We've still have latency problem every business day on regular basis as I described above.
"staging_store_can_run_independently"=true.
And these settings can cause log reading performance's degrading due to using private scraper.
"staging_store_can_run_independently"=false if each subscribtion has latency of between 5 and 6 hours?
Original Message:
Sent: Thu June 23, 2022 07:37 AM
From: Robert Philo
Subject: IIDR Log reader bottleneck: latency issue
Hello
You probably need to look at the log reader and parser I/O metrics in the subscription performance perspective. Possibly an increase in the memory allocated to CDC might reduce any file I/O.
Regards
Robert
------------------------------
Robert Philo
Original Message:
Sent: Thu June 23, 2022 05:20 AM
From: Anuar Akhsambayev
Subject: IIDR Log reader bottleneck: latency issue
Hi Robert!
Thank you. We will look into it.
I also did a simple analysis how long CDC read and parse archived logs on basis of one day history.
As you can see in an image below the highest period when a lot of log files are generated is between 06 AM and 07 AM: ~300 logs are generated everyday at this time and log reading latency starts rising from this time.
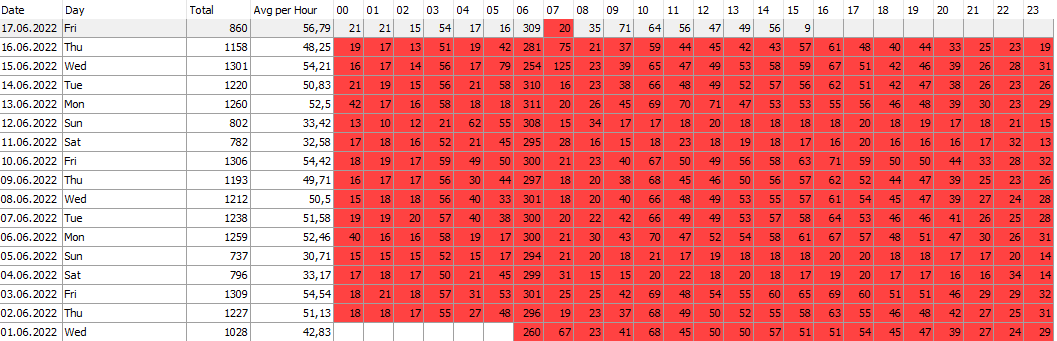
I uploaded log processing statistics from Single Scrape events in Management Console and collected them into file to analyze how latency is going on.
If you look into images below you could see that