In order to use Nvidia GPUs in an Openshift 4 cluster on worker nodes, you need to deploy the Special Resource Operator. There are some prerequisites that must be met before the operator can be installed correctly.

Disable nouveau (RHEL worker node only)
If your worker nodes are RHEL76 or later you need to have
nouveau disabled. This step is not required for CoreOS as it is disabled there per default.
Check if it is activated on your system.
lsmod | grep -i nouveau
If you can see values in the output, then you have to manually disable nouveau. You could perform it with 'modprobe -r nouveau' for test purposes, but it will not be persistent (nouveau will be enabled again after reboot). In order to disable nouveau permanently you need to create a file with these 2 lines to blacklist it.
vi /etc/modprobe.d/blacklist-nvidia-nouveau.conf
blacklist nouveau
options nouveau modeset=0
Now, recreate initial ramdisk and reboot your worker node.
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r)-nouveau.img
dracut /boot/initramfs-$(uname -r).img $(uname -r)
reboot
Your system should now have nouveau disabled. You can check with lsmod if it is the case.
Image Registry Operator
Image Registry Operator is responsible for managing images and must have dedicated storage assigned.
You have to check the values defined in spec section of the operator. With the following command you can see them and perform modifications.
oc edit configs.imageregistry.operator.openshift.io
The 'managementState' option should not set to 'Removed'. If it is the case, then you could assign it to 'Managed'. Check if storage is defined.
If you would like to perform initial tests then you could set the storage to emptyDir with
oc patch configs.imageregistry.operator.openshift.io cluster --type merge --patch '{"spec":{"storage":{"emptyDir":{}}}}', but it is not recommended for production environment as the data is not persistent and bound to pod lifetime.
For more information what storage could be used, refer to the official RedHat documentation (here for Openshift version 4.3.0):
https://docs.openshift.com/container-platform/4.3/registry/configuring-registry-operator.html
Node Feature Discovery
You need to install the Node Feature Discovery operator for enabling specific node labels. You can do it via CLI by performing these steps:
git clone https://github.com/openshift/cluster-nfd-operator.git
cd cluster-nfd-operator
make deploy
You can also install it graphically from the Openshift Web Console. As Administrator, go to Operators -> OperatorHub and search for 'Node Feature Discovery'.
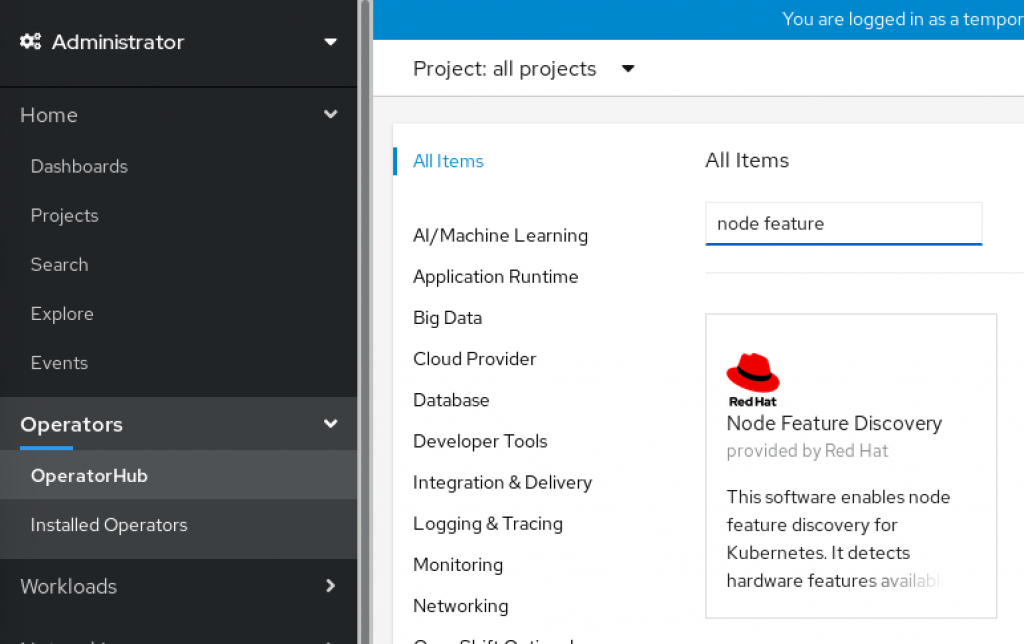
Select the operator and install it in default namespace. Now you are ready to install the Special Resource Operator.
For more information about the Node Feature Discovery, visit its official github repository.
https://github.com/openshift/cluster-nfd-operator
Special Resource Operator
Special Resource Operator will install and set up GPU drivers for Nvidia cards.
Important! Make sure you use the correct github repository URL for SRO which is https://github.com/openshift-psap/special-resource-operator.Clone the repository for the SRO from Github and deploy the operator. Execute these commands.
git clone https://github.com/openshift-psap/special-resource-operator.git
cd special-resource-operator
PULLPOLICY=Always make deploy
You need to wait a couple of minutes for the process to be finished.
