Keep your assets healthy and repair costs low by scheduling maintenance at exactly the right time
Yana Ageeva, Senior Data Scientist, IBM Data Science and AI Elite Team
Anthony Casaletto, Program Director, IBM Data Science and AI Elite Team

Photo by Jacek Dylag on Unsplash
Introducing IBM Industry Accelerators
The IBM Data Science and AI Elite (DSE) team was created over two years ago to work with clients in every industry to help them bring value to all aspects of the business by harnessing data science and AI . After over 160 engagements with clients worldwide, the DSE team created templated packages for some of the top use cases based on learnings from these engagements. We call these Industry Accelerators.
The accelerators are great learning assets, but they are so much more. They are usable components that help kickstart an implementation project, enabling an organization to implement the solution on their own data and get to productive use in an accelerated timeframe.
The Intelligent Maintenance accelerator is designed to address a wide range of audiences, from executive decision makers to data scientists to application developers. Glossaries and Terms provide the information architecture that you need to effectively catalog and analyze your data. The data science project includes assets covering data wrangling, machine learning models and decision optimization enabling the data scientists on the team to collaborate and extend the template models based on available data. The asset covers how to operationalize the implemented data science models, including a sample application, which demonstrates how the deployed models can be used embedded within a business workflow by the application developer.
What is predictive maintenance?
Unplanned maintenance is a key issue in a number of asset intensive industries such as manufacturing, oil and gas, and transportation. It can be extremely costly due to extended production downtimes. Not only do they result in high urgency repairs and investment in new machinery and parts, but unexpected production loss may affect supplier obligation and force a company to purchase products from its competitors, resulting in significant unanticipated costs. According to research by Oneserve, machine downtime is costing British manufacturers over £180 billion a year.
Using predictive analytics and machine learning (ML), the data scientist can determine the lifespan of a machine and the likelihood of it failing on a given day, and then use this information to schedule maintenance before equipment fails but not before it is actually needed, avoiding unnecessary costs associated with repair and production loss (Figure 1). Depending on the industry, the type of assets can vary from cars and trucks to wind turbines, cranes, and oil platforms.
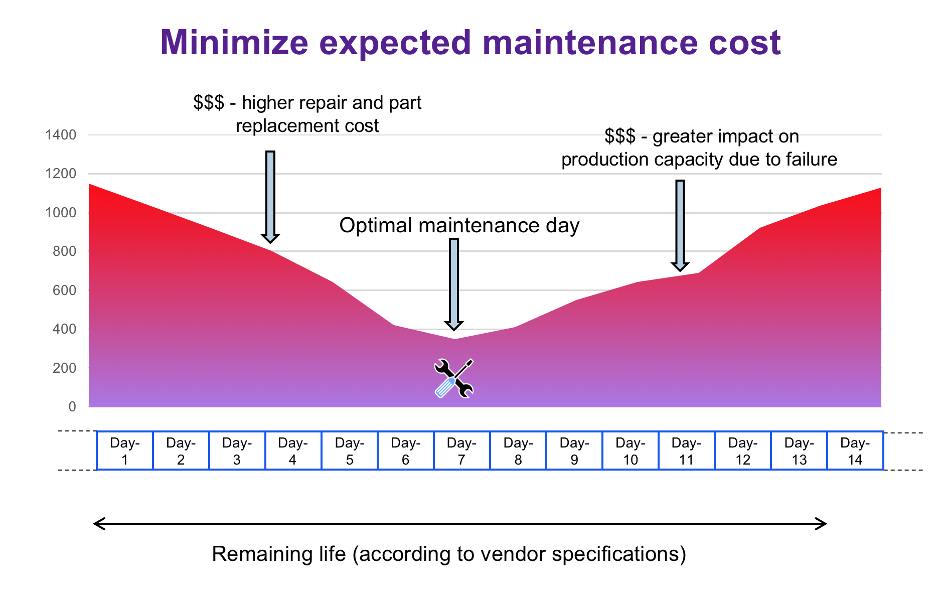
Figure 1: Predicting likelihood of failure helps determine the optimal time for machine maintenance
It is important to notice that predictive maintenance offers real advantages over preventive maintenance, which uses a fixed cycle for replacement and repair, often based on vendor specification. The latter doesn’t take into account the actual state of the machine or the specific environment where it operates, for example production levels or other operating conditions. Therefore, preventive maintenance is often inaccurate and results in excessive costs due to repairs being scheduled too late or too early. Predictive maintenance, on the other hand, can take into account historical data in order to more accurately predict the likelihood of failure.
Why predicting failure is key but not enough to solve the maintenance scheduling challenge?
A machine learning model can take into account all available information, such as sensor data, historical tasks and orders, past failure history, and maintenance history. As a result, it can help determine the optimal maintenance day for each machine based on its specific characteristics (Figure 2).
