IBM Storage Ceph Object Storage Multisite Replication Series. Part Seven, the Archive Zone.
In part Seven of this IBM Storage Ceph Multisite series, we will be introducing the Archive zone, concepts and architecture, and we will also share a hands-on example of attaching an archive zone to a running IBM Storage Ceph Object Multisite cluster
Introduction
Archive your critical data residing on IBM Storage Ceph using the Archive Zone Feature.
The Archive zone uses the multi-site replication and S3 object versioning features; in this way, it will keep all versions of the object available even when deleted in the production site.
With the archive zone, you can have object immutability without enabling object versioning in your production zones, saving the space that the replicas of the versioned S3 objects would consume in the rest of the zones.
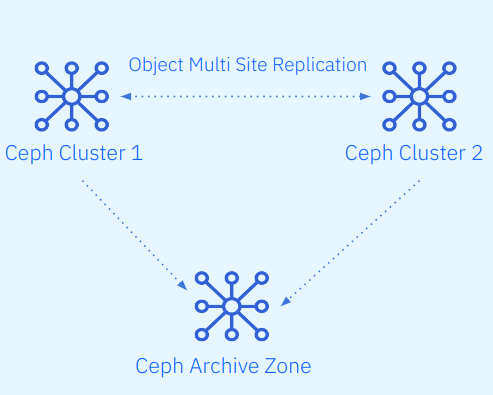
Protect your data against logical or physical errors. It can save users from logical failures, for example, accidental deletion of a bucket in the production zone. It can protect your data from massive hardware failures like a complete production site failure.
As the archive zone provides an immutable copy of your production data, it can help build a ransomware protection strategy.
You can control the storage space usage of an archive zone through the bucket Lifecycle policies of the production buckets, where you can define the number of versions you would like to keep for an object.
We can select on a per-bucket basis the data that we want to send/replicate to the archive zone. If for example, we have pre-production buckets that don’t have any valuable data we can disable the archive zone replication on that bucket.
The Archive Zone Architecture
The Archive zone being a zone in a multisite zonegroup its represented by a Full Ceph Cluster, it can have a different setup than the production zone, it’s own set of pools and replication rules for example.
IBM Storage Ceph archive zone feature has the following main characteristics:
-
Versioning is enabled in all buckets in the RGW archive zone.
-
Every time a user uploads a new object, this object is asynchronously replicated to the archive zone.
-
A new object version is generated in the archive zone for each object modification in the production zone.
-
We are providing immutability because If an object is deleted in the production zone, the object is kept intact in the archive zone. But it’s essential to notice that the archive zone is not applying any object lock to the objects it ingests; the objects are deletable on the archive zone if the user has access to the S3 endpoint with the appropriate permissions.
The Archive zone S3 endpoint for data recovery can be configured on a private network that is only accessible to the operations administrator team. If a recovery of a production object is required, the request would need to go through the administrator ops team.
