Authored by Nils Haustein and Venkateswara R Puvvada
In this blog article we explain how “writable snapshots” can be configured in IBM Storage Scale and how they can be used for different use cases.
Writable snapshots
Snapshots preserve the contents of the file system or independent fileset at a single point of time. Snapshots are space-efficient because the content of the file system is not copied into the snapshot. Instead, snapshots include pointers to the data blocks for each file and directory that are present at the point in time when the snapshot is created.
Snapshots are read-only. Files can be read from the snapshot, but not updated, created, or deleted.
The term “writeable snapshot” refers to the capability to not only read files from the snapshot, but also write, update, and delete files that are allocated in a snapshot, without changing the files in the original file system. Writeable snapshots can be used to clone an entire file system or directory and processes the files that were present at the point of time the snapshot was created.
IBM Storage Scale can provide the capability of “writable snapshots” by leveraging two techniques: Snapshots and Active File Management (AFM) fileset in local update (LU) mode.
Let us explain these functions briefly.
Snapshots
IBM Storage Scale allows to create snapshots for an entire file system or an independent fileset. An independent fileset is a directory in the file system. Snapshots are space-efficient and read-only, as explained above.
The snapshot includes pointers to the data blocks of all files and directories that were present in the file system or fileset at the point in time when the snapshot was created. When a file is read from the snapshot, then the pointers in the snapshot are used to locate and read the snapped data blocks of the file. The snapped data blocks are the blocks the file allocated at the point of time the snapshot was created.
Active File Management Local Update mode
Active File Management allows sharing of files with other clusters or file systems. AFM is based on a home – cache relationship. Home is the storage area where files are located. Cache connects to home via AFM and shows the files located in home storage. However, the content of the files is not present in cache initially. The cache storage just reflects the inodes for each file and directory located in home storage. Upon access, riles are copied (fetched) from home into cache automatically and synchronously. Files can also be copied (pre-fetched) in advance by using the mmafmctl prefetch command.
The connection between cache and home can be realized using the NFS or GPFS protocols (GPFS remote mount). A cache is an AFM fileset representing a directory in a file system. Home is a file system, fileset or directory that is different from the AFM cache. Home and cache are usually configured in different IBM Storage Scale clusters. However, both cache and home can also be configured in the same cluster on distinct file systems.
There are different operational modes provided with AFM. The mode relevant for “writable snapshots” is the local-update mode (LU). After creating an AFM relationship in LU mode, the cache fileset shows all files that are present in home. Files are automatically fetched into the cache fileset upon access. Files that are created, updated, or deleted are not replicated back to home.
An AFM cache fileset configured in local-update mode with its home on a snapshot can be used as “writable-snapshot”.
Configuring “writable snapshots” in IBM Storage Scale
Writable snapshots in IBM Storage Scale rely on the two techniques explained above: Snapshots and AFM LU filesets.
The picture below shows the required components to implement “writable snapshots” and how they interact:
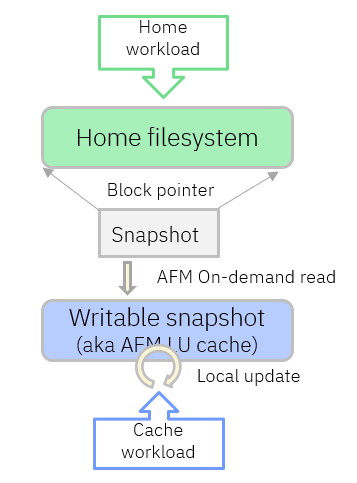
The home file system is where the primary workload and files live. A snapshot can be created in the home file system or in an independent fileset of the home file system. The snapshot is space-efficient and read-only.
The “writable snapshot” is created as AFM LU cache fileset in a different file system. This cache file system can be in the same IBM Storage Scale cluster or in a different one. The AFM LU cache is connected to the snapshot of the home file system via NFS or GPFS protocols (GPFS remote mount). If the AFM LU cache is in the same cluster as the home file system, then using the GPFS protocol is most appropriate. When using the NFS protocol as AFM transport mechanism, then the snapshot path must be exported as NFS export (read-only).