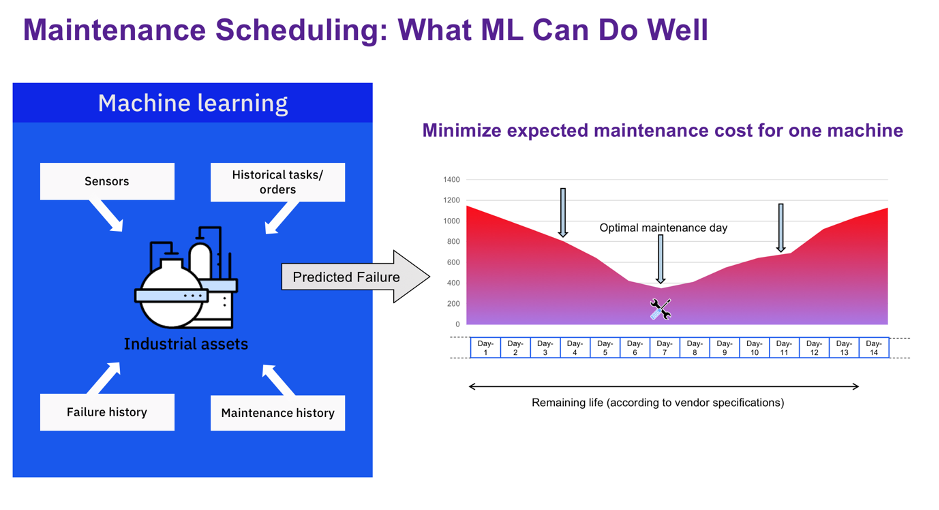
Figure 2: Predicting optimal maintenance day using ML (one machine at a time)
This methodology works great when we consider one machine at a time and there aren’t conflicting priorities. However, once we start introducing some complexity, dependencies, and limited resources, determining the optimal schedule becomes more challenging. For example, what if planned production happens to be highest on the day that we predict to be optimal for maintenance (Figure 3)? In this case, scheduling repairs a day early may end up being less costly as this way we can avoid peak production loss.
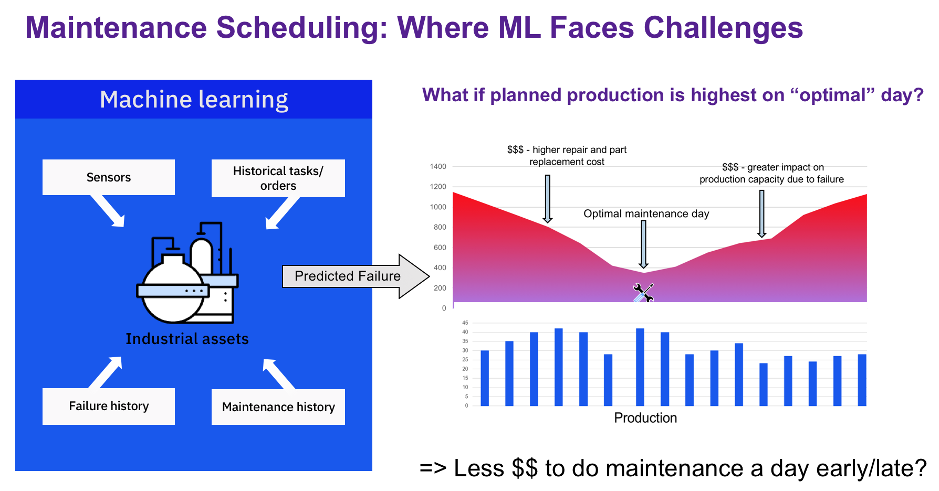
Figure 3: An “optimal” maintenance day may not be optimal if scheduled production numbers are high
More importantly, how do we deal with limited resources? If our ML model predicts that Day 3 is the optimal maintenance day for three machines (Figure 4), but only two maintenance crews are available, what should we do?
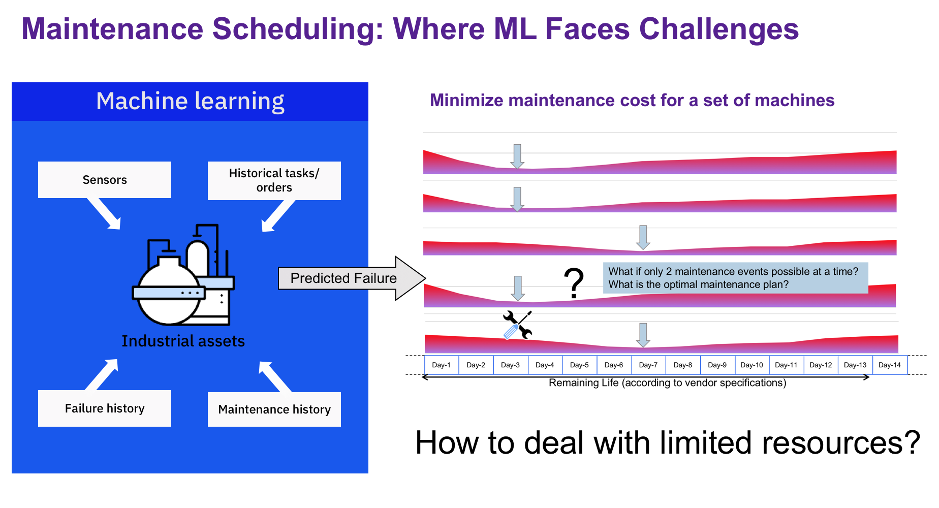
Figure 4: “Optimal” predicted maintenance day for each machine may not be feasible due to limited resources
How can decision optimization help?