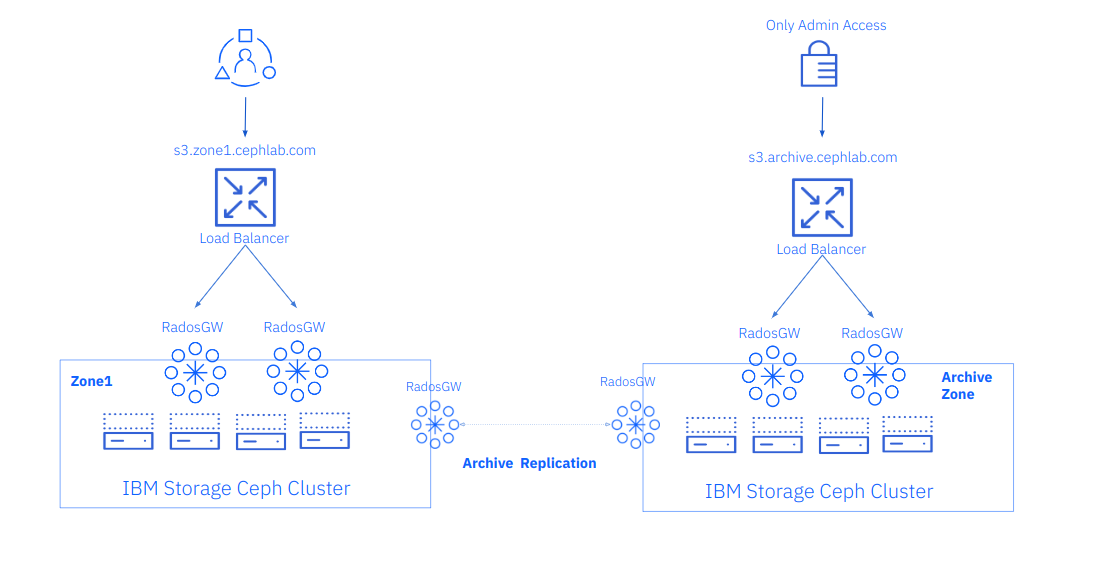
We can deploy the archive zone to an IBM Storage Ceph Object Storage single site configuration; with this configuration, we can attach the archive zone to the current running single zone, single Ceph cluster, as depicted in the following figure:
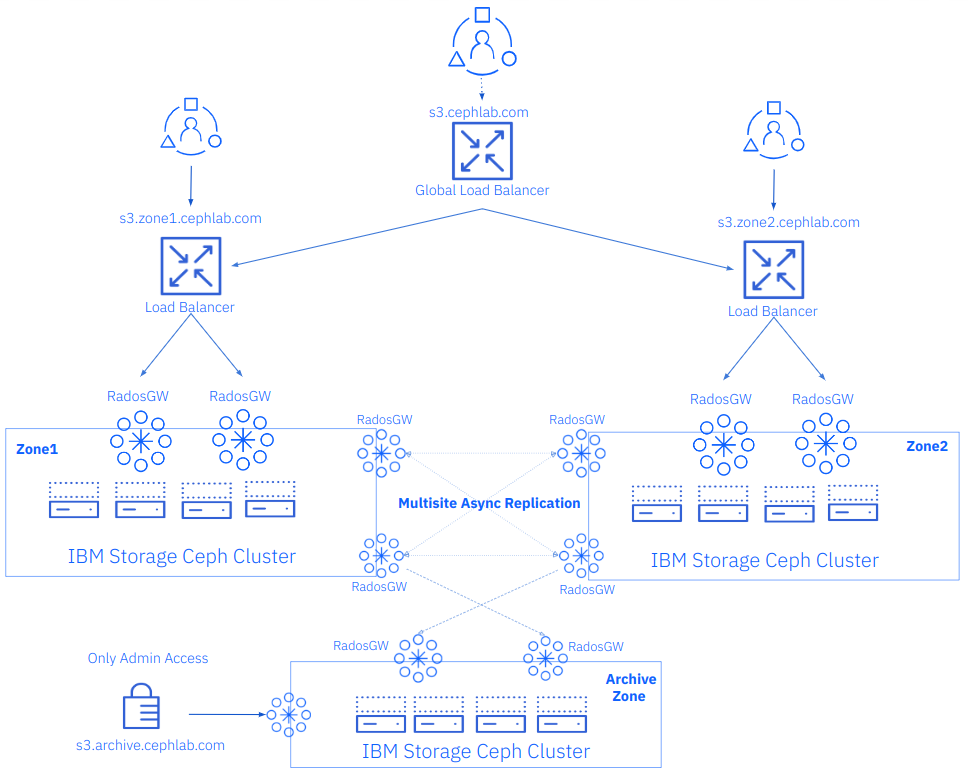
Or we can attach our Archive zone to an IBM Storage Ceph Object Storage multisite configuration, so if, for example, we had a realm/zonegroup replicating between two zones, we can add a third zone representing a third ceph cluster; this is the architecture that we are going to use in our example, continuing with our work in the previous posts were we have setup an IBM Storage Ceph Multisite replication cluster, we are now going to add a third zone to our zonegroup configured as a read-only archive zone. An example of this architecture is shown in the following diagram.