After the “writable snapshot” was created, all files and directories are shown in the AFM LU fileset (cache). The data blocks of the files are still located in the home file system. When the cache workload reads a file, then the file is fetched from the snapshot on home and stored in the cache fileset. When the cache workload creates new files or updates an existing file, then the new or updated files are stored in the AFM LU fileset. When files in the AFM LU fileset are deleted, then they are only deleted in this AFM LU fileset and not in the snapshot.
With this functionality “writeable snapshots” can be used for various use cases.
Use cases with “writable snapshots” in IBM Storage Scale
AFM DR testing
AFM DR provides a disaster recovery function with two IBM Storage Scale clusters. One cluster is configured as primary, the other cluster is configured as secondary. The primary cluster includes the AFM DR primary fileset that is connected to the secondary fileset provided by the secondary cluster. The content of the primary AFM DR fileset is asynchronously replicated to the secondary fileset.
The primary cluster is active, the secondary cluster is standby. Files being created, update, or deleted on the primary AFM DR fileset are asynchronously replicated to the secondary fileset. The secondary fileset is read-only.
AFM DR optionally provides peer-snapshots. A peer-snapshot is created on the primary AFM DR fileset and promoted in block order to the secondary fileset. Consequently, the peer snapshot functionality creates two snapshots, one in the primary and one in the secondary fileset that include the same data, but the snapshots are created at different point of time. The creation of peer-snapshots can also be automated leveraging the RPO feature (recovery point objective) in AFM. RPO is an AFM parameter that is expressed in minutes. If RPO is set to 60 minutes, then AFM automatically creates peer-snapshots in 60 minutes intervals.
AFM DR also provides easy ways for failing over from primary to secondary and failing back to the old primary. These functions however are not important in the context of “writable snapshots”.
One common requirement for AFM DR is to facilitate DR testing. With DR testing the data that is available at a single point of time is used for testing, while the primary cluster continues to serve the workloads. AFM DR with peer snapshots in combination with “writable snapshots” can be used for DR testing.
How DR testing works
AFM DR testing is conducted on the secondary cluster using a “writable snapshot”. For this purpose, an AFM gateway node must be configured on one or more nodes in the secondary cluster by using the IBM Storage Scale command: mmchnode --gateway -N nodename
The AFM DR testing is illustrated in the picture below and subsequently explained step-by-step:
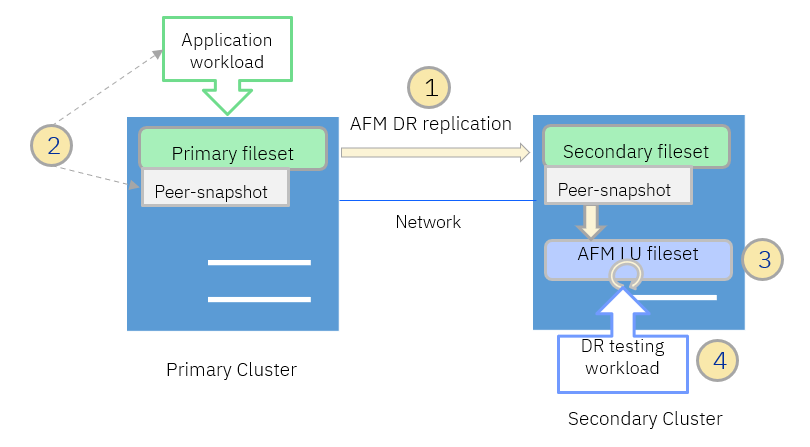
As shown in the picture above, there is a primary and secondary cluster with primary and secondary AFM DR filesets respectively. The application workload uses the primary fileset and all files and directories are replicated from the primary to the secondary fileset asynchronously. The steps to create and use a “writable snapshot” in the secondary cluster for DR testing are as follows:
- The AFM relationship between primary and secondary is active and files are asynchronously replicated from primary fileset to the secondary fileset.
- An application consistent peer-snapshot is created on the primary fileset.
