Cassandra offers a robust solution for managing and storing large datasets used in machine learning (ML). With its ability to provide scalability, high performance, fault tolerance, flexibility and seamless integration with other tools and platforms, it can efficiently handle the demands of ML workloads. This makes it a reliable choice for organizations dealing with big data and complex machine learning tasks.
ML using Cassandra is a strategy that involves utilizing Apache Cassandra as a storage and management system for the massive amount of data needed in ML. Building a ML model using Cassandra and Scikit-Learn to develop a predictive model that can learn from the massive data stored in Cassandra and make accurate predictions on new data. The applications can be used in various industries such as Finance, Logistics, Healthcare, and E-commerce, where there is a large volume of data to be analyzed for making informed decisions.
In this blog, I'll demonstrate how to build a classification model for truck maintenance using Cassandra and Scikit-learn, which can provide a valuable tool for the transportation industry by helping to reduce the risk of unexpected breakdowns and ensure that trucks are operating efficiently.
What is Cassandra
Cassandra is an open source database application from Apache. It is known as a NoSQL (Not only SQL) type of database application and can be accessed and administered from various nodes both remotely and directly.
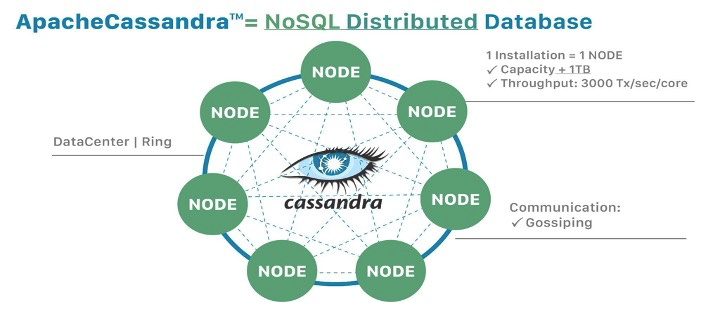
Features of Cassandra
-
It is a column-oriented database.
-
It is highly consistent, fault-tolerant, and scalable.
-
Peer to peer architecture.
-
Faster processing, easy to learn & work on it.
-
Uncomplicated process for data copying, etc.
-
It was created for Facebook and was later open-sourced.
-
The data model is based on Google Bigtable.
-
The distributed design is based on Amazon Dynamo.
Key characteristics of Cassandra
-
Open source availability
-
Distributed footprint
-
Scalability
-
Cassandra Query Language
-
Fault tolerance
-
Schema free
Why Cassandra
-
Instant and simple solutions for complex problems such as, logging and metrics collection with a simple, sleek and elegant feature for centralized logging.
-
Low maintenance overhead. Cassandra databases can run almost independently hence reducing maintenance dependency.
-
Low cost of maintenance since it hardly requires any maintenance so cost automatically boils down.
-
Easy to learn and large number of developers for community support.
-
Fast read and write a feature. Reading and writing on disks using Cassandra is quite fast and feasible.
Working with Cassandra
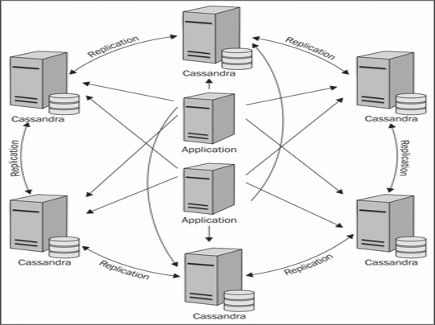
Cassandra architecture
Start Cassandra cluster
Run the following command to start the Cassandra cluster:
cqlsh
The cql environment will be activated.
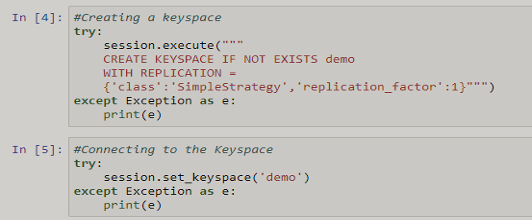
Create Keyspace
Run the following command to create the keyspace:
CREATE KEYSPACE name WITH REPLICATION = {‘class’: ‘class name’, ‘replication_factor’: no. of replications}

Validate available keyspaces
Run the following command to show all the keyspaces available:
DESCRIBE KEYSPACES;

