Part 2: Trip Duration by User Type
This question is a bit unclear in terms of what to do with the anomalies, so I'll be making two graphs. One with anomalies, one without.
There are NA values in the dataset for usertype as can be seen from missing table image above. Since it's only 0.09% of the data, it can be considered safe to remove.
According to Citi Bikes' website: The first 45 minutes of each ride is included for Annual Members, and the first 30 minutes of each ride is included for Day Pass users. If you want to keep a bike out for longer, it's only an extra $4 for each additional 15 minutes.
It's safe to assume, no one (or very few people) will be willing to rent a bike for more than 2 hours, especially a clunky citibike. If they did, it would cost them an additional $20 assuming they're annual subscribers. It would be more economical for them to buy a bike if they want that workout or use one of the tour bikes in central park if they want to tour and explore the city on a bike. There may be a better way to choose an optimal cutoff, however, time is key in a client project. Or just docing and getting another bike. The real cost of a bike is accrued ~24 hours.
Anomalies: Any trip which lasts longer than 2 hours (7,200 seconds) probably indicates a stolen bike, an anomaly, or incorrect docking of the bike. As an avid Citi Bike user, I know first hand that it doesn't make any sense for one to use a bike for more than one hour! However, I've added a one hour cushion just in case. No rider would plan to go over the maximum 45 minutes allowed. However, I plan to reduce this to one hour in the future for modeling purposes.
- First Half- with anomalies in dataset
- The bargraph of average trip duration for each user type. It's helpful, but would be better to see a box-plot or violin plot. Would be easier to interpret in minutes.
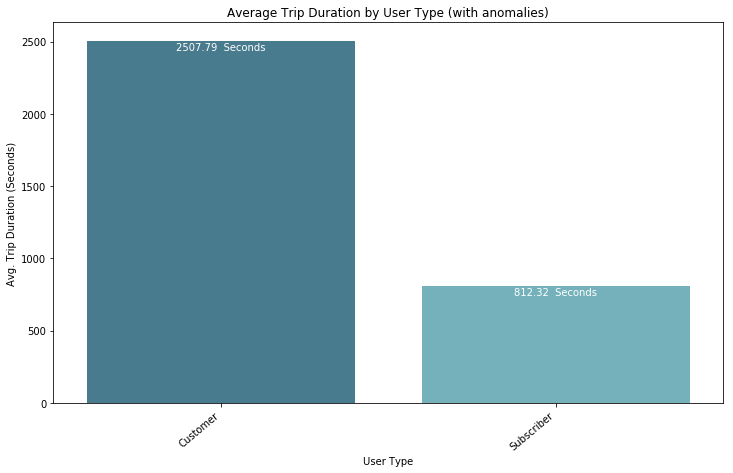
- Second graph is a basic violin plot based with anomalies included. As we can see, there is too much noise for this to be useful. It'll be better to look at this without anomalies.

2. Second Half - without anomalies in dataset
- A much more informative graph about trip duration based on user type with anomalies defined as mentioned above. "Fliers" have been removed from the graph below.
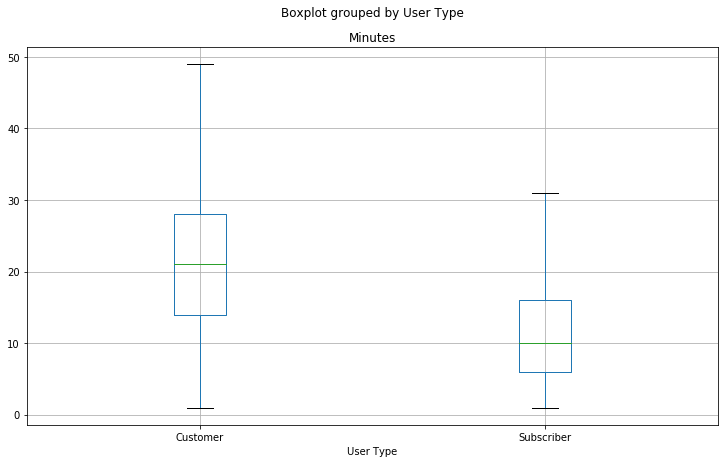 Note: User Type will most likely be a strong predictor of trip duration
Note: User Type will most likely be a strong predictor of trip duration
- Bar-graph highlighting average duration of each trip based on user type
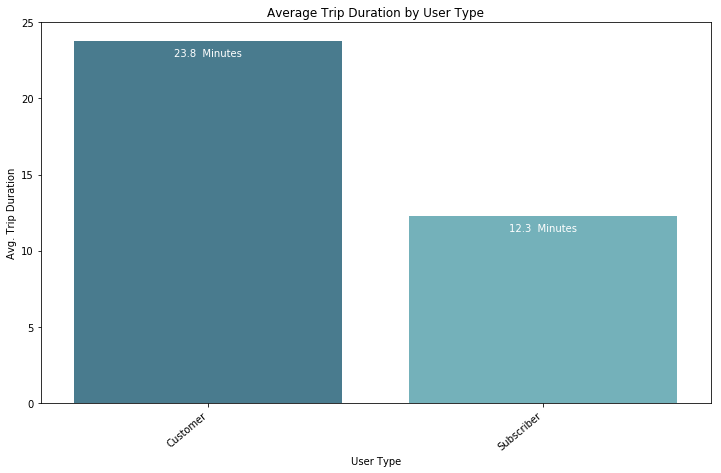
It's safe to say that user type will be a strong predictor of trip duration. It's a point to note for now and we can come back to this later on.
