
The content on this page was originally published on Instana.com and has been migrated to the community as a historical asset. As such, it may contain outdated information on our products and features. Please comment if you have questions about the content.
Context
Instana aims to provide accurate and instant application monitoring metrics on dashboards and in Unbounded Analytics. These metrics are calculated based on millions of calls collected from the systems under monitoring. Calls are stored in Clickhouse which is a columnar database and each call has hundreds of tags stored in columns.
We use various techniques to speed up the querying of this data. The most important one is the use of materialized views. The idea is to select a couple of most frequently used tags such as service.name, endpoint.name, http.status etc., and pre-aggregate metrics (call count, latency, error rate etc.) over these tags into buckets of different sizes (1min, 1h). The materialized view contains much fewer data than the original table so it is much faster to read, filter and aggregate from the view.
However, this approach has a limitation. There are 2 types of tags that cannot be included into the materialized view. Therefore, queries filtering or grouping by these tags cannot be optimized:
Tag that has very high cardinality
Including tags like http.url into the materialized view will increase the number of rows in the view. For example, if we only include endpoint.name in the view, endpoint /api/users/{id} will have only 1 row per minute if the bucket size is 1 minute. However, if we include http.path in addition and the endpoint receives requests with hundreds of different paths such as /api/users/123, each unique path would generate a new row in the view.
Custom key value pair tag defined by the user
Users could add custom tags to an agent (agent.tag), to a call through SDK (call.tag), to a docker container (docker.label) or define a custom HTTP header (call.http.header). Each tag has a custom key and value, e.g. agent.tag.env=prod, docker.label.version=1.0. The keys are dynamic and unknown to Instana, so we cannot create a static materialized view on top of these columns.
We need to figure out a solution to optimize the latency of queries using these tags.
Solution
The solution we came up with is to automatically detect complex queries that cannot be optimized by the materialized views, register them as precomputed filters and tag calls matching these filters during processing time. The idea is to move the complexity from query time to the processing time. This allows to better distribute the filtering and aggregation work load over time during call processing. When the load increases, it’s easier and less costly to scale out the processing component than the database.
The general architecture looks as following:
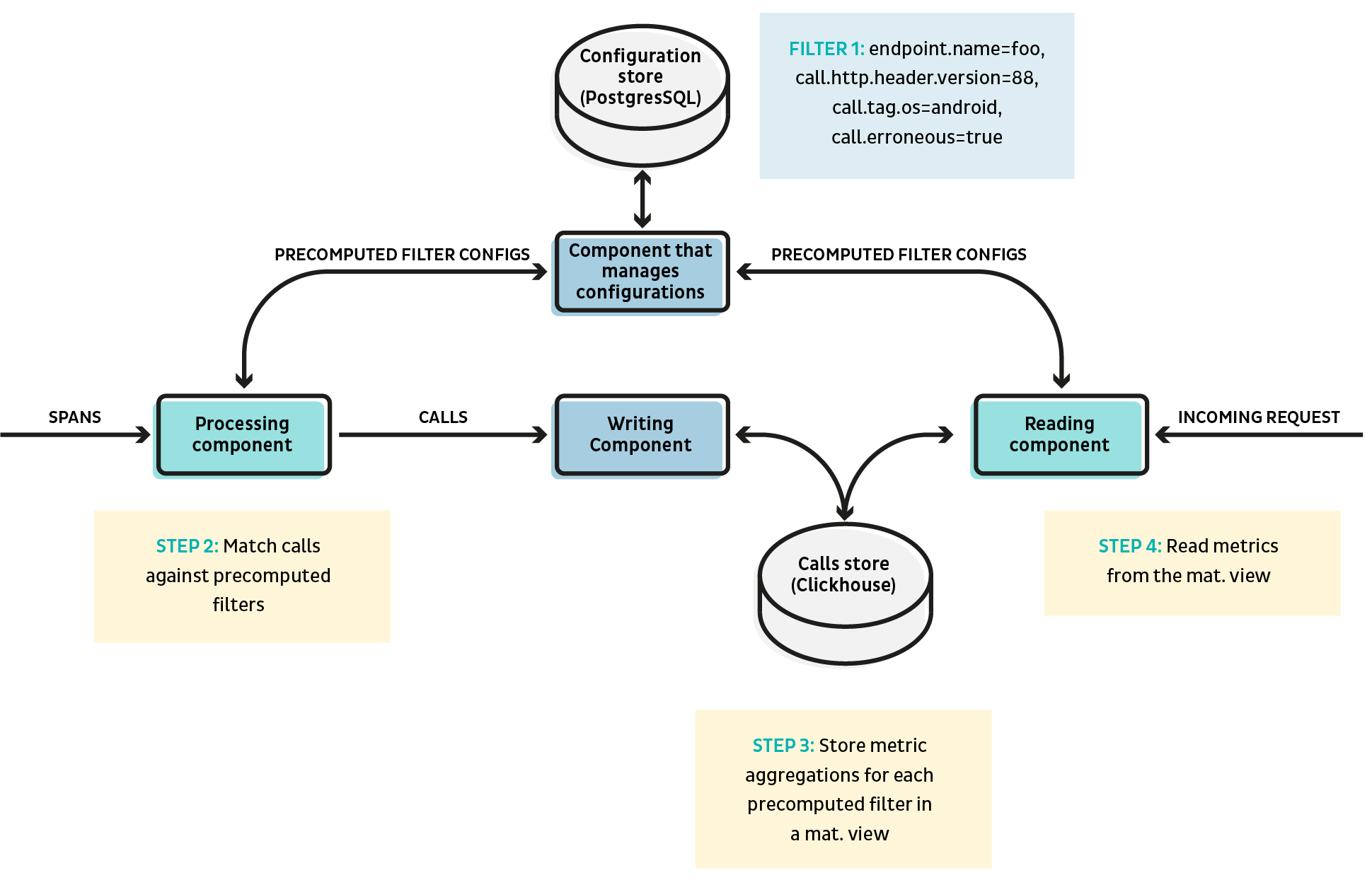
- Step 1: The reading component detects and registers the complex queries as a precomputed filter and pushes them to a shared database. A precomputed filter is basically mapping between a key and a complex filtering with tags on the calls, e.g. filter1: endpoint.name=foo AND call.http.header.version=88 AND call.tag.os=android AND call.erroneous=true, plus some metadata such as creation time or last hit time.