While machine learning can take into account all available data and past history to predict the likelihood of failure for a given machine, decision optimization (DO) can take it a step further and generate a schedule that is optimal for a set of machines, subject to limited resources (e.g. maintenance crew availability), other constraints and dependencies (production plan and repair costs), and optimization metrics (minimizing total cost, maximizing customer satisfaction/meeting planned production, minimizing late maintenance). Not only does it offer us valuable insights, but it also generates an actionable schedule or plan (Figure 5).
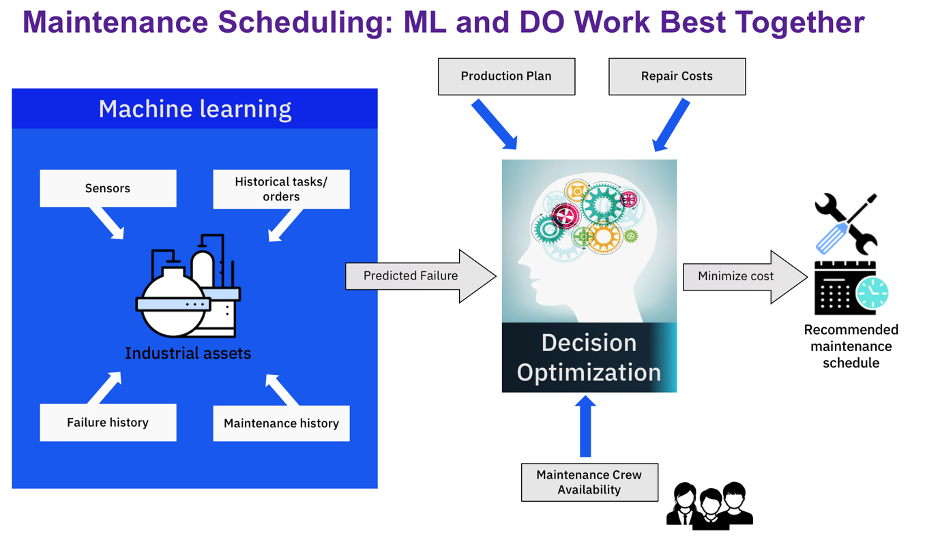
Figure 5: Combining the Power of Machine Learning & Decision Optimization for Maintenance Scheduling
As is the case with any business solution, it is not enough to create a model. Our ultimate goal should be a solution delivered in the hands of business users and decision makers. This is true no matter what technology is being used, and the methodology will be similar. Here, as an example, we outline how IBM Cloud Pak for Data (CPD), the IBM data science platform, can be used to build a predictive maintenance scheduling solution. The key steps are the following (Figure 6):

Figure 6: Decision Optimization application development and deployment using IBM Cloud Pak for Data
Step 0: Gather and Prepare available data
Gather all required data, including historical information on the machines and failure rates. Glossaries and Terms provide the information architecture that is needed to effectively catalog and analyze your data. IBM Cloud Pak for Data enables the data transformation step through a variety of tools including open-source scripts or visual drag-and-drop tooling.
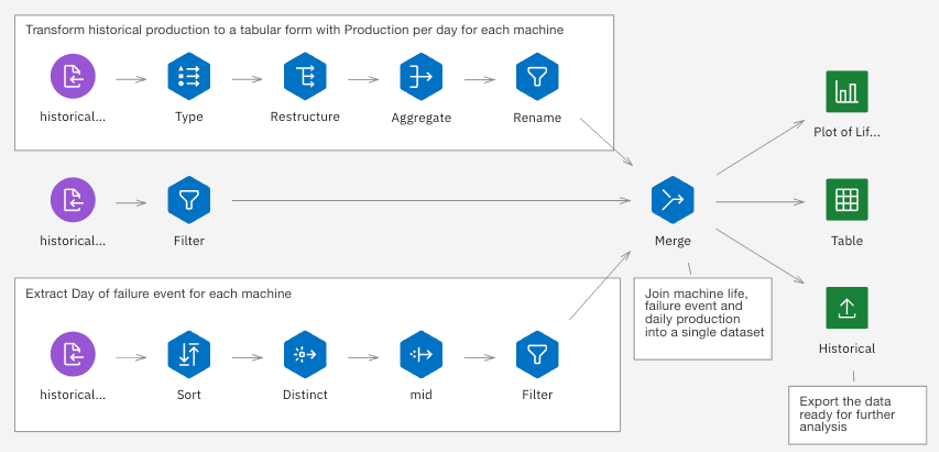
Figure 7 - SPSS Modeler Flow data transformation
Step 1: Build a Machine Learning Model
Build and deploy a machine learning model to predict the likelihood of failure on a given day. In IBM Cloud Pak for Data this can be done in a variety of ways, including automatic model building using AutoAI, building a model in Python or R using an open-source package such as scikit-learn or using SPSS Modeler’s drag-and-drop interface.