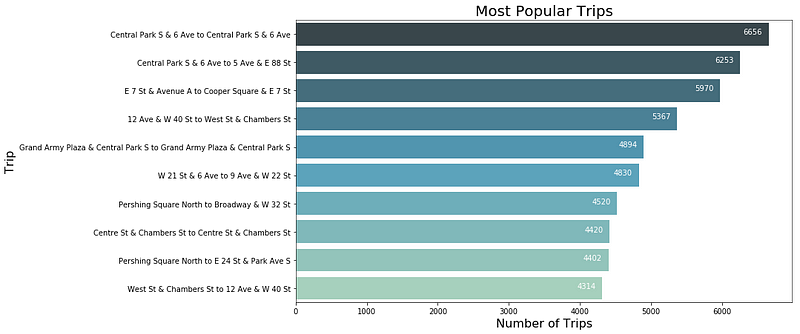
Part 3: Most Popular Trip
To get most popular trips, the most convenient way to do this is by using the groupby function in pandas. It's analogous to a Pivot table.
trips_df = df.groupby(['Start Station Name','End Station Name']).size().reset_index(name = 'Number of Trips')
The groupby function makes it extremely easy and convenient to identify the most popular trips.
Part 4: Rider Performance by Gender and Age
Ask: Rider performance by Gender and Age based on avg trip distance (station to station), median speed (trip duration/distance traveled)
Let's make sure the data we're working with here is clean.
- Missing Gender and Birth Year values? - Check missing_table above
- No for Gender. Yes for Birth Year
- ~10% Missing Birth year. Not a big chunk of data. Can either impute missing values or drop it. Since it's less than 10% of the data, it's safe to assume the rest of the 90% is a representative sample of data and we can replace the birth year with the median, based on gender and Start Station ID. I chose this method because most people the same age live in similar neighborhoods (i.e: young people in east village, older people in Upper East Side, etc.). This will be done after anomalies are removed and speed is calculated. There may be better ways to impute this data, please share your thoughts in the comments section below.
df['Birth Year'] = df.groupby(['Gender','Start Station ID'])['Birth Year'].transform(lambda x: x.fillna(x.median()))
2. Are there anomalies?
- For Birth Year, there are some people born prior to 1960. I can believe some 60 year olds can ride a bike and that's a stretch, however, anyone "born" prior to that riding a Citi Bike is an anomaly and false data. There could be a few senior citizens riding a bike, but probably not likely.
- My approach is to identify the age 2 standard deviations lower than the mean. After calculating this number, mean - 2stdev, I removed the tail end of the data, birth year prior to 1956.
df = df.drop(df.index[(df['Birth Year'] < df['Birth Year'].mean()-(2*df['Birth Year'].std()))])
3. Calculate an Age column to make visuals easier to interpret:
df['Age'] = 2018 - df['Birth Year'];
df['Age'] = df['Age'].astype(int);
4. Calculate trip distance (Miles)
- No reliable way to calculate bike route since we can't know what route a rider took without GPS data from each bike.
- Could use Google maps and use lat, long coordinates to find bike route distance. However, this would require more than the daily limit on API calls. Use the geopy.distance package which uses Vincenty distance uses more accurate ellipsoidal models. This is more accurate than Haversine formula, but doesn't matter much for our purposes since the curvature of the earth has a negligible effect on the distance for bike trips in NYC.
- In the future, for a dataset of this size, I would consider using the Haversine formula to calculate distance if it's faster. The code below takes too long to run on a dataset of this size.
dist = []
for i in range(len(df)):
dist.append(geopy.distance.vincenty(df.iloc[i]['Start Coordinates'],df.iloc[i]['End Coordinates']).miles)
if (i%1000000==0):
print(i)
5. Calculate Speed (min/mile) and (mile/hr)
- (min/mile): Can be used like sprint time (how fast does this person run)
df['min_mile'] = round(df['Minutes']/df['Distance'], 2)
- (mile/hr): Conventional approach. Miles/hour is an easy to understand unit of measure and one most people are used to seeing. So the visual will be created based on this understanding.
df['mile_hour'] = round(df['Distance']/(df['Minutes']/60),2)
6. Dealing with "circular" trips
- Circular trips are trips which start and end at the same station. The distance for these trips will come out to 0, however, that is not the case. These points will skew the data and visuals. Will be removing them to account for this issue.
- For the model, this data is also irrelevant. Because if someone is going on a circular trip, the only person who knows how long the trip is going to take is the rider, assuming s/he knows that. So it's safe to drop this data for the model.
df = df.drop(df.index[(df['Distance'] == 0)])
7. We have some Start Coordinates as (0.0,0.0). These are trips which were taken away for repair or for other purposes. These should be dropped. If kept, the distance for these trips is 5,389 miles. For this reason I've dropped any points where the distance is outrageously large. Additionally, we have some missing values. Since it's a tiny portion, let's replace missing values based on Gender and start location.