an average "log processing duration" is always around 40-50 seconds depending on log file's size. At first sight it is obvious that IIDR couldn't handle with lots number of log files which had been already generated and collected. CDC log reader read and parse them one by one and latency rise up (starting at 6:00 AM) to 3.5 hours and goes down back and reach 0 afternoon (at 15:50 PM). For example, CBS_1_2147206_844335453.arc file (was created at 22.06.2022 6:58:00) processing has been completed at 22.06.2022 10:35:00.
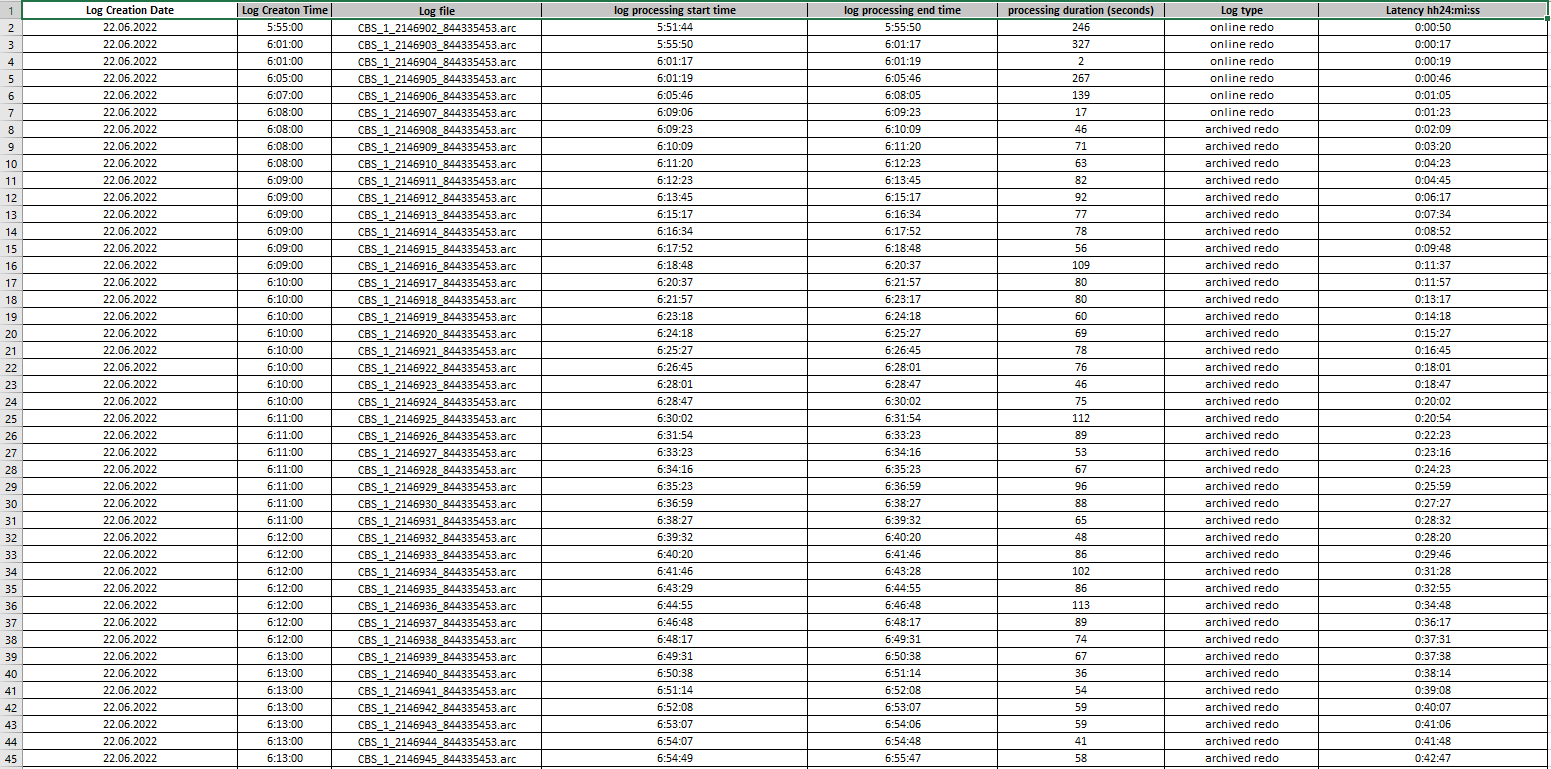