- Step 2: The processing component reads the precomputed filters from the shared database. Each incoming call will be matched against all the registered precomputed filters. If there’s a match, the call will be tagged with the filter id. A call can be tagged with multiple ids if it matches multiple filters.
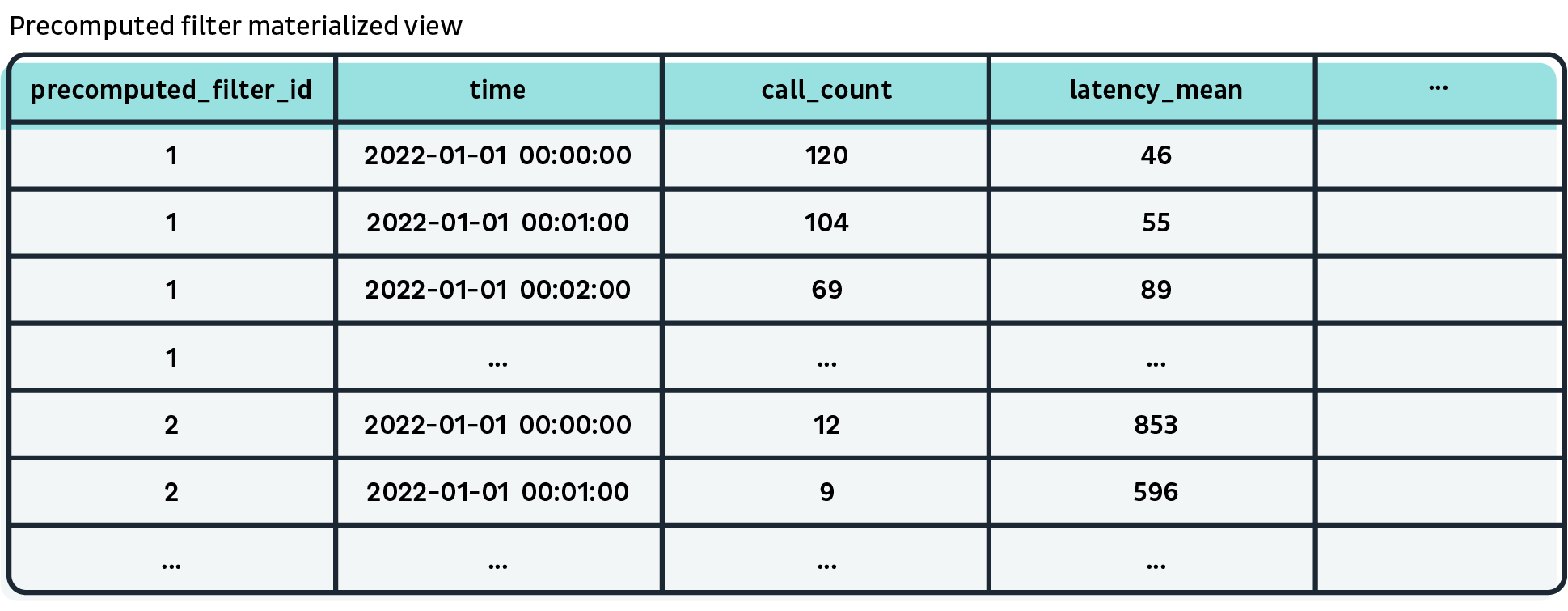
- Step 3: Calls are stored in Clickhouse with an additional column precomputed_filter_ids Array(String). We then create a materialized view which groups calls by each precomputed filter id. The id will be the primary key and sorting key of the view table, followed by the bucket timestamp, so querying the view filtered by id is extremely fast.
- Step 4: The reading component can transform a complex query into precomputed_filter.id = xxx, and query the materialized view to return the metrics for calls matching the complex query.