Let’s start with our archive zone configuration; I have a freshly deployed third ceph cluster that runs on four nodes from 08 to 11, ceph-node-[08-11].cephlab.com.
[root@ceph-node-08 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-node-08.cephlab.com ceph-node-08 _admin,osd,mon,mgr,rgwsync
ceph-node-09.cephlab.com 192.168.122.135 osd,mon,mgr,rgwsync
ceph-node-10.cephlab.com 192.168.122.204 osd,mon,mgr,rgw
ceph-node-11.cephlab.com 192.168.122.194 osd,rgw
4 hosts in cluster
Currently, the archive zone is not configurable using the RGW MGR module, so we must run some radosgw-admin commands to get it configured. First, we must pull the information from our already deployed' multisite' cluster realm. We use a zone group endpoint and the access key and secret key for our RGW multisite synchronization user, if you need to check the details of your sync user, you can run: `radosgw-admin user info --uid sysuser-multisite`
[root@ceph-node-08]# radosgw-admin realm pull --rgw-realm=multisite --url=http://ceph-node-01.cephlab.com:8000 --access-key=X1BLKQE3VJ1QQ27ORQP4 --secret=kEam3Fq5Wgf24Ns1PZXQPdqb5CL3GlsAwpKJqRjg --default
[root@ceph-node-08]# radosgw-admin period pull --url=http://ceph-node-01.cephlab.com:8000 --access-key=X1BLKQE3VJ1QQ27ORQP4 --secret=kEam3Fq5Wgf24Ns1PZXQPdqb5CL3GlsAwpKJqRjg
Once we have pulled the realm and the period locally, our third cluster has all the required Realm and zone group configuration, so if we run a `radosgw-admin zonegroup get`, you will be able to see all of the details for our current multisite setup, moving forward we will configure a new zone, called `archive`, we provide the list of endpoints, these endpoints are the sync RGWs that we are going to run on our new cluster, again the access-key and secret-key for the sync user, and last but not least the tier type, this flag is the one that defines that this new zone is going to be created as an archive zone.
[root@ceph-node-08]# radosgw-admin zone create --rgw-zone=archive --rgw-zonegroup=multizg --endpoints=http://ceph-node-08.cephlab.com:8000,http://ceph-node-09.cephlab.com:8000 --access-key=X1BLKQE3VJ1QQ27ORQP4 --secret=kEam3Fq5Wgf24Ns1PZXQPdqb5CL3GlsAwpKJqRjg --tier-type=archive --default
With the new zone in place, we can update the period to push our new zone config to the rest of the zones in the zone group
[root@ceph-node-08]# radosgw-admin period update --commit
Using cephadm, we are going to deploy two RGW services that will be utilised to replicate the data from the production zones; in this example, we are going to use the cephadm rgw cli instead of a spec file to showcase a different way to configure your ceph services with cephadm. Both of the RGWs that we are spinning up will belong to the archive zone; using the `--placement` argument, we are configuring two RGW services that will run on ceph-node-08, and ceph-node-09, the same nodes we configured as our zone replication endpoints on our previous commands.
[root@ceph-node-08 ~]# ceph orch apply rgw multi.archive --realm=multisite --zone=archive --placement="2 ceph-node-08.cephlab.com ceph-node-09.cephlab.com" --port=8000
Scheduled rgw.multi.archive update...