Check the state of the operator and nvidia pods which are available in a new namespace openshift-sro. You may switch to it with oc project openshift-sro or if you dont want to, issue all commands with -n openshift-sro flag.
oc get pods -n openshift-sro
All pods should be in running state. A sample output should look as follows (here with 2 worker nodes with Nvidia cards):
oc get pods -n openshift-sro
NAME READY STATUS RESTARTS AGE
nvidia-dcgm-exporter-n88kl 2/2 Running 0 4m1s
nvidia-dcgm-exporter-v7x7h 2/2 Running 0 4m1s
nvidia-device-plugin-daemonset-fggrw 1/1 Running 0 4m38s
nvidia-device-plugin-daemonset-qxjwp 1/1 Running 0 4m38s
nvidia-dp-validation-daemonset-jzjm9 1/1 Running 0 4m18s
nvidia-dp-validation-daemonset-rqtzb 1/1 Running 0 4m18s
nvidia-driver-daemonset-kfb6w 1/1 Running 6 12m
nvidia-driver-daemonset-sjp8h 1/1 Running 6 12m
nvidia-driver-internal-1-build 0/1 Completed 0 17m
nvidia-driver-validation-daemonset-5b7sj 1/1 Running 0 4m54s
nvidia-driver-validation-daemonset-v2drl 1/1 Running 0 4m54s
nvidia-feature-discovery-jv75w 1/1 Running 0 3m33s
nvidia-feature-discovery-mq56x 1/1 Running 0 3m33s
nvidia-grafana-dbc444dd8-6rb9n 1/1 Running 0 3m35s
special-resource-operator-5d46cf8bc4-htwg6 1/1 Running 0 17m
It is also possible to install the SRO from Operator Hub. You can check there for the latest version.

Monitoring on Grafana
After the successful deployment of the SRO you will receive a Grafana pod, which monitors the current workload of your GPUs and provides various other statistics. As Administrator, go to Monitoring -> Routes. Select as project 'openshift-sro'. You will see the URL to the Grafana dashboard.
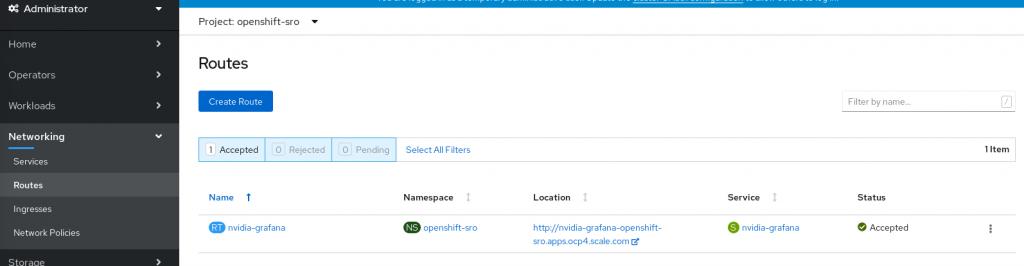
Click on the link. Log in as 'admin' user with password 'admin'. You will be prompted to change the password. Now you can see the dashboard.
Select GPU dashboard. There, you can see statistics related to your cards.
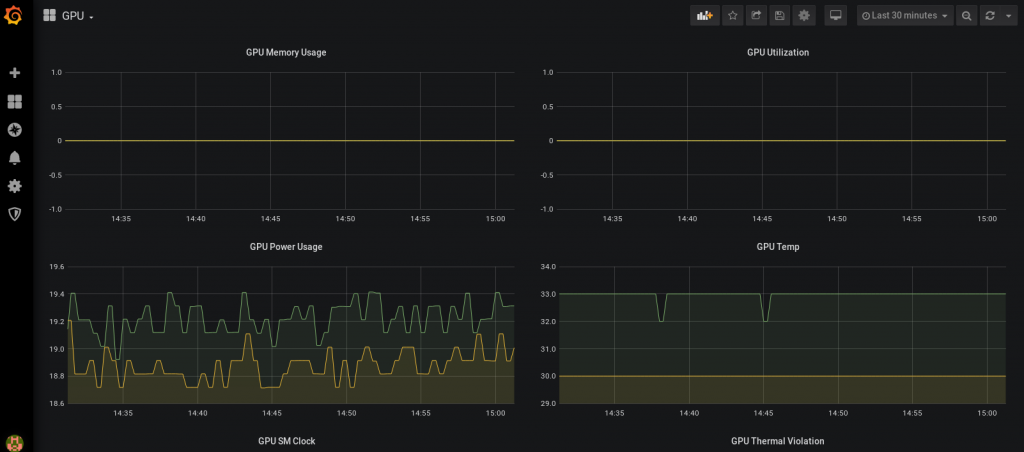
Consider changing the refresh period to analyze the workloads of the GPUs (top right corner).
GPU burn test
In case you would like to test huge workloads, you could try the GPU burn test.
This would show maximum performance but it can be dangerous as it requires a good cooling system on your graphic cards. For more information visit its official website.
https://github.com/openshift-psap/gpu-burnExecute these commands in order to download and run the test.
git clone https://github.com/openshift-psap/gpu-burn.git
cd gpu-burn
oc create -f gpu-burn.yaml
It will create pods which you could observe with oc logs showing current GPU temperature. You could also check on Graphana dashboard how your graphic cards perform.
Troubleshooting
If you would like to undeploy the Special Resource Operator, go to its directory and execute the following command:
make undeploy
Then you can redeploy it again with 'PULLPOLICY=Always make deploy'. This procedure may solve the issues with the SRO so you should give it a try.