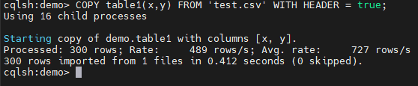
Import Data from CSV
In Cassandra, you can import data from CSV files also. To do so, first you have to create a table with same structure as the CSV file, then you can use the following command:
COPY tablename (col names) FROM ‘file.csv’ WITH HEADER = true;
Python for Cassandra
Here, you will see how to use python scripts to connect to the Cassandra database, write data, read data, and perform operations on the data inside the database.
Jupyter Notebook
-
Start the Jupyter Notebook with no browser on the server where Cassandra is installed by running this command:
ssh -L 8888:localhost:8888 username@ip -p port-number
-
Activate the Anaconda base environment, as shown:

-
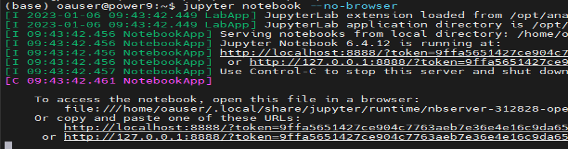
Start Jupyter Notebook with no browser (since we are on remote access):
jupyter notebook –no-browser
-
Copy the link with token id and paste it into the browser. You should now be able to see the Jupyter Notebook window on your browser.
Connection String
Inside Jupyter Notebook, open a new Python file and Start with installing Cassandra drivers (for first time connection only).
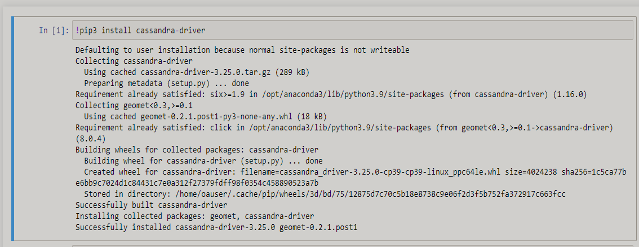
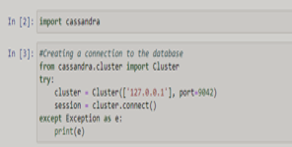
Connect with cluster
import cassandra
from cassandra.cluster import Cluster
cluster = Cluster([Self.host], port = Self.port)
Session = cluster.connect()
Create Keyspace
Create table

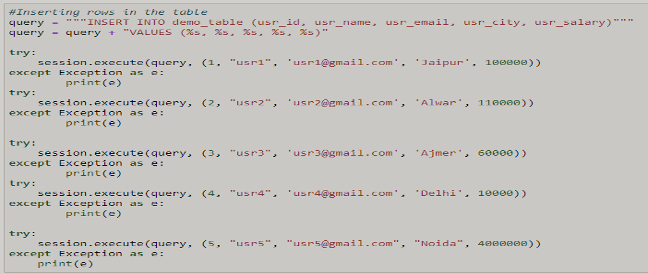
Insert data
Query data
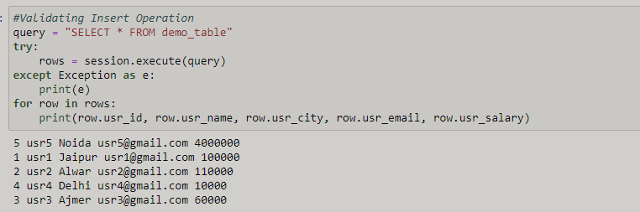
Training machine learning model for truck fleet maintenance optimization
Connection

Since, we have data in the database, we have to create pandas DataFrame for training ML algorithms on this data. Steps will be as follows:
-
Import pandas
-
SELECT query for retrieving data
-
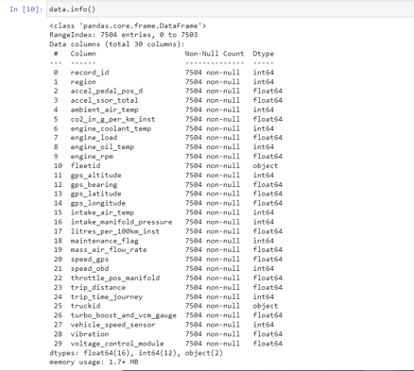
Convert data into pandas DataFrame
DataFrame
Accuracy
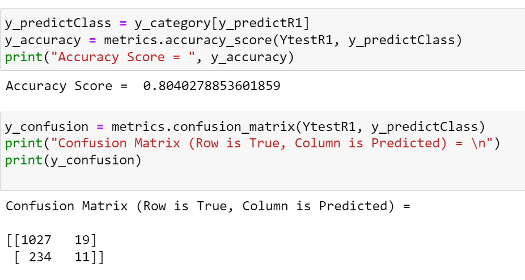
Summary
Since, we have stored data into a pandas DataFrame, any model can be trained on this data.
Thank you!