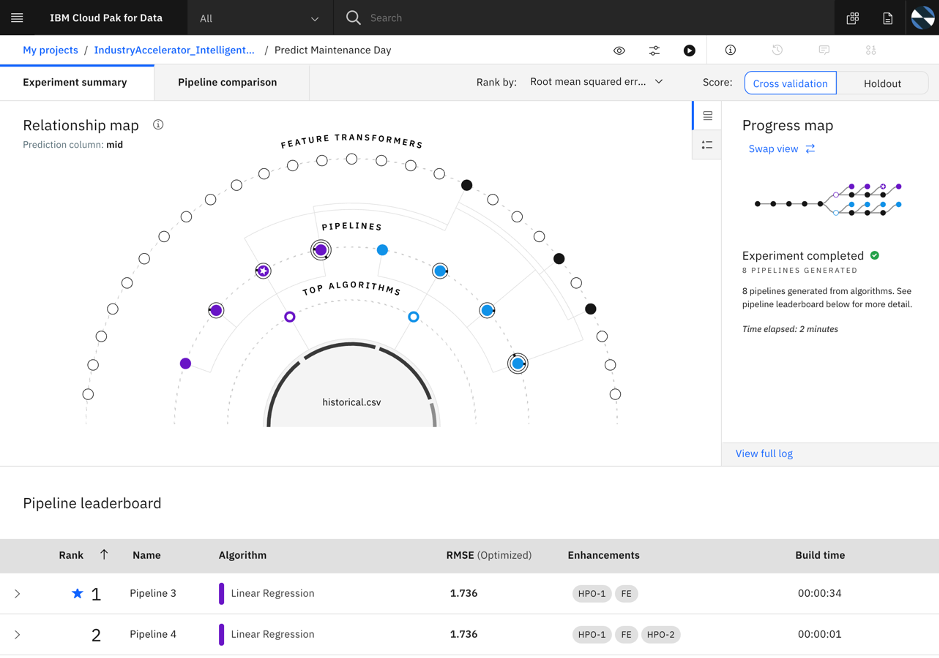
Figure 8: AutoAI model to predict failure day for an individual machine
Using AutoAI the tooling can automatically discover the most effective algorithm, transformations and Hyper Parameter Optimization (HPO) for the target variable based on the training data; based on the user specified evaluation metric and data partitioning scheme.
Once the model has been trained, validated, and tested, it can be deployed as an online model to be accessed using REST APIs.
Step 2: Build a Decision Optimization model to schedule maintenance
This step involves building an optimization model and creating an initial visualization dashboard to get feedback from the business users:
- Build a DO model to schedule maintenance. In IBM Cloud Pak for Data this can be done using the CPLEX Python API. The input of the DO model will include the output of the ML model, i.e. machine failure predictions.
- Configure a visualization dashboard and perform what-if analysis, i.e. create and compare different scenarios side-by-side. In IBM Cloud Pack for Data this can be easily done using Decision Optimization dashboardswhere you can create and compare different scenarios by changing your inputs, re-running the model, and visualizing the output. Once you are ready, share the dashboard with the business users to get feedback on the model and scenario presentation.
Let’s take a look at these two tasks in more detail.
Model business requirements
The key elements of a decision optimization model are optimization metrics, constraints, and decision variables.
Optimization metrics define what we are optimizing for (minimizing/ maximizing). In case of predictive maintenance these metrics could be any one or a combination of the following:
- minimize cost (maintenance, labor)
- minimize late maintenance
- maximize production
- maximize customer satisfaction
The optimization model will need to take into account a number of constraints, including:
- predicted likelihood of machine failure (output of the ML model)
- the impact of maintenance on production (we may want to avoid doing maintenance on days with highest planned production levels)
- maintenance crew availability
- machine characteristics (cost of repair, cost of remaining component life, etc.)
Finally, the decisions that need to be made (modelled as decision variables) determine the day/time when each machine is scheduled for maintenance. These values are not part of our input data and will instead be automatically determined by the optimization engine as part of the solution.