Sample pseudo query:
SELECT SUM(call_count)
FROM precomputed_filter_view
WHERE time > toDateTime(‘2022-06-01 00:00:00’)
AND time < toDateTime(‘2022-06-01 12:00:00’)
AND precomputed_filter_id = ‘1’
How do we handle grouping?
precomputed_filter.id = xxx only handles the filtering part, if the query requests for metrics grouped by a tag such as endpoint.name, we need to handle this with additional steps:
During the processing, if a call matches the filter, we need to extract the value of the grouping tag endpoint.name from the call, and also store this tag in an additional column. The column will also be included in the materialized view, placed after the precomputed_filter_id and time columns in the sorting key.
Sample pseudo query:
SELECT precomputed_filter_group, SUM(call_count)
FROM precomputed_filter_view
WHERE time > toDateTime(‘2022-06-01 00:00:00’)
AND time < toDateTime(‘2022-06-01 12:00:00’)
AND precomputed_filter_id = ‘1’
GROUP BY precomputed_filter_group
Result
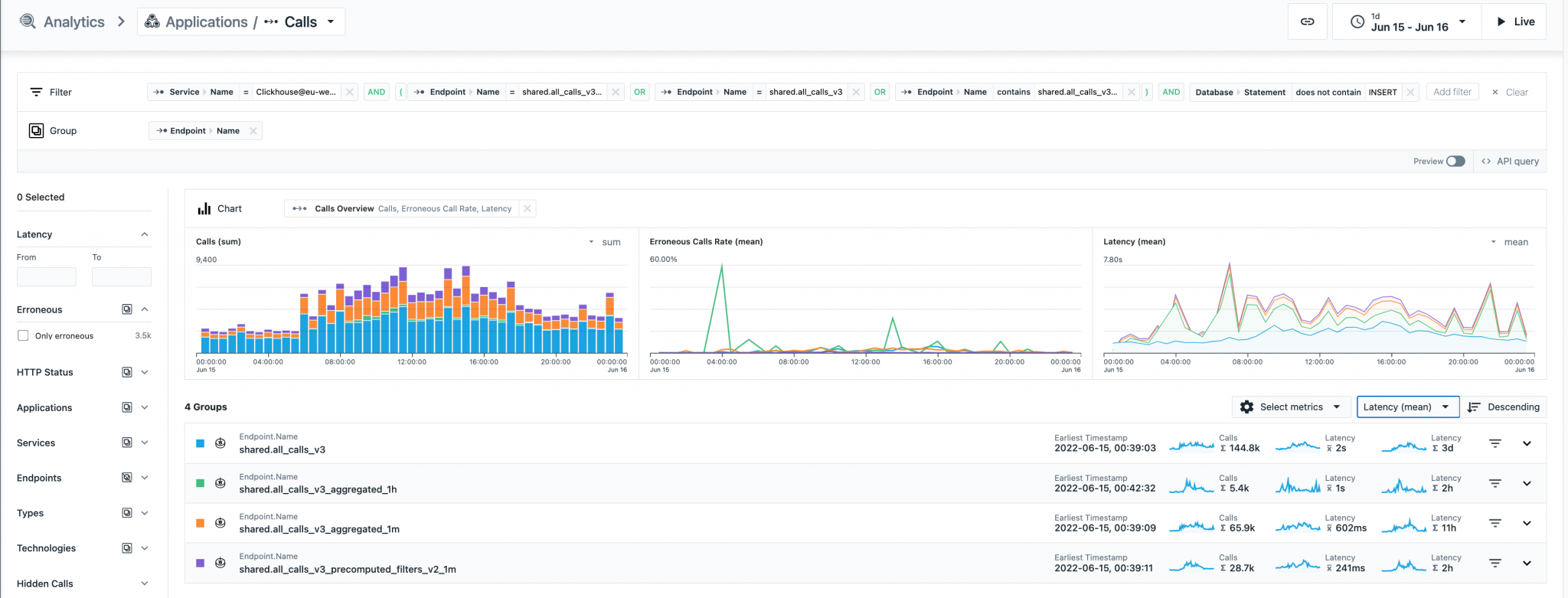
Above is a very coarse-grained analysis of queries customers did during a day in our EU region, broken down by different tables and views. We can see that the queries to the precomputed filter materialized view is almost 10 times faster than those to the original calls table, and 3 times faster than a query optimized by the materialized view of the same bucket size (1min).
Limitations and future improvements
The major limitation is that a query can only be optimized after it’s first registered as a precomputed filter. It works well for recurrent queries that users do on a regular basis. However, if a user runs an ad-hoc query in Unbounded Analytics for the first time over the last day or so, the optimization can not kick in immediately. To limit the load on the processing pipeline, we also disable a precomputed filter if it’s not used over a certain period of time.
Some complex queries are predictable if they are configured in a custom dashboard or alerting configuration. In these cases, we can use the configuration to create precomputed filters so that even users can see the metrics and charts quickly even if they open the custom dashboard or jump from an alert to Unbounded Analytics for the first time.