TPC-DS Benchmark using Trino with IBM Storage Ceph Object Storage S3-select
In this Article, we analyze the results of performance benchmarks conducted on Trino with IBM Storage Ceph Object S3-select feature enabled, using TPC-DS benchmark queries at 1TB and 3TB scale. We demonstrate that, on average, queries run 2.5X faster. In some cases, we achieved nine times improvements with a network data processing reduction of 144TB compared to using Trino without the S3-select feature enabled. Combining IBM Storage Ceph(S3-Select) with Trino/Presto can enhance data lake performance, reduce costs, and simplify data access for organizations.
I would like to thank Gal Salomon and Tim Wilkinson for conducting the TPC-DS benchmarking and providing us with these results.

Introduction
What is Trino?
Trino is a distributed SQL query engine that allows users to query data from multiple sources using a single SQL statement. It provides data warehouse-like capabilities directly on the data lake.
What is the difference between Trino, Presto and PrestoDB?
You may have heard references to Trino, Presto, PrestoDB, all of which originated from the same project. Presto was the initial project from Facebook, which was open-sourced in 2013. PrestoSQL became a community-based open-source project in 2018 and was rebranded to Trino in 2020.
Presto is a critical component of the IBM WatsonX.Data offering, and serves as an essential tool for data engineers who require a fast query engine for their higher-level BI tools.
Why choose IBM Storage Ceph for S3 Object Storage?
IBM Storage Ceph provides a first-class, highly compatible S3 API for on-premises deployments.
IBM Storage Ceph confidently meets the needs of critical large-scale installations and the ever-growing demand for data. Its performance scales alongside capacity, resulting in substantial cost savings and the ability to manage exponential data growth.
IBM Storage Ceph offers first-class mission-critical support, exceeding enterprise SLA’s requirements with the IBM Level 2 support team's direct access to the engineers who write the code.

What enhancements does IBM Storage Ceph bring to data query tools like Trino, Presto?
IBM Storage Ceph provides the S3 API S3-select feature. S3-select significantly improves the efficient SQL processing of data stored in Object Storage. By pushing the query down to the IBM Storage Ceph cluster, S3-select can dramatically enhance performance, processing queries faster and minimising resource costs(Network/CPU). S3 Select and Trino are horizontally scalable, allowing you to handle increasing data volumes and user queries without sacrificing performance. Trino's support for SQL and S3 Select's ability to query data in place enables users to access and analyze data without dealing with complex data movement or transformation tasks.
IBM Storage Ceph Object Datacenter-Data-Delivery Network (D3N) feature uses high-speed storage such as NVMe flash or DRAM to cache datasets on the access side. D3N improves the performance of big-data jobs running in analysis clusters by speeding up recurring reads from the data lake or lakehouse.
TPC-DS benchmarks IBM Storage Ceph + Trino
Test Procedure
We executed the following 72 TPC-DS queries at three different scale factors, 1TB, 2TB and 3TB, to characterize performance and resource consumption. The datasets were in uncompressed CSV format. We executed each query numerous times with and without S3-select and ensured consistent results by monitoring the standard deviations for each run.
If you’re interested in exploring this topic further, please check out Gal’s Salomon GitHub repository; where you will find instructions on how to set up a testing environment with Trino and IBM Storage Ceph; additionally, instructions are available on the TPC-DS benchmarking tools used for this benchmark.
Test Environment.
The hardware used for the benchmark was the following:
-
-
3x Dell R630 MON/MGR nodes
-
8x Supermicro 6048R OSD/RGW nodes
-
192x OSDs (bluestore): 24 2TB HDD and 2x 800G NVMe for WAL/DB per OSD
Tuneables
The s3select settings adjusted for optimal configuration:
-
hive.max-split-size - The largest size of a single file section assigned to a worker. More minor splits result in more parallelism and thus can decrease latency, have more overhead, and increase load on the system. Testing started with 4,8,16,32,64,128MB but eventually settled on 128MB for all tests.
-
hive.max-splits-per-second - The maximum number of splits/sec generated per table scan. It can be used to reduce the load on the storage system. There’s no limit by default, so Trino maximizes the parallelization of data access. All testing was performed using 10K for this setting.