Visualize and compare scenarios side by side
Decision Optimization dashboards display inputs and outputs of our DO model. The input tab may look something like this:
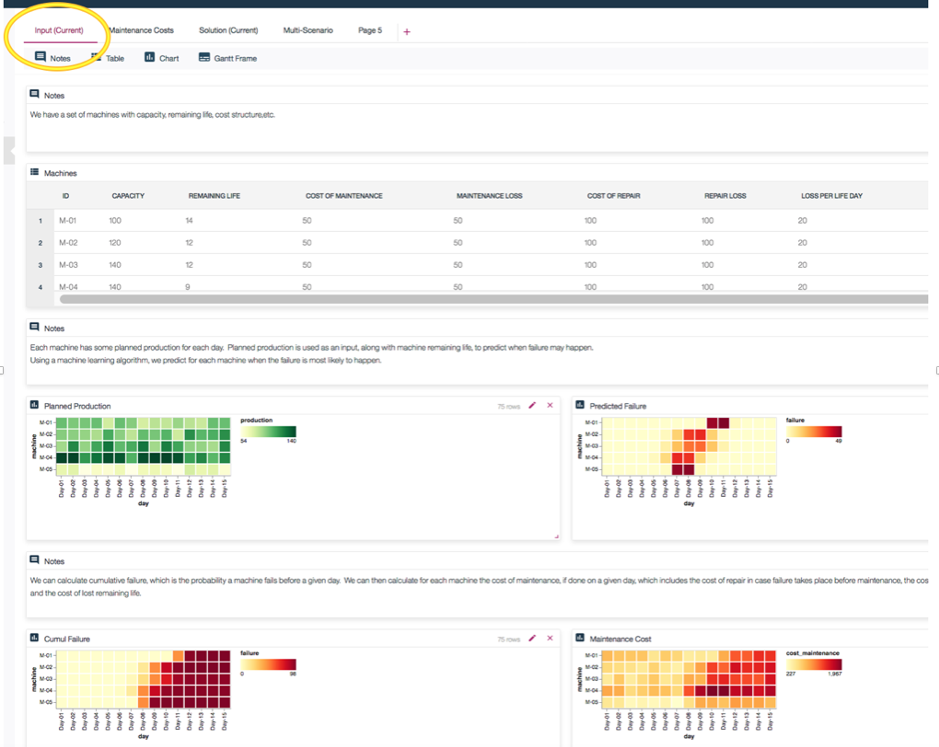
Figure 9: DO for Cloud Pak for Data Dashboard — scenario inputs
Here we see some data on machines and their characteristics, planned production levels by day, predicted failure (output of the ML model), and maintenance cost. Of particular interest is the predicted failure chart which may give some clues as to when it makes sense to schedule maintenance. Let’s say we wanted to use a heuristic and schedule “right before it gets too red”, meaning the day before the machine is very likely to fail. We will treat this as our “Manual” scenario and define maintenance events as follows (checkmark indicates a maintenance event):
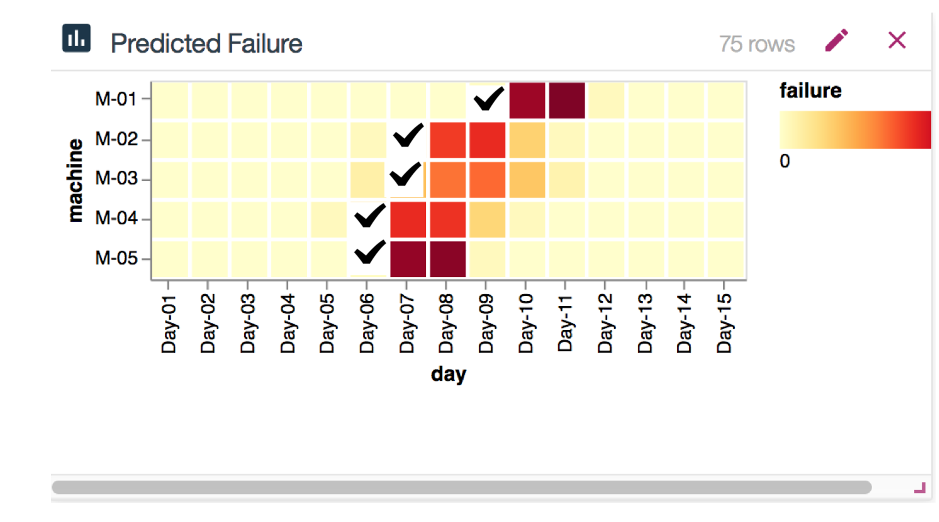
Figure 10: Using a heuristic to determine the optimal maintenance day for each machine
We also define an “Optimized” scenario with no fixed maintenance events and let the optimization engine determine the schedule automatically. After solving the two scenarios, we can compare the solutions side-by-side in the multi-scenario tab of the Dashboard:
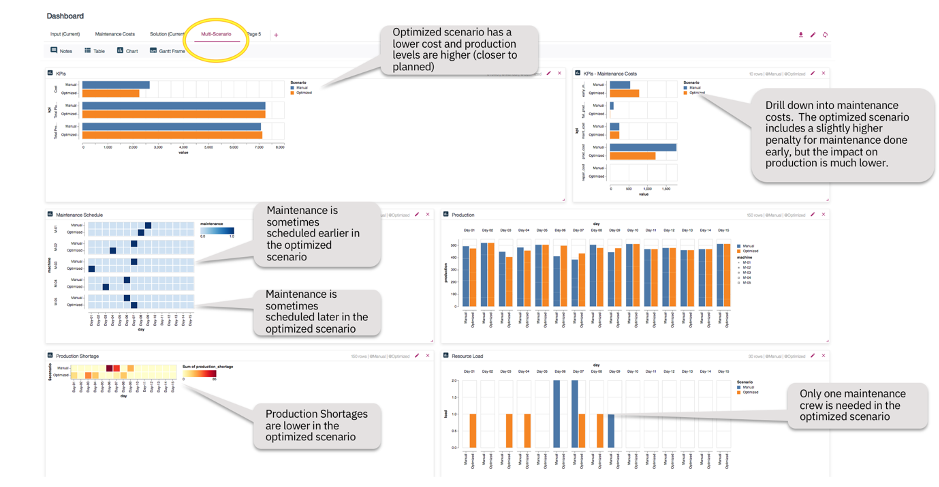
Figure 11: DO Dashboard — compare manual vs optimized scenarios side-by-side
