Performance and Scalability are the top two challenges for AI storage Nowadays organizations are using AI for digital transformation, such as leveraging deep learning to detect problematic products in manufacture to reduce the need for manual efforts for improved production, or leveraging deep learning for face recognition and human behavior analysis in security industry etc. IDC predicts that by 2021, 75% of commercial enterprise apps will use AI[1], so it will be everywhere in the near future. And by looking at the infrastructure of AI, we see that compute nodes are developing really fast: NVIDIA’s DGX-2 server performance has improved 10x in six months[2], much faster than Moore’s law predicts. So the next question is: how can storage keep all these GPUs fed with data?
So the first challenge for users is performance: once they invest in an expensive GPU cluster and start to run AI jobs, they often find that overall performance is not as good as expected and realize storage is the bottleneck. There are two common IO patterns for AI workloads: either small-cache IO for IOPS requirements or large-cache IO for throughput requirements. For example, in TensorFlow, if your applications read pictures directly and if your pictures are small (e.g. 10KB per picture) IOPS requirements will be high; if your applications read formatted data, TensorFlow will read the data with 256KB per IO[3], which requires high storage throughput. So ideally the storage needs to provide consistent performance with flexible IO patterns.
Due to the explosive data growth and development of AI technology, more compute nodes with GPUs will be used for the training phase of the workflow, requiring more data to meet the increasing demands of AI jobs. This leads to the second major challenge for AI storage: the need to future proof the system by ensuring that it can support good scaling with more compute nodes and more storage-side nodes.
How IBM Spectrum Scale can help with these two top challengesSo how IBM Storage can help with these requirements? Fortunately, IBM offers IBM Spectrum Scale with its proven track record as the leading high performance and scalable file system that can provide huge throughput and/or high IOPS with various options of hardware configurations and no practical limits on scaling with performance improvement.
In a recent customer proof of concept deployment using Caffe for video analytics, IBM demonstrated that IBM Spectrum Scale could keep all of the GPUs 100% busy for seven compute nodes (four P40 GPUs per compute node) with just a few SSDs, and could support the scaling of the compute nodes from seven to twenty nodes without performance decline, far outpacing a competitive offering and satisfying the customer’s requirements.
Here is a recommend architecture for adopting IBM Spectrum Scale for your AI workload:
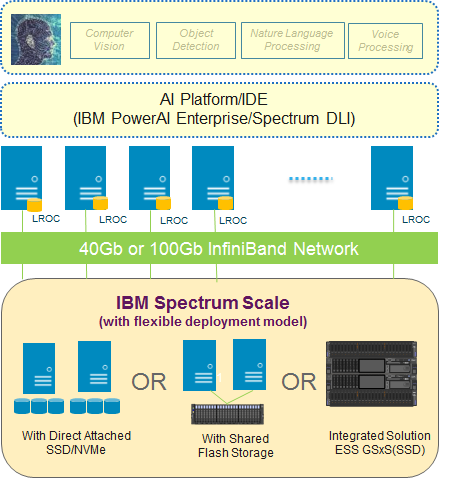 Figure 1 Reference Architecture for AI
Figure 1 Reference Architecture for AIThe recommended hardware configurations are:
1)IBM Spectrum Scale Server/Client configuration
2)Sharing-nothing cluster (with high IOPS SSD or NVMe storage) or IBM Elastic Storage Server (ESS) GSxS/SSD or IBM Flash storage
3)40Gb/100Gb InfiniBand or RoCE ethernet for RDMA
For customers requiring higher performance, IBM Spectrum Scale also provides a cache mechanism to further boost performance: configuring the local SSD in the computing node to cache the frequently read data in local SSD will allow further reads to be done from local SSD instead of going back and forth from the backend storage. This is referred as ‘LROC’ (Local Read Only Cache) in the above reference architecture and more details can be found
here. And the latest release of IBM Spectrum Scale (5.0.1+) includes performance enhancements specifically for AI such as better support for Caffe with LMDB.
In addition, IBM Spectrum Scale supports RDMA which can significantly reduce the IO latency between computing nodes and IBM Spectrum Scale servers to achieve higher IOPS and throughput.
IBM Spectrum Scale can directly leverage Hadoop environment data for AI jobsVery often, customers have a Hadoop environment and want AI applications to re-use the Hadoop data. This is a perfect fit for IBM Spectrum Scale, which can ‘enable’ all the data for Hadoop to be seen immediately by AI workloads for in-place analytics without the need to copy data, by contrast with the native HDFS solution. The reference architecture is as below.
 Figure 2 Reference Framework for AI and big dataIBM Spectrum Scale can provide economical tiering for big data lake
Figure 2 Reference Framework for AI and big dataIBM Spectrum Scale can provide economical tiering for big data lakeAs AI data continues to grow, users often implement data tiering to make their storage more economical. IBM Spectrum Scale offers transparent cloud tiering that allows cold data readily to migrate to and from cloud storage, as shown in the reference architecture below.
 Figure 3 Reference Architecture for large Data Lake
Figure 3 Reference Architecture for large Data LakeIn summary, IBM Spectrum Scale can fully meet the performance and scalability requirements for AI workloads thanks to its parallel storage architecture, which has been successfully deployed in hundreds of highly demanding customer environments, coupled with continuous innovation including performance enhancements such as LROC and RDMA. Beyond these two critical advantages, IBM Spectrum Scale also provides advanced features that help to better fit it into the bigger infrastructure picture, include integration with Hadoop environments to support in-place analytics, transparent cloud tiering for big data etc. We believe IBM Spectrum Scale will be your optimal choice of AI storage for today and tomorrow. To learn more, please visit
IBM Spectrum Scale product page.
Reference1. Worldwide Storage for Cognitive/AI Workloads Forecast, 2018–2022, April 2018, IDC #US43707918
2. http://images.nvidia.com/content/pdf/dgx2-print-datasheet-a4-nv-620850-r9-web.pdf
3. I/O size is decided by Tensorflow not storage software
4.
IBM Spectrum Scale Knowledge Center5.
IBM Elastic Storage ServerAcknowledgementMany thanks for a lot of IBM members(Rong Shen, Rick Janowski, Douglas O'flaherty and Spectrum Scale BDA team members etc) for their helpful comments.
#AI#DeepLearning#IBMSpectrumScale#Softwaredefinedstorage#cognitivecomputing#BigDataandAnalytics