested to put VDISK from the sane recovery group to the same failure group. In large cluster, if there are multiple recovery groups are in the same rack or building, you can also put VDISKs from those rack or building into the same failure group, to build advanced solution, such as Storage Scale stretch cluster.
#infrastructure-highlights