Concurrency
The Trino engine processes complex queries by “breaking” the original query into multiple parallel s3select-requests; these requests split the requested table(an S3 object) into equal ranges, then distributed across our Ceph cluster by the load balancer. The load balancer efficiently channels requests among all the configured Ceph Object Gateways, ensuring optimal performance and scalability for our data processing needs.
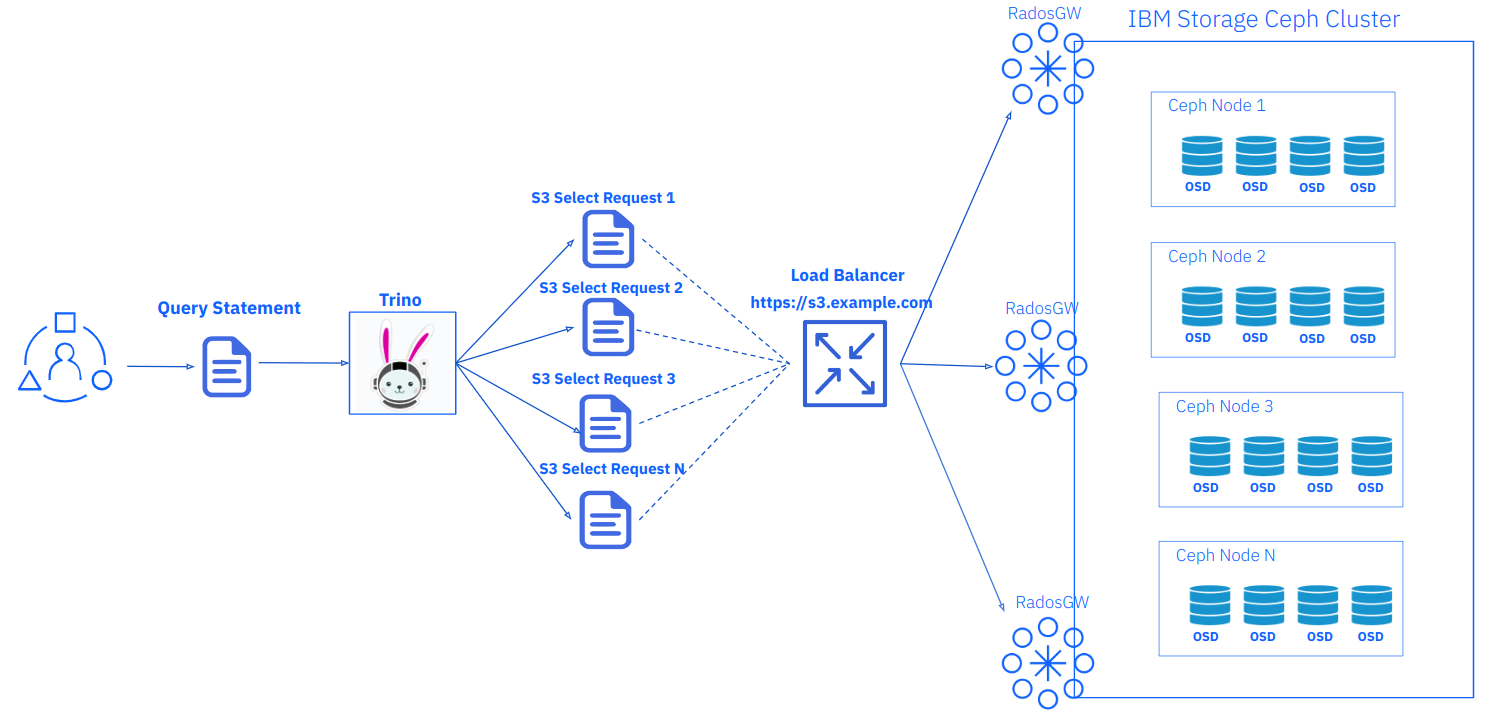
Test Results