We can check the RGWs have started correctly:
[root@ceph-node-08]# ceph orch ps | grep archive
[root@ceph-node-08]# ceph orch ps | grep archive
rgw.multi.archive.ceph-node-08.hratsi ceph-node-08.cephlab.com *:8000 running (10m) 10m ago 10m 80.5M - 18.2.0-131.el9cp 463bf5538482 44608611b391
rgw.multi.archive.ceph-node-09.lubyaa ceph-node-09.cephlab.com *:8000 running (10m) 10m ago 10m 80.7M - 18.2.0-131.el9cp 463bf5538482 d39dbc9b3351
Once the RGW spin-up, the RGW pools for the archive zone get created for us, here remember if we wanted to use EC for our RGW Data pool, this would be the moment to create it before we enable replication from production to the archive zone. The data pool gets created using the default configuration of replica x3.
[root@ceph-node-08]# ceph osd lspools | grep archive
8 archive.rgw.log
9 archive.rgw.control
10 archive.rgw.meta
11 archive.rgw.buckets.index
If we now check the status of the sync from one of our archive zone nodes, we can see that there is currently no replication configured; this is because we are using `sync policy`, and there is no zonegroup sync policy configured for the archive zone:
[root@ceph-node-08]# radosgw-admin sync status --rgw-zone=archive
realm beeea955-8341-41cc-a046-46de2d5ddeb9 (multisite)
zonegroup 2761ad42-fd71-4170-87c6-74c20dd1e334 (multizg)
zone bac4e4d7-c568-4676-a64c-f375014620ae (archive)
current time 2024-02-12T17:19:24Z
zonegroup features enabled: resharding
disabled: compress-encrypted
metadata sync syncing
full sync: 0/64 shards
incremental sync: 64/64 shards
metadata is caught up with master
data sync source: 66df8c0a-c67d-4bd7-9975-bc02a549f13e (zone1)
not syncing from zone
source: 7b9273a9-eb59-413d-a465-3029664c73d7 (zone2)
not syncing from zone
Now, we want to start replicating data to our archive zone, so we need to create a zone group policy; if you recall from our previous post, we have a zone group policy configured to “allow” replication at the zone group level, and then we configured replication on a per-bucket basis.
In this case, we will take a different approach with the archive zone. We are going to configure unidirectional sync at the zone group level, and we are going to set the policy status to “enabled” so by default, all buckets in the zone `zone1` will get replicated to the `archive` archive zone.
Like always, to create a sync policy, we need a group, a flow and a pipe, let's go ahead and create a new zone group group policy called “grouparchive”
[root@ceph-node-00 ~]# radosgw-admin sync group create --group-id=grouparchive --status=enabled
We are creating a “directional”(unidirectional) flow, that will replicate all data from zone1 to the archive zone:
[root@ceph-node-00 ~]# radosgw-admin sync group flow create --group-id=grouparchive --flow-id=flow-archive --flow-type=directional --source-zone=zone1 --dest-zone=archive
Finally, we create a pipe where we use * for all the fields to avoid typing the full zone names, as the * represents all the zones configured in the flow; we could have also typed zone1 and archive zone in the different zone fields.
[root@ceph-node-00 ~]# radosgw-admin sync group pipe create --group-id=grouparchive --pipe-id=pipe-archive --source-zones='*' --source-bucket='*' --dest-zones='*' --dest-bucket='*'
Zonegroup sync policies always need to be committed
[root@ceph-node-00 ~]# radosgw-admin period update --commit
If we check the configured zone group policies, we now have two groups, `group1` from our previous blog posts and `grouparchive` that we created and configured right now:
[root@ceph-node-00 ~]# radosgw-admin sync group get
[
{
"key": "group1",
"val": {
"id": "group1",
"data_flow": {
"symmetrical": [
{
"id": "flow-mirror",
"zones": [
"zone1",
"zone2"
]
}
]
},
"pipes": [
{
"id": "pipe1",
"source": {
"bucket": "*",
"zones": [
"*"
]
},
"dest": {
"bucket": "*",
"zones": [
"*"
]
},
"params": {
"source": {
"filter": {
"tags": []
}
},
"dest": {},
"priority": 0,
"mode": "system",
"user": ""
}
}
],
"status": "allowed"
}
},
{
"key": "grouparchive",
"val": {
"id": "grouparchive",
"data_flow": {
"directional": [
{
"source_zone": "zone1",
"dest_zone": "archive"
}
]
},
"pipes": [
{
"id": "pipe-archive",
"source": {
"bucket": "*",
"zones": [
"*"
]
},
"dest": {
"bucket": "*",
"zones": [
"*"
]
},
"params": {
"source": {
"filter": {
"tags": []
}
},
"dest": {},
"priority": 0,
"mode": "system",
"user": ""
}
}
],
"status": "enabled"
}
}
]
If we check any bucket from zone1, I have chosen the `unidrectional` bucket, but it could be any other; we will see that we now have a new syn policy configured with the id `pipe-archive`, that comes from the zone group policy we just applied because this is unidirectional. I’m running the command from ceph-node-00 (zone1). I only have the dests field populated with the source being zone1 and the destination being the archive zone.