- Once the snapshot peer was created on the secondary, an AFM LU fileset is created on the secondary using the peer-snapshot as target. The AFM LU fileset represents a “writable snapshot”. Preferably, the AFM LU fileset is created on a different filesystem to decouple the replication workload from the DR testing workload in the secondary cluster.
- Once the AFM LU fileset was created and linked, the DR test can be conducted on the “writable snapshot” represented by the AFM LU fileset on the secondary.
When the DR test completed, the AFM LU fileset can be unlinked and deleted. The process can be restarted for the next AFM DR testing scenario.
As shown above, performing DR testing with AFM DR using “writable snapshots” is simple and efficient:
- There is no impact to the application workload on the primary cluster because the data used for DR testing resides in the secondary system.
- “Writable snapshots” do not change any files in the primary or secondary AFM DR filesets.
- Peer-snapshots can be created application consistent. For example, if the application is a database, then the database can be suspended on the primary cluster, and the peer-snapshot can be triggered. This consistent snapshot is then used as “writable snapshot” on the secondary cluster.
- There is some impact for the replication workload on the secondary cluster. This impact can be limited by using a separate files system for the “writable snapshot” in the secondary cluster.
Let’s move on the next use case.
Work with database clones
With “writable snapshots” databases can be cloned and used independently from the original database. The cloned database reflects the original database inventory at a single point in time and can be updated.
To create “writable snapshot” on an AFM LU fileset an AFM gateway node must be configured on one or more nodes in the cluster by using the IBM Storage Scale command: mmchnode --gateway -N nodename
Database cloning using “writable snapshots” is illustrated in the picture below and explained subsequently:
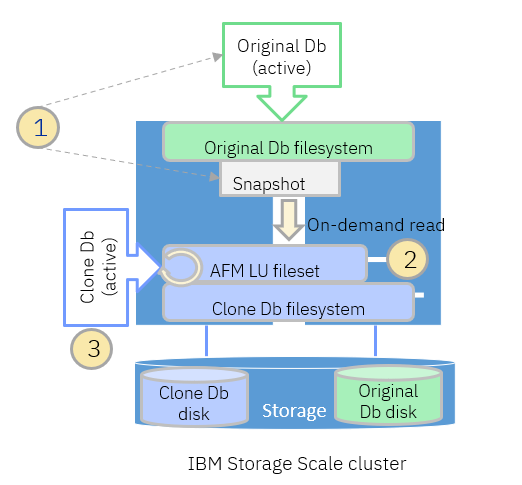
As shown in the picture above, the original database runs on the original Db file system. There is another file system in the cluster (clone Db filesystem) for the “writable snapshot” used by the cloned database. Both file systems use different disk. The steps to create a “writable snapshot” in for the cloned database are as follows:
- Create an application consistent snapshot in the original Db file system, for example by suspending the original database, creating a snapshot in the original Db file system, and resuming the original database.
- Create and link an AFM LU fileset in the clone Db file system using the path of the original Db snapshot as target. The AFM LU fileset represents a “writable snapshot”.
- Start the cloned database using the data in the “writable snapshot”.
When the processing of the cloned database completed, the AFM LU fileset can be unlinked and deleted. The process can be restarted for the cloned database processing.
As shown above, performing database cloning on a “writable snapshot” is simple. There are a few things to consider:
- After resuming the original database in step 1, the performance of the original database may degrade. This is because the database will start updating blocks that need to be copied or redirected in the snapshot.
- After starting the cloned database, additional workload will be seen on the original Db file system potentially impacting the original database performance. This is because the cloned database will read files from the snapshot that are still located in the original Db file system. Once most files are read from the original Db file system into the “writable snapshot”, the original database performance stabilizes because the cloned database will read from the clone Db file system.
- After starting the cloned database, the resource utilization (CPU, memory) may increase in the cluster because many files must be read from the original Db file system into the “writable snapshot”.
Some of the performance impacts and resource utilization challenges mentioned above can be mitigated by running the cloned database in a remote cluster. Thereby, the AFM LU fileset is created over an NFS or GPFS cross-cluster mount from the remote cluster to the snapshot of the original Db file system.
#Highlights#Highlights-home