OpenShift (Kubernetes) with its built-in redundancy of resources is designed to be self-resilient against failures of its many components – pods, nodes, APIs etc.. However, there are two shortcomings to the OpenShift resiliency that Fusion squarely addresses.
Resiliency Solutions for Varied Failure Scenarios
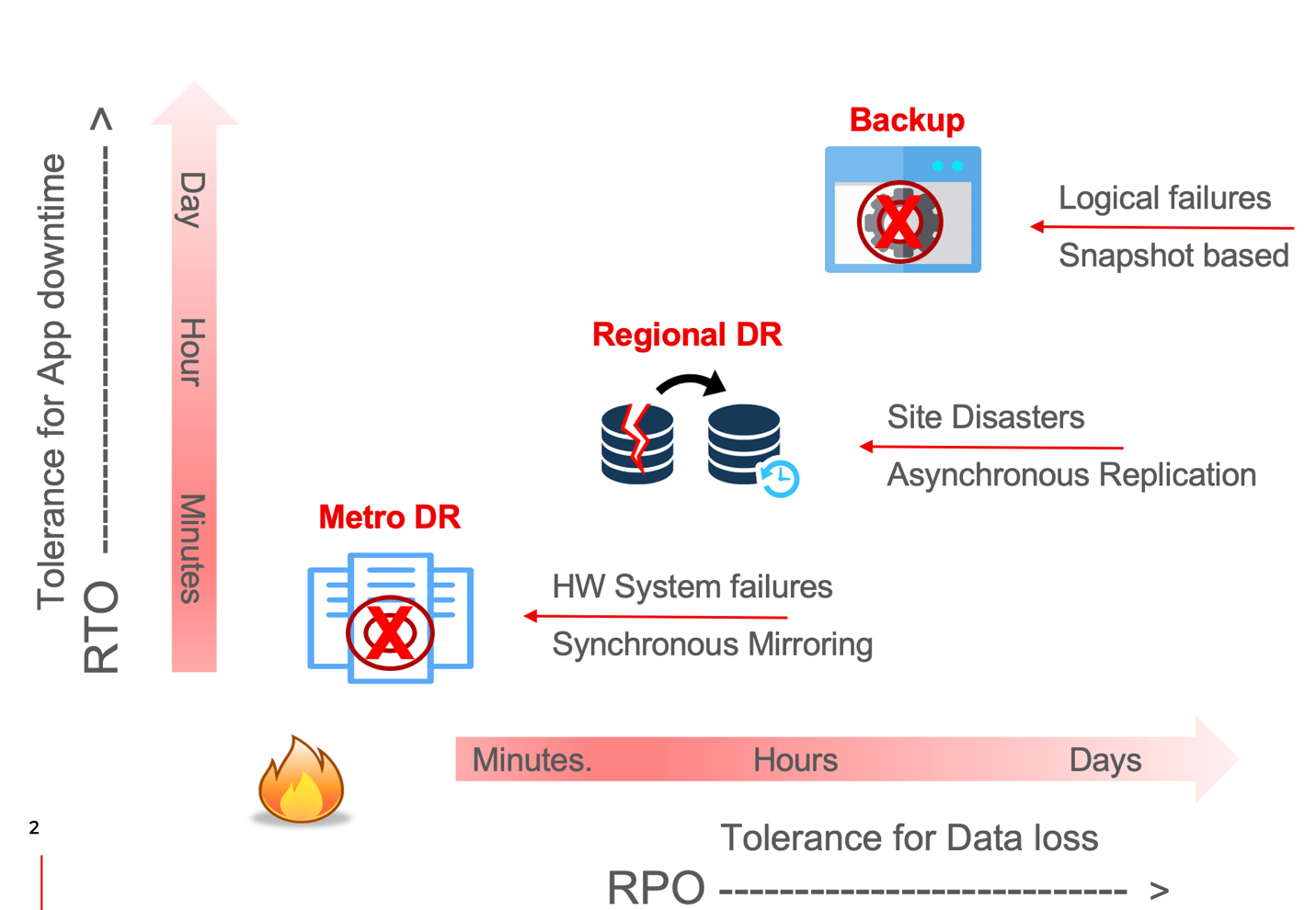
As mentioned earlier Fusion enables application resiliency against a multitude of failure scenarios. Different failure scenarios require different protection schemes. Furthermore, different applications require different SLAs (RPO & RTO) based on their business criticality. Hence, Fusion has designed different resiliency solutions to meet a full spectrum of RPO and RTO requirements, that meet different infrastructure needs and cost restrictions.
High Availability
It is recommended for teams to start their resiliency planning by designing their OpenShift clusters with multi-zone configurations provided by Fusion. This provides protection against infrastructure failures in any single availability zone. Fusion ensures there is application data redundancy and the data copies are affinitized to each failure zone and thus the application is not impacted by any single failure. When these zone-aware data volumes are coupled with similar protection for worker nodes from OpenShift clusters, applications have a complete protection against zone failures. This protection is available for both on-prem and supported cloud platforms and for all data types - block, file, and object storage.
These configurations are simplified with OpenShift IPI installers for Fusion SDS and also with pre-configured appliance with Storage Fusion HCI System. Fusion HCI is available as a three-rack appliance that can be spread across failure domains, and provides a turnkey deployment of OpenShift optimized for availability.
Think of it as three AZs in a box - The public cloud operating model in your private data center.
Backup
For many logical or software failures that are triggered by ransomware attacks, software data corruption, accidental deletions, one must rely on a previous snapshot copy of the application. Recovery is achieved by restoring the application from a backup, whether in the original cluster or in an alternate cluster.