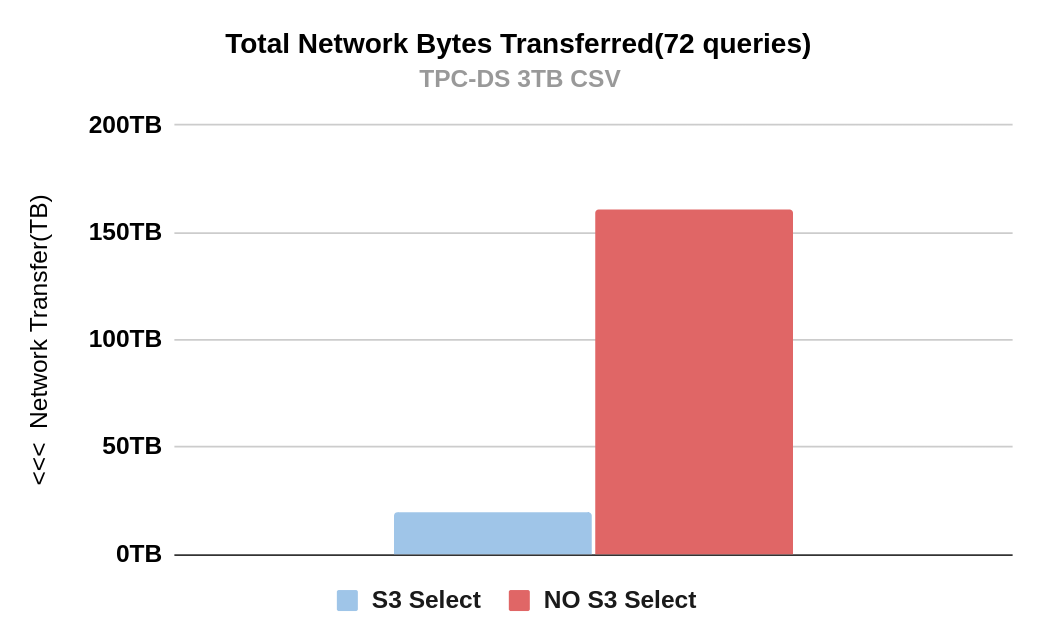
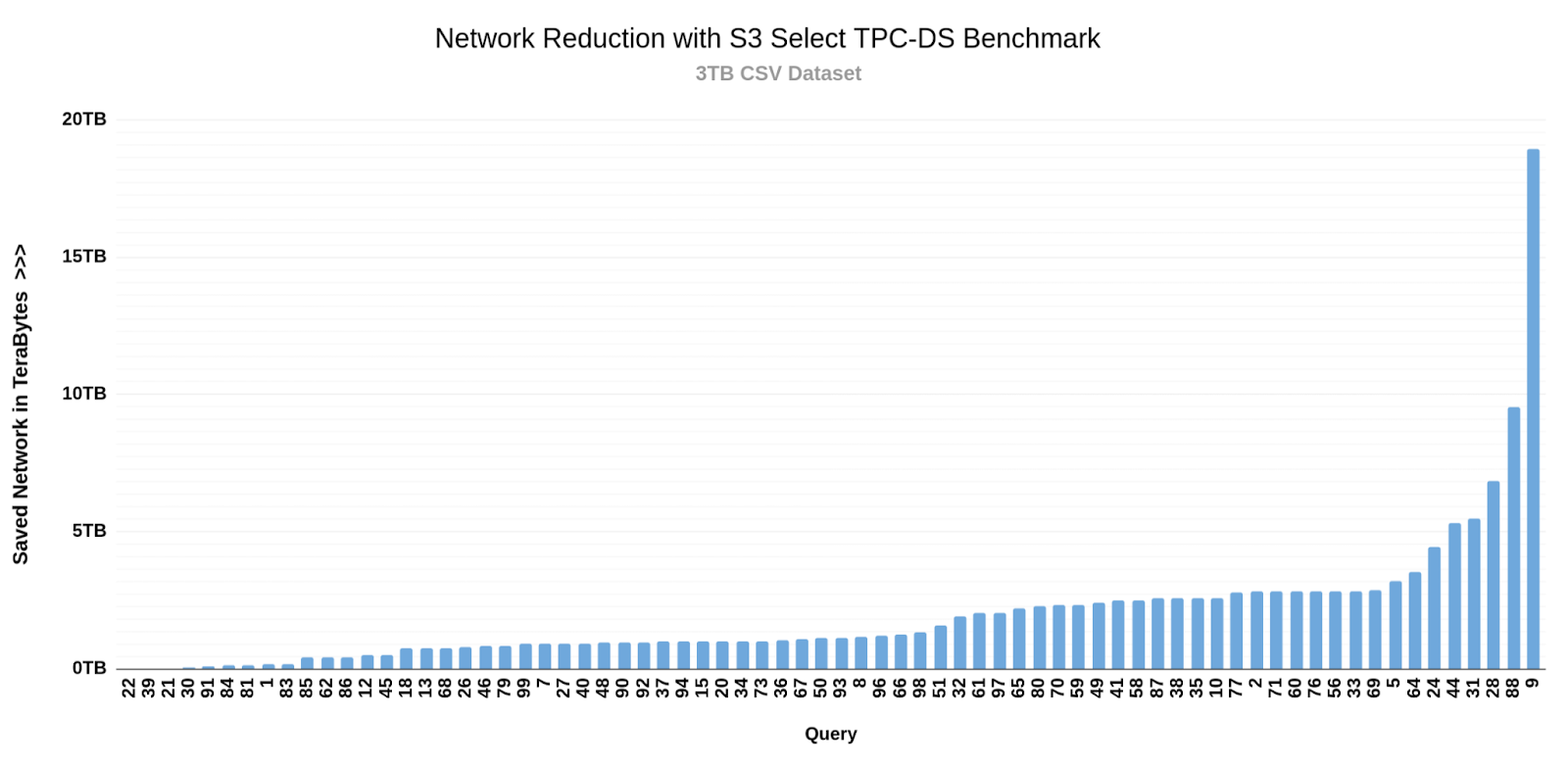
This next section will provide an overview of the TPC-DS Benchmark results; these results help us understand how the IBM Storage Ceph Object S3 Select feature has vast benefits when working with CSV datasets. The benefits mainly come from improved query times and reduced data processing; we have included a diagram below that shows the total network savings achieved by using S3-select during our