Backups have come a long way since a 8mm tape drives stuck directly in the front of a server with one tape per day of the week. Having an offline copy of your data in a fireproof data vault is a reassuring thought. In the modern datacenters we use either physical tape libraries or virtual tape libraries. A new arrival is the use of object storage as a method of saving files in either the public cloud, like AWS storage or IBM Cloud storage, or in a private cloud with a solution like IBM Cloud Object Storage.
In Spectrum Scale we can use object stores in two ways; We can use something called Transparent Cloud Tiering (tct), where an object store is integrated into the filesystem as an external data pool, and we can create policies to migrate the data part of files to the cloud, and recall transparently. This is really nice, but not suitable for out home NAS solution, as it requires RedHat Enterprise linux, and we're running Ubuntu.
So, we'll be using the AFM to Cloud Object Storage (afm2cos) functionality, which builds one the fundamentals of Automated File Management, which created a special fileset in the filesystem that is a representation of a "home" or source fileset. The representation includes all metadata, which is recreated (filenames, permission etc) but the data (content) of the files is optional. If you access the file, the content will be transparently recalled, and if your fileset becomes full, the file content will be dynamically evicted (removed).
OK, so let's configure AFM first, then we'll create an account in the IBM Cloud, create an object store, and finally am afm2cos fileset that stores all its data there.
Configuring AFM is just this command, you have to appoint your system as a gateway. In large environments these gateways are dedicated servers, but we can get away with assigning this functionality to our home NAS server:
mmchnode --gateway -N `hostname`
Next, you need an IBM ID, go to: https://cloud.ibm.com/login
And click on "Create an account" if you do already have one. Otherwise, log in to the IBM Cloud to use your free "Lite" account, no credit card required.
On the Cloud web interface, click on "Create a resource" and search for "Object storage", you should see the following panel:

Create your Object store, and give it a nice name, like "COS AFM Spectrum Scale Storage". You now have 25GiB of free Object Storage! Check for your storage in the resources list (may need a refresh). Next we need to know the URL, and we need credentials. Select your storage and you can see the options you need in the left pane: Buckets, Endpoints and Service Credentials.
We'll create a bucket first, this can also be done by Spectrum Scale, but we have some cool options here. Name your bucket something meaningful, and select Regional and as we need some performance, select the location nearest to you. Note the region name, we need that to find the Endpoint URL.
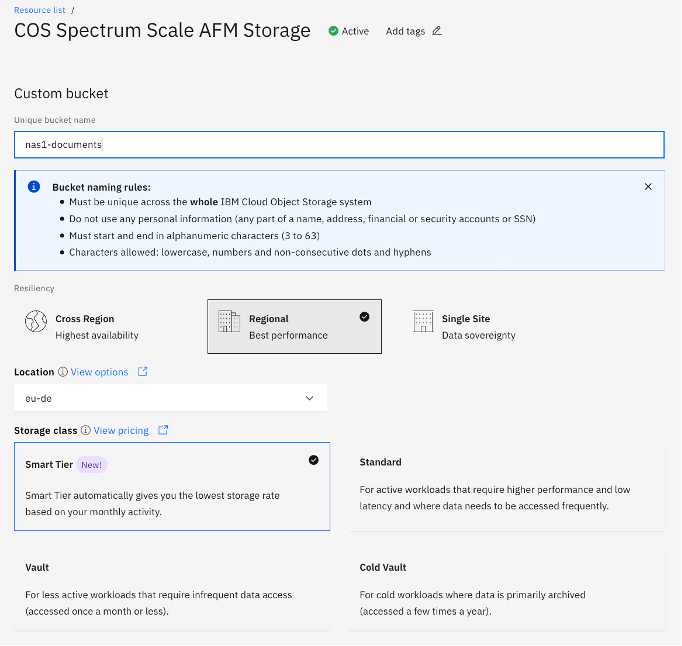
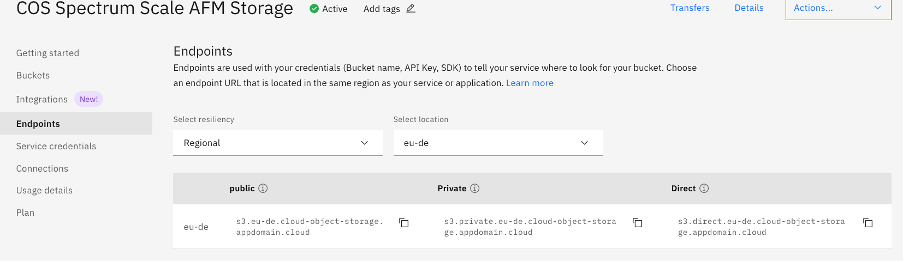
Go to the endpoints option, and select "Regional" and your Location. Now you have to copy the public endpoint URL.