Clearly the optimized scenario results in lower total cost and less production shortage. Looking at the maintenance schedule, it is easy to see that the optimal maintenance days aren’t obvious as in some cases it is better to schedule maintenance several days earlier and in other cases even one day late (machine 6). The optimized scenario also makes better use of resources — one maintenance crew required as compared to two in the “Manual” scenario. The benefits of optimization are easy to see, even on a very small problem (6 machines, 15 days, and small number of constraints). Imagine how much more difficult it would be to find a good solution when a problem is large (hundreds/thousands of machines and large number and type of constraints)!
Step 3: Deploy the models and embed them in your application
Once the business users have had a chance to review the dashboard and test scenarios, the Machine Learning and Decision Optimization models can be deployed as online web services using Watson Machine Learning within IBM Cloud Pak for Data. Each model is then available through a REST API endpoint. The final step is to build and deploy a web application (e.g. Node.js), or embed services in an existing one, and generate your maintenance schedule by accessing the ML and DO online models.
Under the main “Maintenance Planning” tab we connect to the ML executable service to obtain predictions. The top of each curve tells us when each machine is most likely to fail:
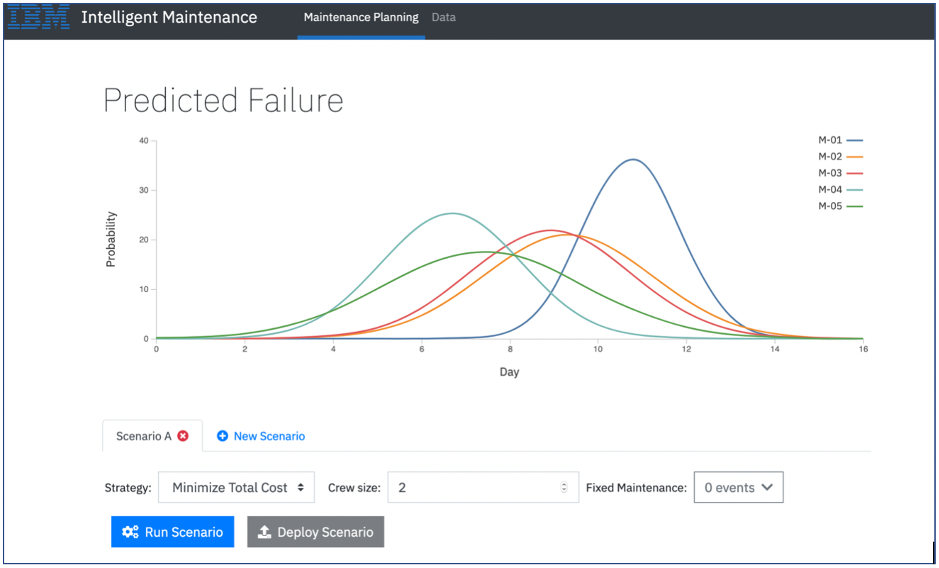
Figure 12: Connect to the executable ML service and obtain failure predictions
We are now ready to invoke the optimization service and generate the optimal maintenance schedule in one click of a button:
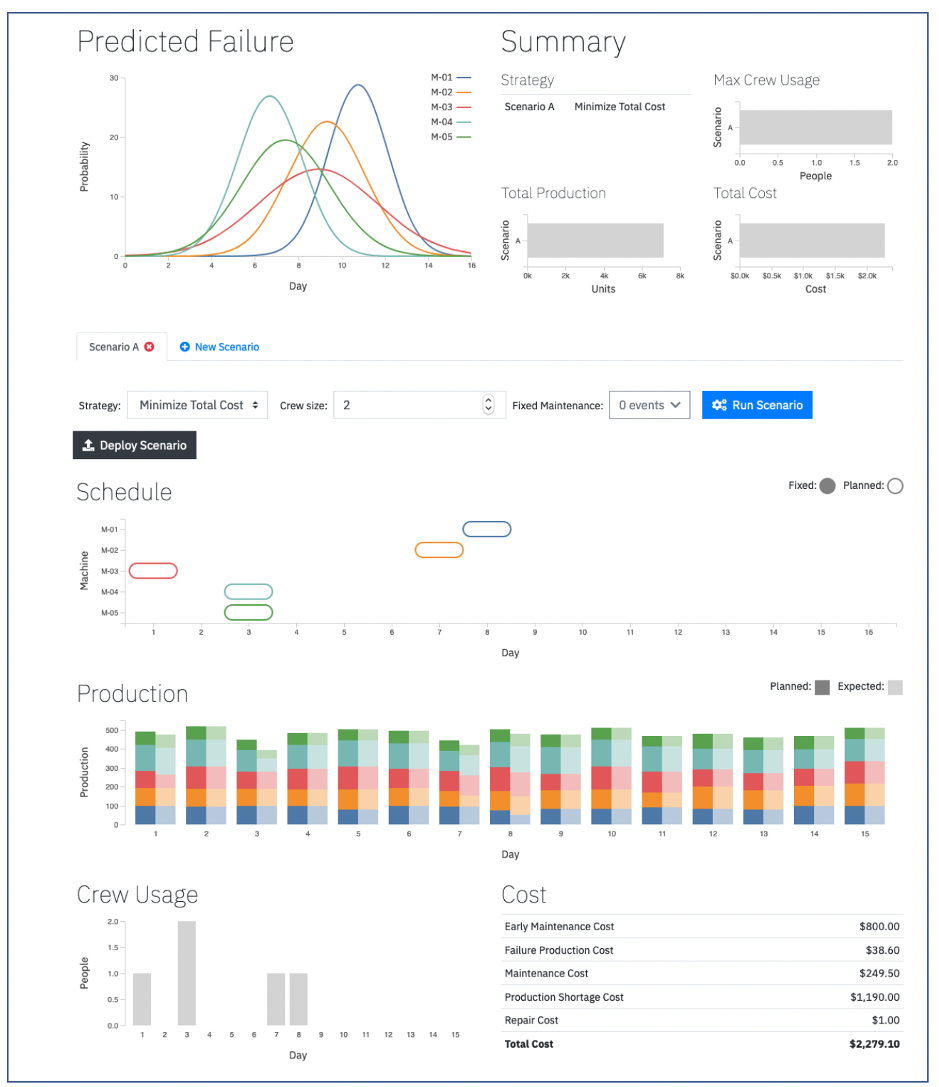
Figure 13: Connect to the online DO model and obtain the optimal maintenance schedule in one click!
Now that we have obtained the optimal maintenance schedule, we can easily fix some maintenance events manually (equivalent to the “Manual” scenario in the Cloud Pak for Data DO Dashboard, discussed above) by creating a new scenario and specifying the events:
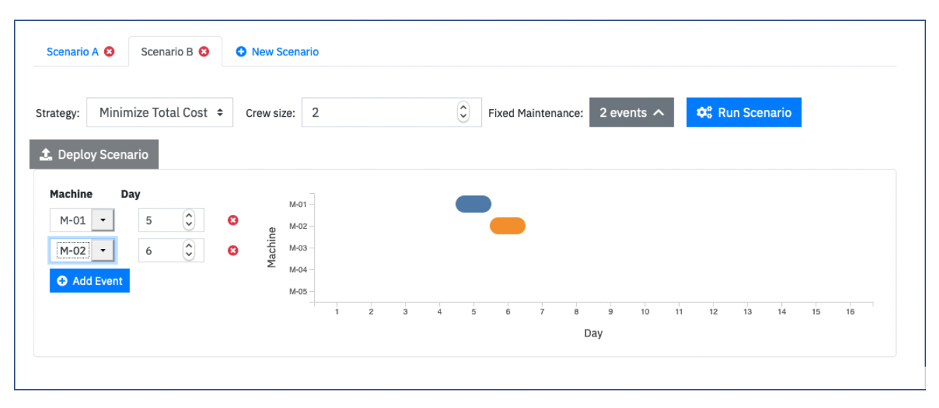
Figure 14: Specifying some maintenance events manually
Solving the scenario one more time and comparing the results to the original one confirms that the optimal solution is better than the manual one (cost of $2,279 vs $2,471):
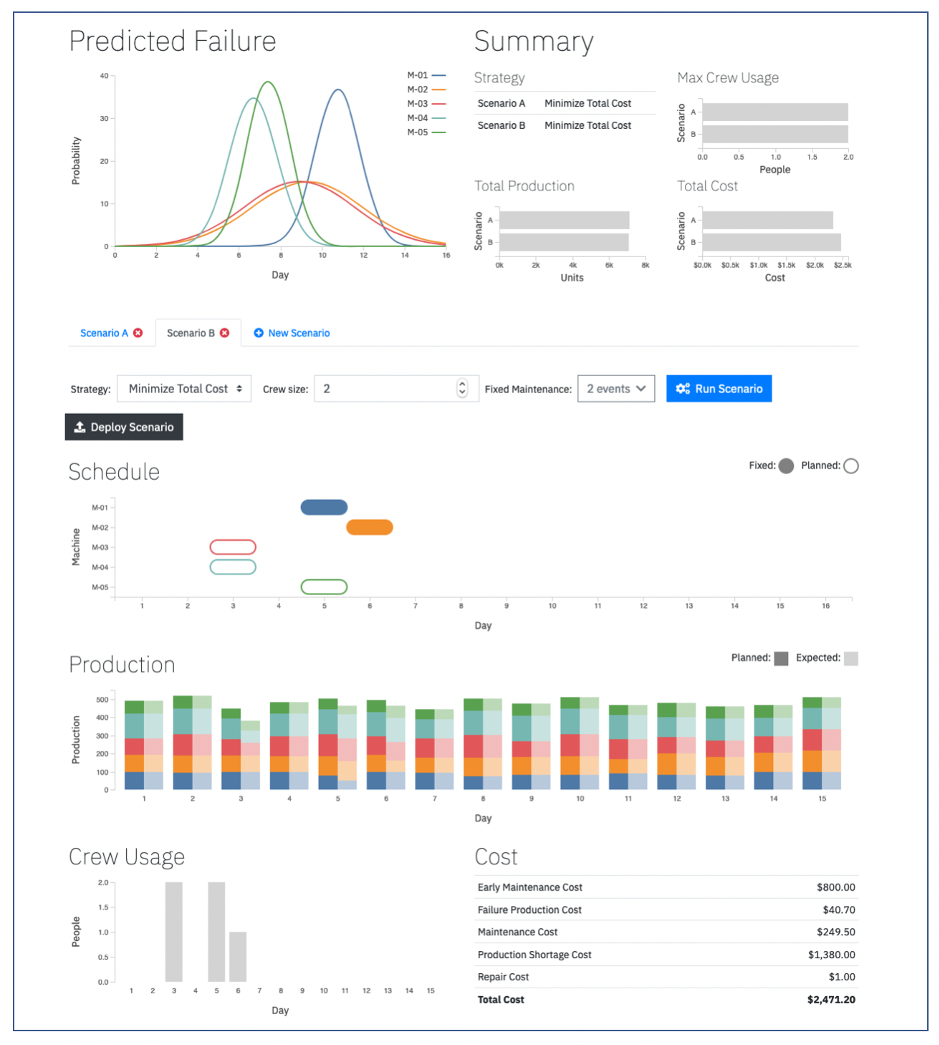
Figure 15: Solving the Manual scenario (using a simple heuristic to schedule maintenance) and comparing the results
Of course, this is just a simple example of a demo implemented using IBM Cloud Pak for Data, Decision Optimization, and Node.js. The possibilities are infinite as far as what you can do and how you can present information in your own app.
Summary
Predictive maintenance scheduling is a key area in many asset intensive industries. Creating an optimal maintenance schedule is a challenging problem that is best tackled using the combined power of machine learning and decision optimization. While machine learning can take into account all available data and past history to predict the likelihood of failure for each machine, decision optimization can take it a step further and generate a schedule that is optimal for a set of machines, subject to limited resources, other constraints and dependencies, and optimization metrics. Not only does optimization offer valuable insights but it also generates an actionable schedule or plan.
The benefits of using a good predictive maintenance solution can be significant and include but are not limited to:
- Lower cost and higher customer satisfaction
- Reduced planning/scheduling time and effort
- Improved asset reliability and availability
- Improved operational efficiency of individual assets
According to a study by the World Economic Forum and Accenture, the business value of a predictive maintenance solution is:
- -12% scheduling costs
- -30% maintenance costs
- -70% unplanned downtime
There are many Industry Accelerators today and more coming throughout the year. The best part: these are absolutely FREE and available for your consumption on the IBM Data Science Community .
Industry Accelerators run on the IBM Cloud Pak for Data platform. To find out more about the capabilities of the platform and to start a free trial, visit: https://www.ibm.com/products/cloud-pak-for-data
Interested in learning more about the Industry Accelerators but need a little help in getting started? The DSE team can plan, co-create and implement a project with you based on our proven Agile AI methodology.
Visit: http://ibm.com/community/datascience/elite
#GlobalAIandDataScience#GlobalDataScience#Hands-on#Hands-on-feature#Highlights-home#News-DS