testing; we can save a total of 144TB of network data processing by utilizing this feature.
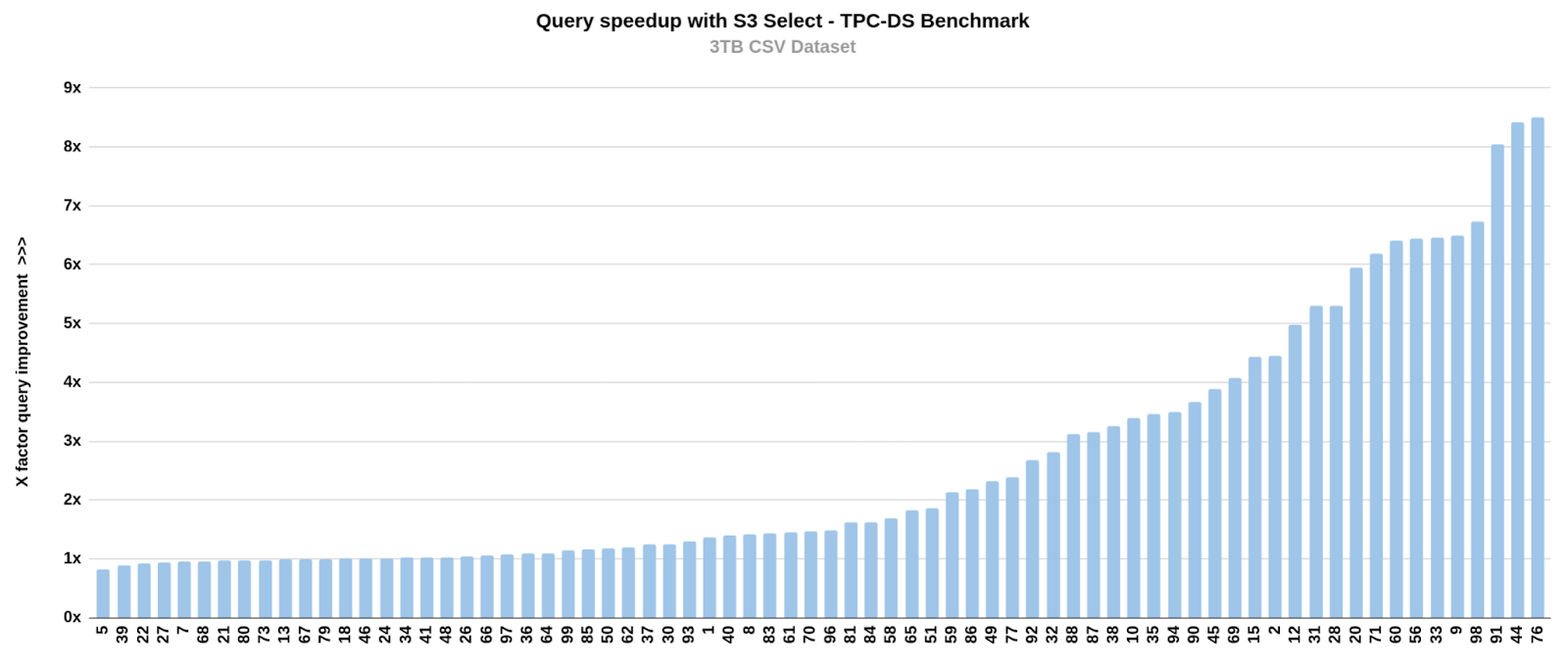
The following graph displays the per query speedup achieved using s3-select for the 3TB Scale dataset; the X-axis represents the speedup improvements for each query. During testing, we observed that enabling s3-select improved all of the 72 queries; the highest query reduction we saw was nine times faster, with an average improvement of around 2.5x.