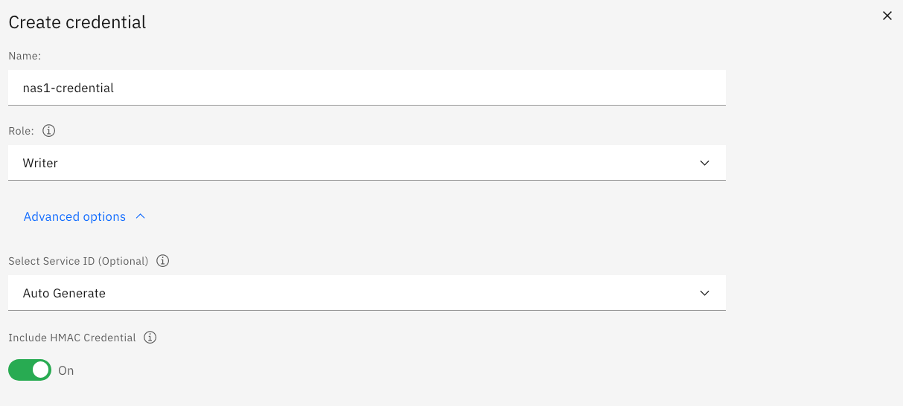
Lastly we need an access key (username) and secret key (password) to access our object store, and therefore our bucket. In the "Service Credentials" screen you can create a new user that Scale will use to connect to the Object Store. I called mine "nas1-credential". Make sure you enable the HMAC credential option!
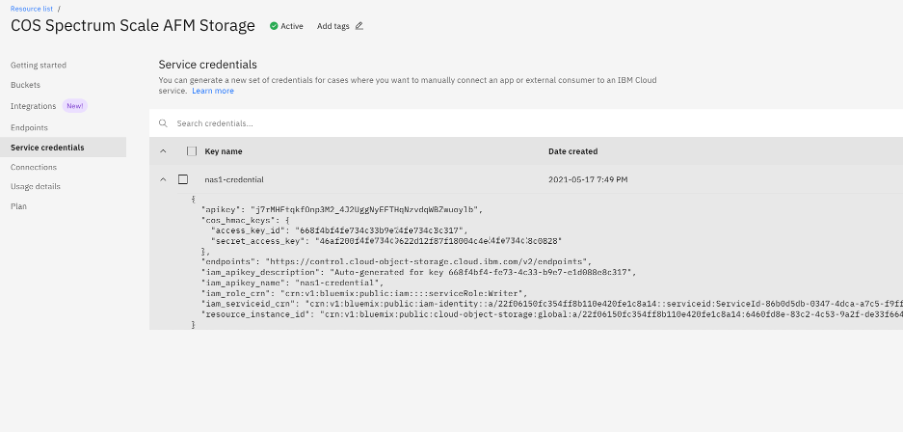
Now, if you look at the Service credential details, you can see the access key_id and secret_access_key. Copy those, and keep them secret!