Fusion provides application consistent backup solutions that provide protection for both application data and metadata and are tailored for each application with ‘application recipes’. Because with these solutions the recovery starts after the failure, they tend to be at a higher end of RPO and RTO spectrum.
There are many complexities to an application consistent backup:
There’s a CSI standard for storage providers to be able to provide snapshots of individual persistent volumes. But a containerized application isn’t individual persistent volumes. Real containerized applications can be made of multiple micro services running across multiple namespaces. These applications may use dozens of persistent volumes. The applications also have declared state and dynamic state. Backing up the application means that we have to be able to capture a backup across:
-
The declared state
-
The dynamic state
Fusion Backup & Restore is designed to handle all these complexities in providing an application consistent backup solution.
DR Solutions
Fusion provides dual DR solutions that are designed to protect the applications from external threats that impact clusters. All DR solutions from Fusion are designed for application recovery, which means they not only replicate the application data but also has the means to protect the cluster meta data and Application related Kubernetes Objects. Failover is at the granularity of the application. Fusion provides a set of operators that automate the failover of the application which not only reduces the failover time (lowering the RTO), but also failover success rate by eliminating human errors.
Metro-DR: A unique solution that offers no data loss (RPO=0) protection for clusters deployed across data centers that are connected by low latency networks. This solution is most suitable for applications that cannot afford to lose any data in a DR scenario and can cope with the stringent network and quorum requirements. This solution does not protect applications from large blast radius failures.
Regional-DR: This is the most traditional and flexible DR solution where the data is asynchronously replicated across clusters that can be separated over large distances and connected by WAN networks. While there is a potential data loss due to the asynchronous data replication, this solution protects from the large blast radius geographical data center failures.
Multi-tiered protection with combination of HA, DR and Backup solutions
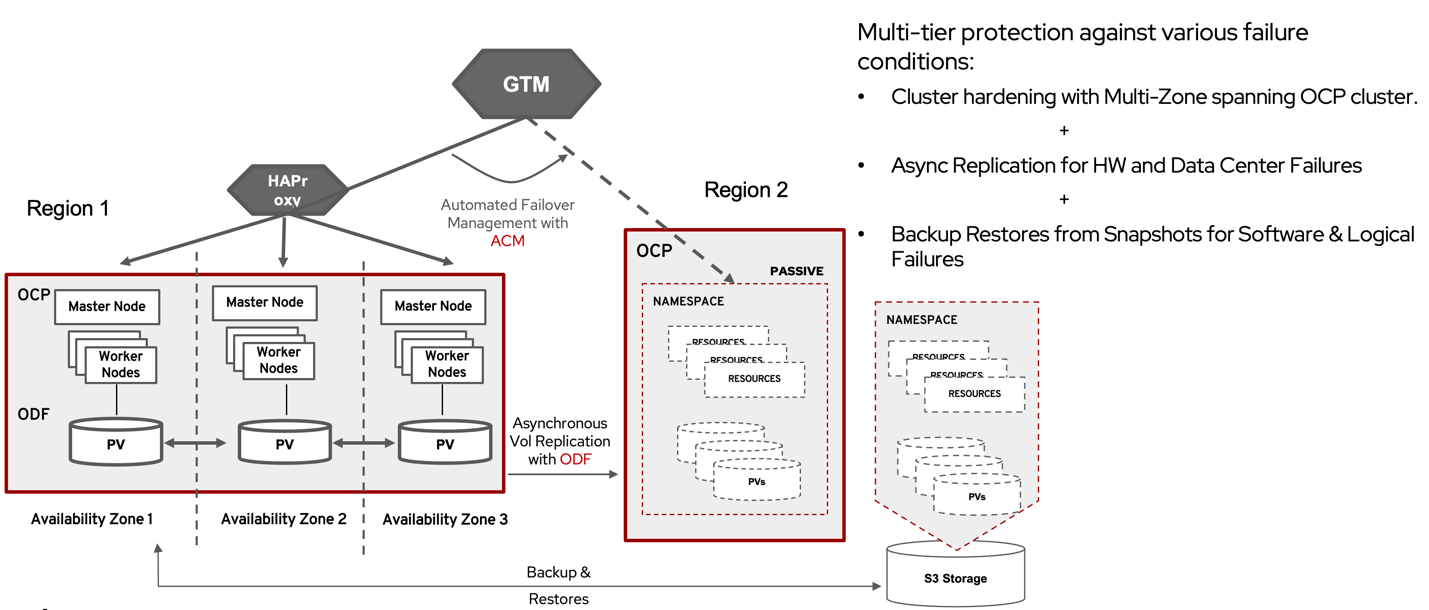
Another key advantage of Fusion-enabled application resiliency is that all of the above categories of solutions are designed to work with each other, providing applications with a powerful and comprehensive protection from multiple failure scenarios and infrastructure requirements. Users can craft their own SLOs for their application by using a combination of High Availability, Backup and DR solutions. For Ex: a cluster can be configured with HA on the primary site to protect against zone or Metro failures, while being configured with Regional-DR to protect against site or region failures, and at the same time applications are backed up - retaining point-in-time application-consistent copies to protect against logical failures.
Summary
OpenShift applications require purposeful resiliency. Due the dynamic nature of Kubernetes, legacy solutions do not work well. Fusion Software is designed to overcome many limitations of these legacy solutions and is purpose built for providing resiliency for stateful applications in OpenShift. Fusion provides comprehensive resiliency solutions for users to choose the right solution that is suited to their application needs and infrastructure dependencies. Solutions range from HA against zonal failures, Metro-DR against small range data center failures, Regional-DR against large blast radius data center failures and backups against any logical or physical system failures. All these solutions are designed to provide a complete application recovery that includes application state and data.
More details on each of these solutions are available in the Fusion documentation.