[root@ceph-node-00 ~]# radosgw-admin sync info --bucket unidirectional
{
"sources": [],
"dests": [
{
"id": "pipe-archive",
"source": {
"zone": "zone1",
"bucket": "unidirectional:66df8c0a-c67d-4bd7-9975-bc02a549f13e.36430.1"
},
"dest": {
"zone": "archive",
"bucket": "unidirectional:66df8c0a-c67d-4bd7-9975-bc02a549f13e.36430.1"
},
"params": {
"source": {
"filter": {
"tags": []
}
},
"dest": {},
"priority": 0,
"mode": "system",
"user": ""
}
},
{
"id": "test-pipe1",
"source": {
"zone": "zone1",
"bucket": "unidirectional:66df8c0a-c67d-4bd7-9975-bc02a549f13e.36430.1"
},
"dest": {
"zone": "zone2",
"bucket": "unidirectional:66df8c0a-c67d-4bd7-9975-bc02a549f13e.36430.1"
},
"params": {
"source": {
"filter": {
"tags": []
}
},
"dest": {},
"priority": 0,
"mode": "system",
"user": "user1"
}
},
If we run the `radosgw-admin sync status` command again, we can see that now the status for zone1 has changed from “not syncing from zone” to having synchronization enabled and “ data is caught up with source”
[root@ceph-node-08 ~]# radosgw-admin sync status --rgw-zone=archive
realm beeea955-8341-41cc-a046-46de2d5ddeb9 (multisite)
zonegroup 2761ad42-fd71-4170-87c6-74c20dd1e334 (multizg)
zone bac4e4d7-c568-4676-a64c-f375014620ae (archive)
current time 2024-02-12T17:09:26Z
zonegroup features enabled: resharding
disabled: compress-encrypted
metadata sync syncing
full sync: 0/64 shards
incremental sync: 64/64 shards
metadata is caught up with master
data sync source: 66df8c0a-c67d-4bd7-9975-bc02a549f13e (zone1)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source
source: 7b9273a9-eb59-413d-a465-3029664c73d7 (zone2)
not syncing from zone
At this point, all the data ingested into zone1 will be replicated to the archive zone; with this configuration, where we only have to set a uniderectional flow from “zone1” → “Archive”, so if, for example, a new object is ingested in zone2 because we have bi-directional bucket sync policy for the `unidirectional` bucket, the object replication flow will be the following: “zone2” → “zone1” → “Archive”
We can set another unidirectional zone group policy from “zone2”→ “Archive”, so objects ingested in zone2 don’t need zone1 available to get replicated to the archive zone; they can go directly to the archive zone.
Summary & up next
We have introduced the archive zone feature in Part Seven of this series. We shared a hands-on example of configuring an archive zone to a running IBM Storage Ceph Object Multisite cluster; in the final blog of the IBM Storage Ceph Multisite series, we will be demonstrating how the Archive Zone feature can help you recover critical data from your production site.
Links to the rest of the blog series:
IBM Storage Ceph resources
Find out more about IBM Storage Ceph
#Featured-area-1
#Featured-area-1-home
#Highlights#Highlights-home