Now the store is ready and we can configure Spectrum Scale. Log in as root and define the access and secret key using the mmafmcoskeys command for your bucket:
# mmafmcoskeys nas1-documents set 668f4bf4fe734c33b9e4fe734c338c317 46af200f364fe734c33d12f87f1804fe734c33ec88c0828
Spectrum Scale now knows what credentials belong to that particular bucket. We can now create an AFM fileset with that bucket name and all cloud information:
mmafmcosconfig nas1 cloud-documents --endpoint https://s3.eu-de.cloud-object-storage.appdomain.cloud:443 --bucket nas1-documents --mode iw
That's it! You now have an AFM fileset to transparently sends all file data to the cloud, and can recall data if it needs to. Let's see how that works. You can list the filesets with mmlsfileset:
# mmlsfileset nas1 -L
Filesets in file system 'nas1':
Name Id RootInode ParentId Created InodeSpace MaxInodes AllocInodes
root 0 3 -- Mon Apr 12 18:03:44 2021 0 66560 66560
Documents 1 4042 0 Tue Apr 13 09:06:55 2021 0 0 0
cloud-documents 2 131075 0 Mon May 17 20:22:36 2021 1 100352 100352
If you want to see all details, you can specify the --afm and -L option together:
# mmlsfileset nas1 cloud-documents --afm -L
Attributes for fileset cloud-documents:
=======================================
Status Linked
Path /nas1/cloud-documents
Id 3
Root inode 131075
Parent Id 0
Created Mon May 17 20:22:36 2021
Comment
Inode space 1
Maximum number of inodes 100352
Allocated inodes 100352
Permission change flag chmodAndSetacl
afm-associated Yes
Target https://s3.eu-de.cloud-object-storage.appdomain.cloud:443/nas1-documents
Mode independent-writer
File Lookup Refresh Interval disable
File Open Refresh Interval disable
Dir Lookup Refresh Interval disable
Dir Open Refresh Interval disable
Async Delay 15 (default)
Last pSnapId 0
Display Home Snapshots no
Parallel Read Chunk Size 0
Number of Gateway Flush Threads 4
Prefetch Threshold 0 (default)
Eviction Enabled yes (default)
Parallel Write Chunk Size 0
IO Flags 0x400000 (afmSkipHomeRefresh)
As nas1-documents an AFM fileset we can see the status with mmafmctl. The status can be Inactive, Active, or Dirty, meaning nothing transferred yet, some files transferred, and some files need transferring. Let's create some files for testing and see what happens.
# mmafmctl nas1 getstate
Fileset Name Fileset Target Cache State Gateway Node Queue Length Queue numExec
------------ -------------- ------------- ------------ ------------ -------------
cloud-documents https://s3.eu-de.cloud-object-storage.appdomain.cloud:443/nas1-documents Inactive
# head -c 10M /dev/zero > /nas1/cloud-documents/file1
# head -c 10M /dev/zero > /nas1/cloud-documents/file2
# head -c 10M /dev/zero > /nas1/cloud-documents/file3
# mmafmctl nas1 getstate
Fileset Name Fileset Target Cache State Gateway Node Queue Length Queue numExec
------------ -------------- ------------- ------------ ------------ -------------
cloud-documents https://s3.eu-de.cloud-object-storage.appdomain.cloud:443/nas1-documents Dirty scalenode1 3 0
Check on the cloud in the Bucket, under objects:

The Status should auotmaytically become Active after the uploads finish.
# mmafmctl nas1 getstate
Fileset Name Fileset Target Cache State Gateway Node Queue Length Queue numExec
------------ -------------- ------------- ------------ ------------ -------------
cloud-documents https://s3.eu-de.cloud-object-storage.appdomain.cloud:443/nas1-documents Active scalenode1 0 3
The default behaviour of an afm2cos fileset is to only "know" the files it puts there itself, and to not delete any objects (files) in the bucket, but it can overwrite them. This approach means we do not need to check the content of the bucket to have a idea what's in there, we assume we already know. If it is out of sync, you can run the mmafmcosctl command like so:
# mmafmcosctl nas1 cloud-documents /nas1/cloud-documents download --all --metadata
# mmafmcosctl nas1 cloud-documents /nas1/cloud-documents upload --all
You can have a more remote filesystem like behaviour, but this comes at the cost of checking the content of the bucket and that slows filesystem access down and causes more LIST requests to the object store, of which you have a limited free amount. Create a new afm2cos fileset with the --object-fs to try it, we'll automatically create the bucket this time using the --new-bucket option.
# mmafmcoskeys nas1-ibmcloud set 668f4bf4fe734c33b9e4fe734c338c317 46af200f34fe734c3312f87f18004fe734c3388c0828
# mmafmcosconfig nas1 ibmcloud --endpoint https://s3.eu-de.cloud-object-storage.appdomain.cloud:443 --new-bucket nas1-ibmcloud --mode iw --object-fs
If you want to remove the fileset again, you'll need to unlink (unmount) it, and then delete it with the force (-f) option. This does not delete the objects in the bucket.
mmunlinkfileset nas1 ibmcloud
Fileset ibmcloud unlinked
# mmdelfileset nas1 ibmcloud -f
mmdelfileset nas1 ibmcloud -f
Checking fileset ...
Checking fileset complete.
Deleting user files ...
100.00 % complete on Fri Jun 4 17:40:20 2021 ( 100352 inodes with total 392 MB data processed)
Deleting fileset ...
Fileset ibmcloud deleted.
Enjoy using the cloud to store your important files. Next blog we'll talk a little about troubleshooting Spectrum Scale: Part 7: Maintenance and Troubleshooting
#Highlights#Highlights-home