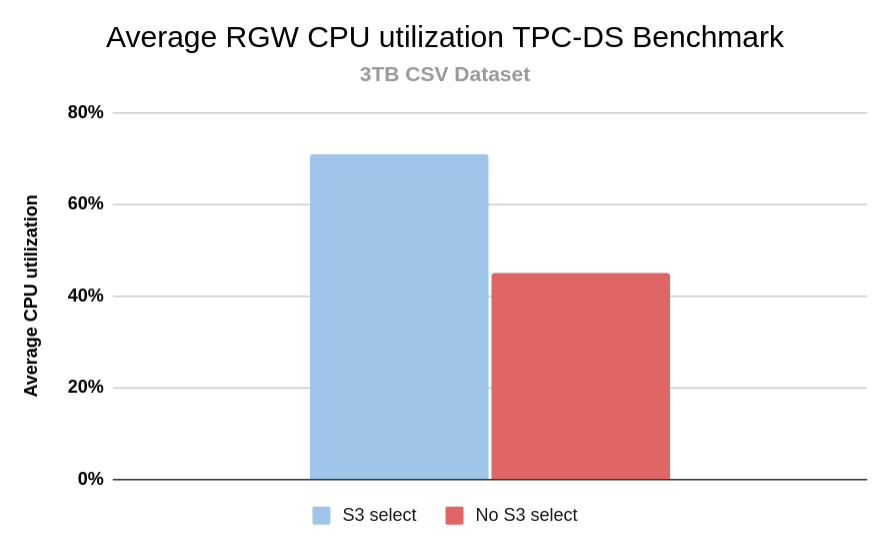
When S3-Select is enabled we are pushing down the computational work to the Ceph Object Gateways, so as expected there was an increase in CPU usage of the IBM Storage Ceph Object gateways during the execution of the queries with S3-Select enabled. However, it was still well within safe boundaries. The memory consumption increase with S3 select enabled during the execution of the queries was barely noticeable, with an average increase in memory consumption of 2.50%; pushdown can process objects of any size since it does so in chunks (without preloading the object).
The third graph shows the network processing reduction per query; as you can see from the graph, when S3-select was enabled, all of the 72 queries saw a decrease in network processing. Query number 9 was able to reduce the network data processing by 18TB. The total reduction in processed data across all 72 queries was 144 TB when enabling S3 Select.
Summary & what’s up Next
In this post, we are excited to share the results of our benchmark testing, where we ran our TPC-DS 72 queries at 1TB and 3TB scale. We have found that by utilizing IBM Storage Ceph Object S3-Select Pushdown performance optimizations, you can now run queries faster than before. With Trino and S3-Select, you can push the computational work of projection and predicate operations to IBM Storage Ceph, resulting in up to 9x performance improvement in query runtime, with an average of 2.5x. This significantly reduces data transferred through the network, saving 144TB of network traffic for the 72 executed queries. Organizations can enhance their data lake performance, reduce costs, and simplify data access by combining IBM Storage Ceph(S3-Select) with Trino/Presto.
IBM Storage Ceph resources
Find out more about IBM Storage Ceph.