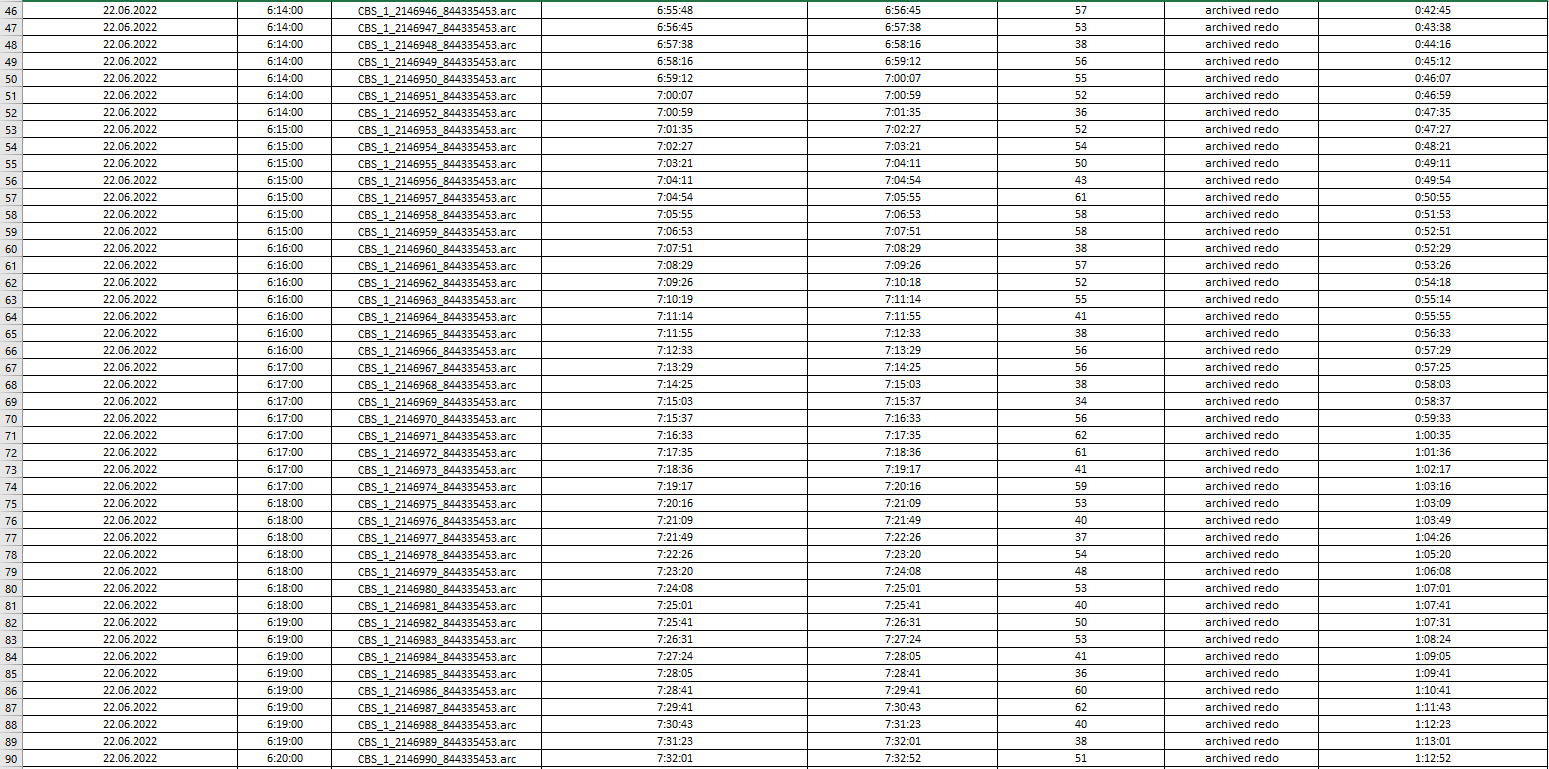
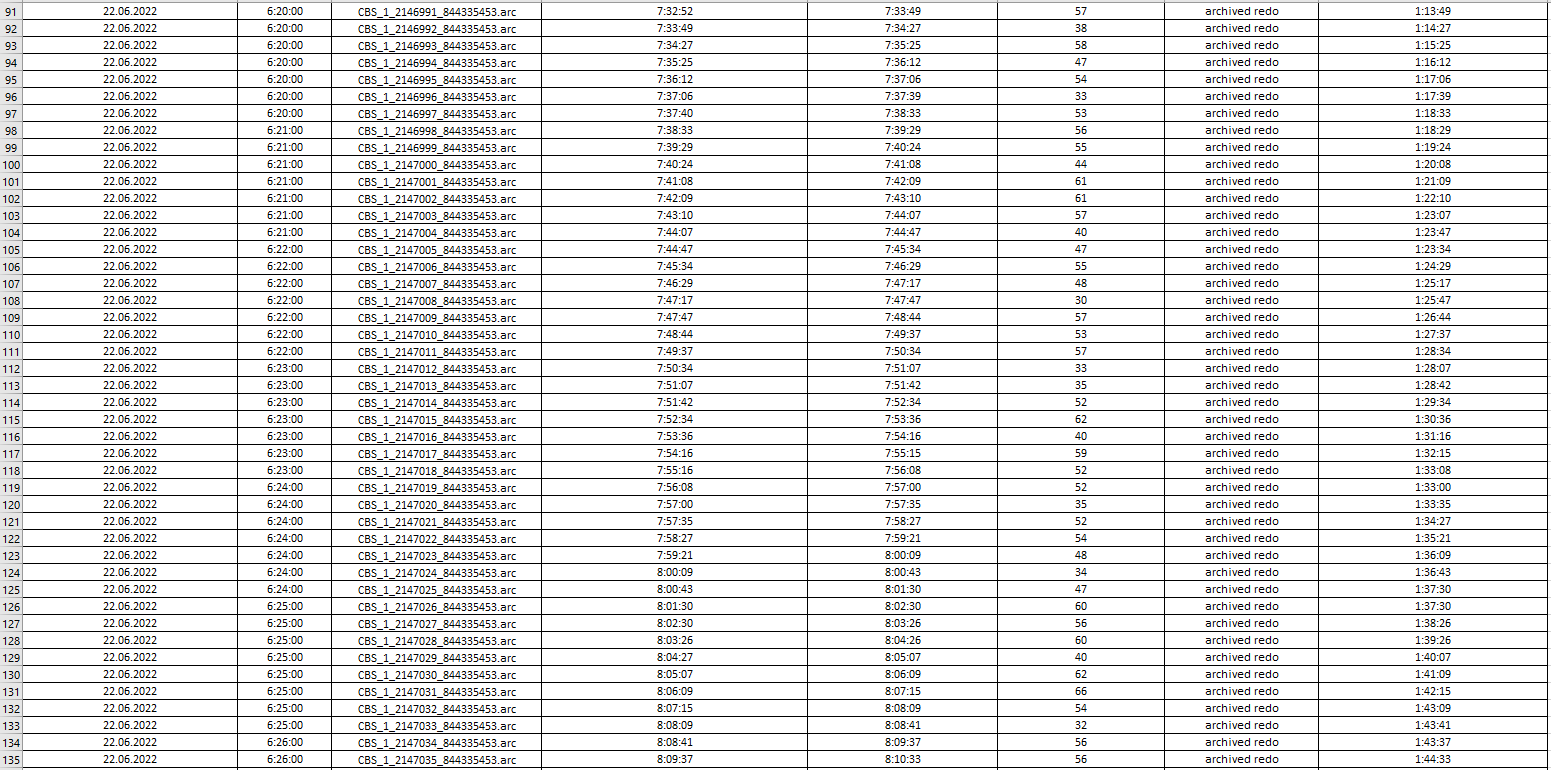
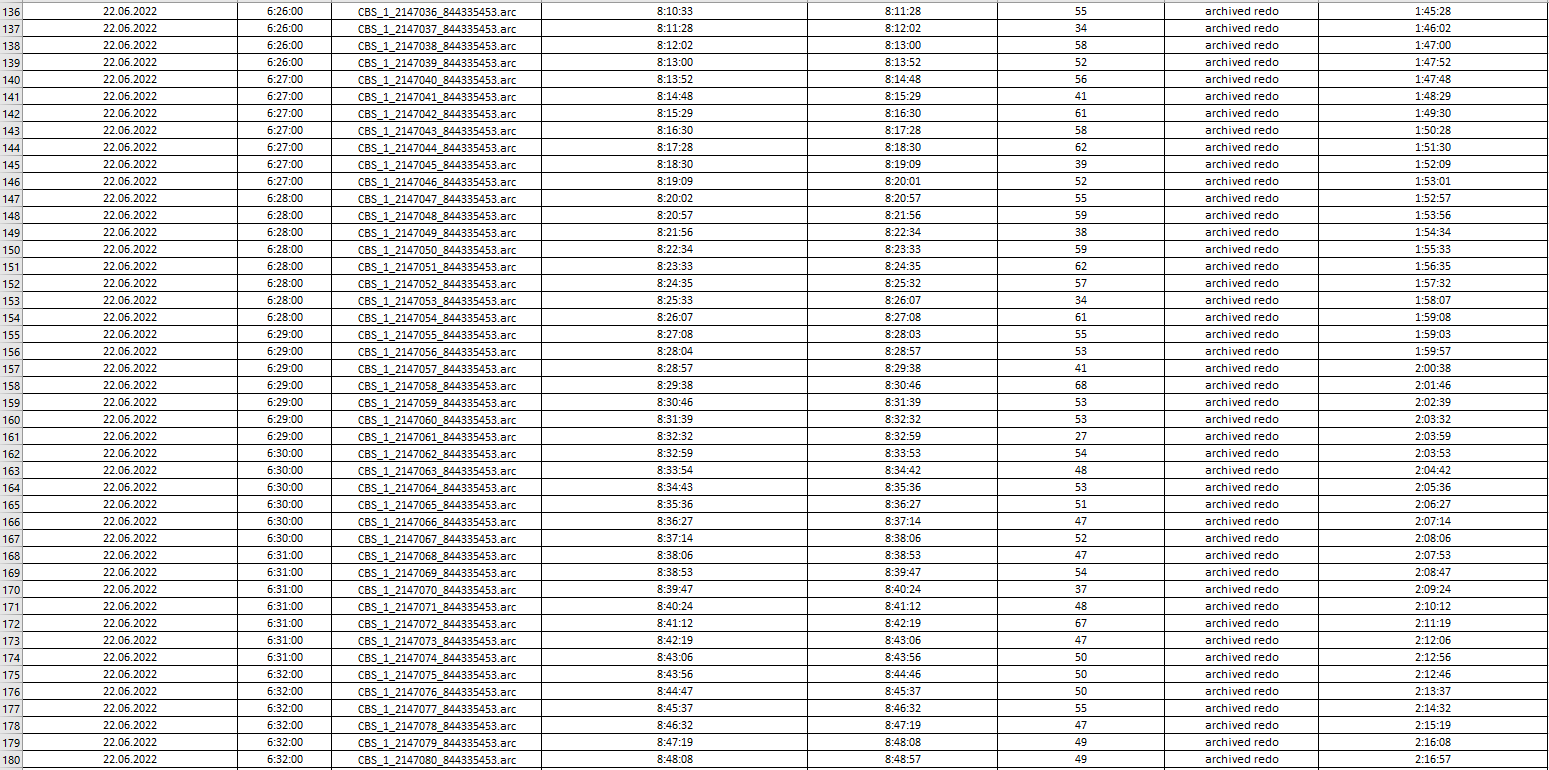
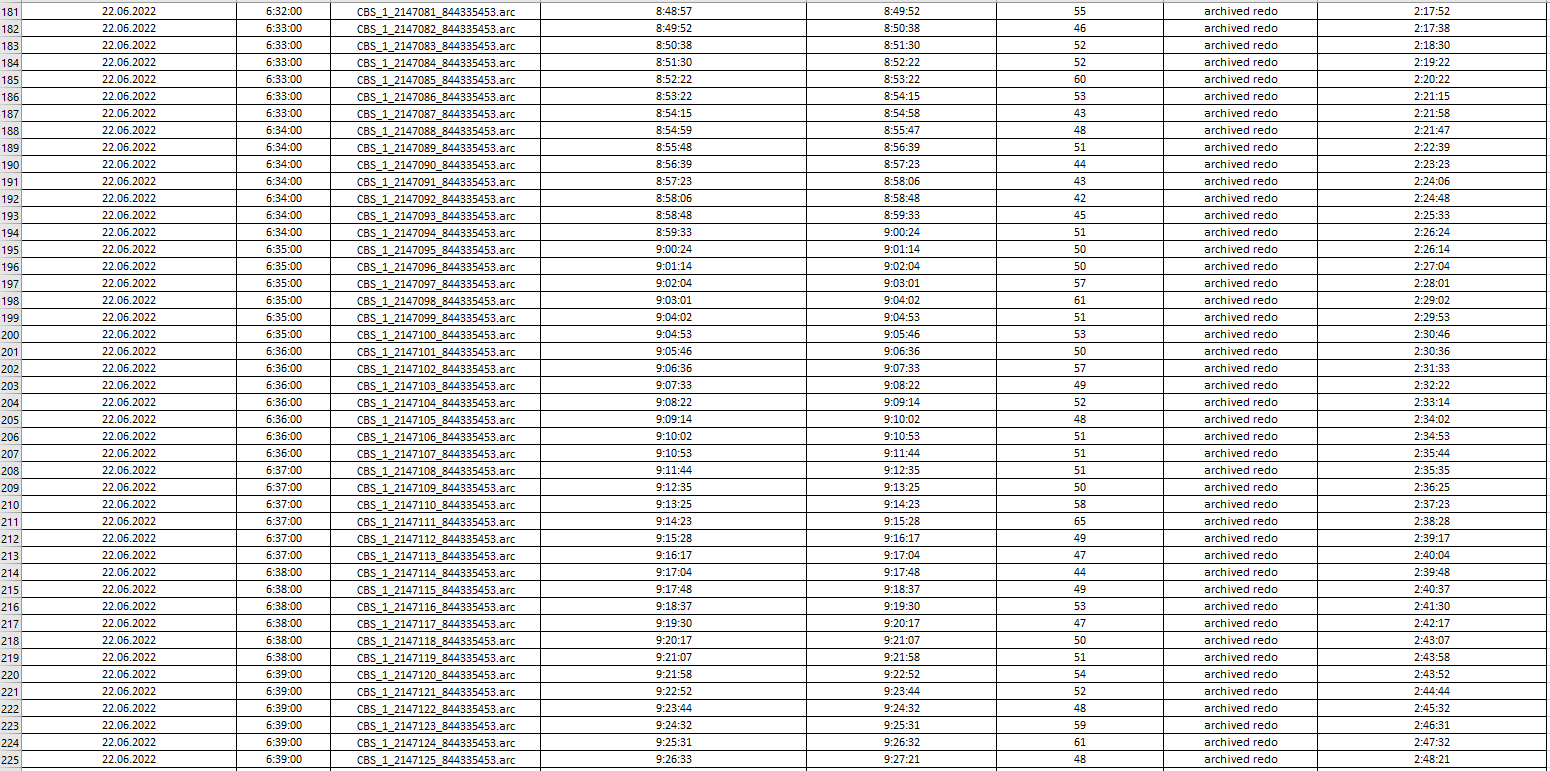
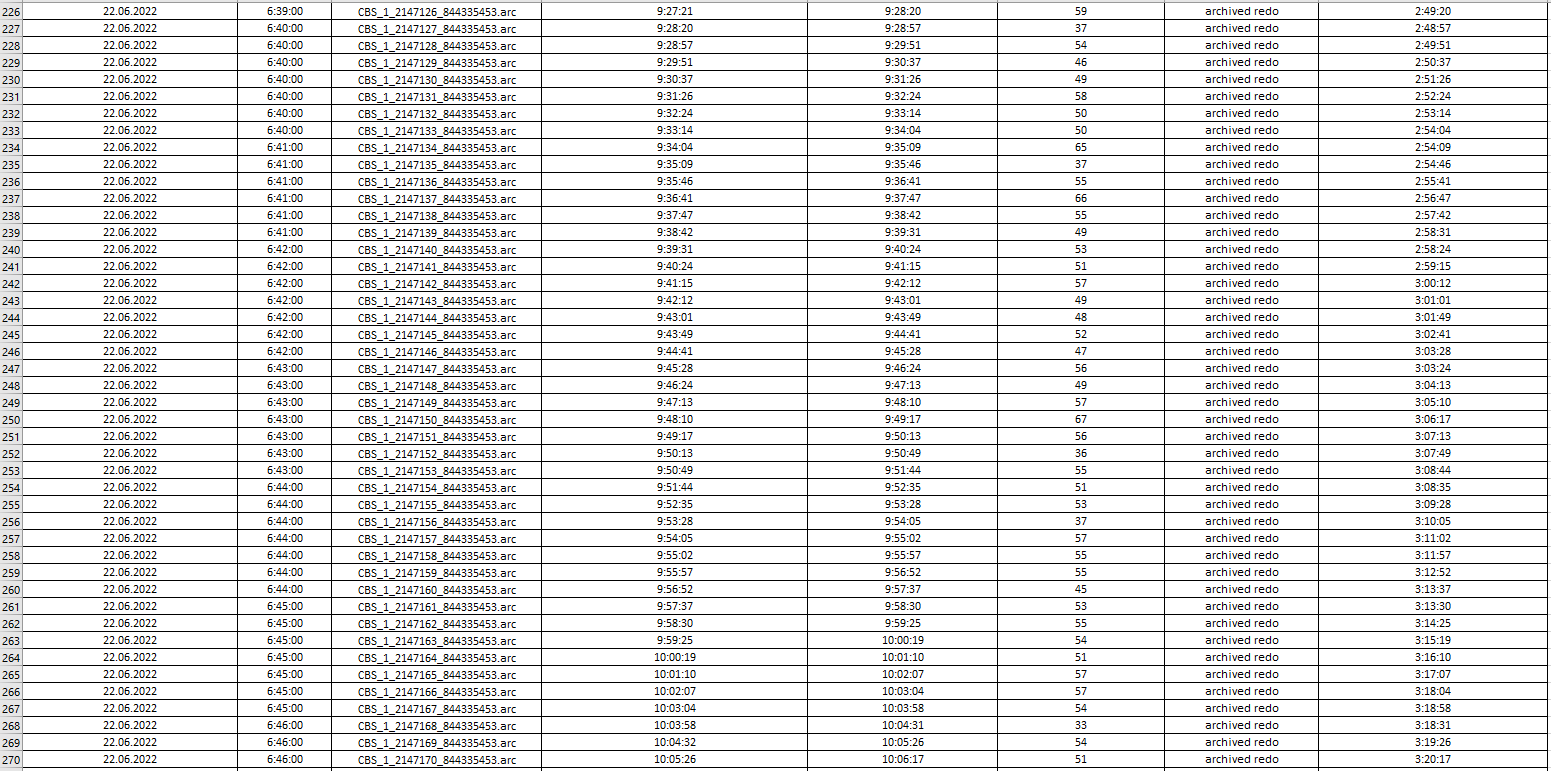
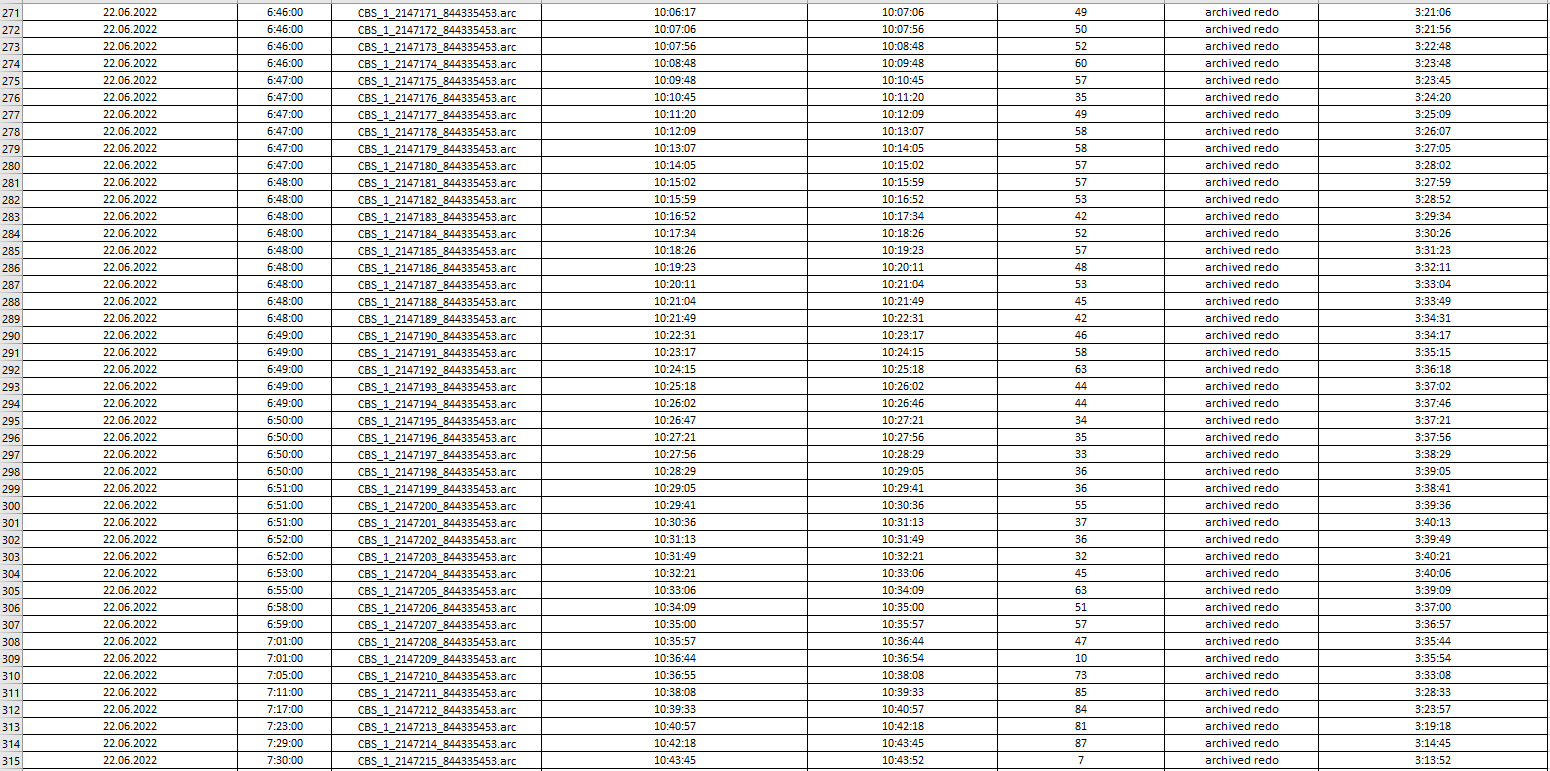
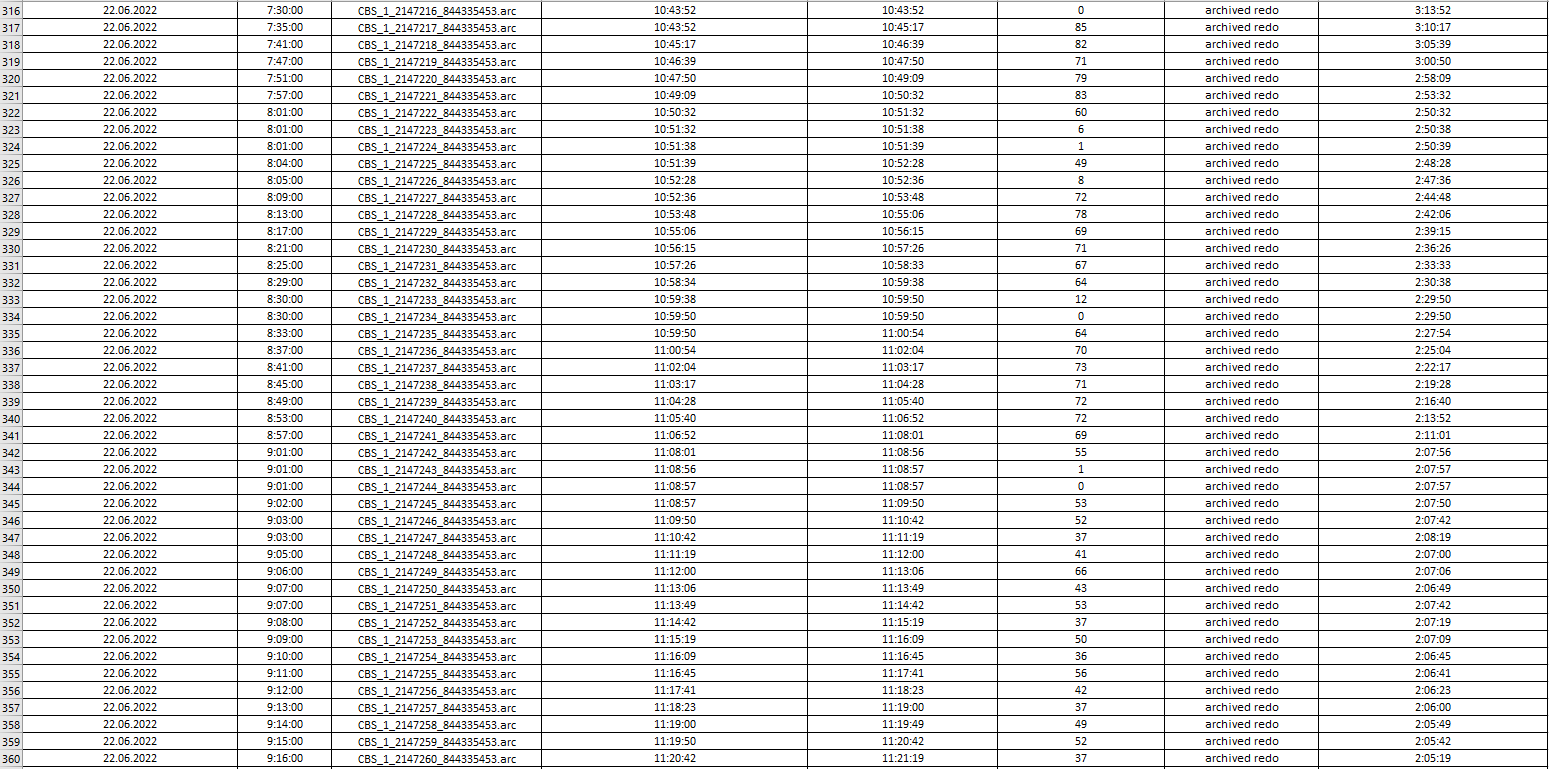 ....
....
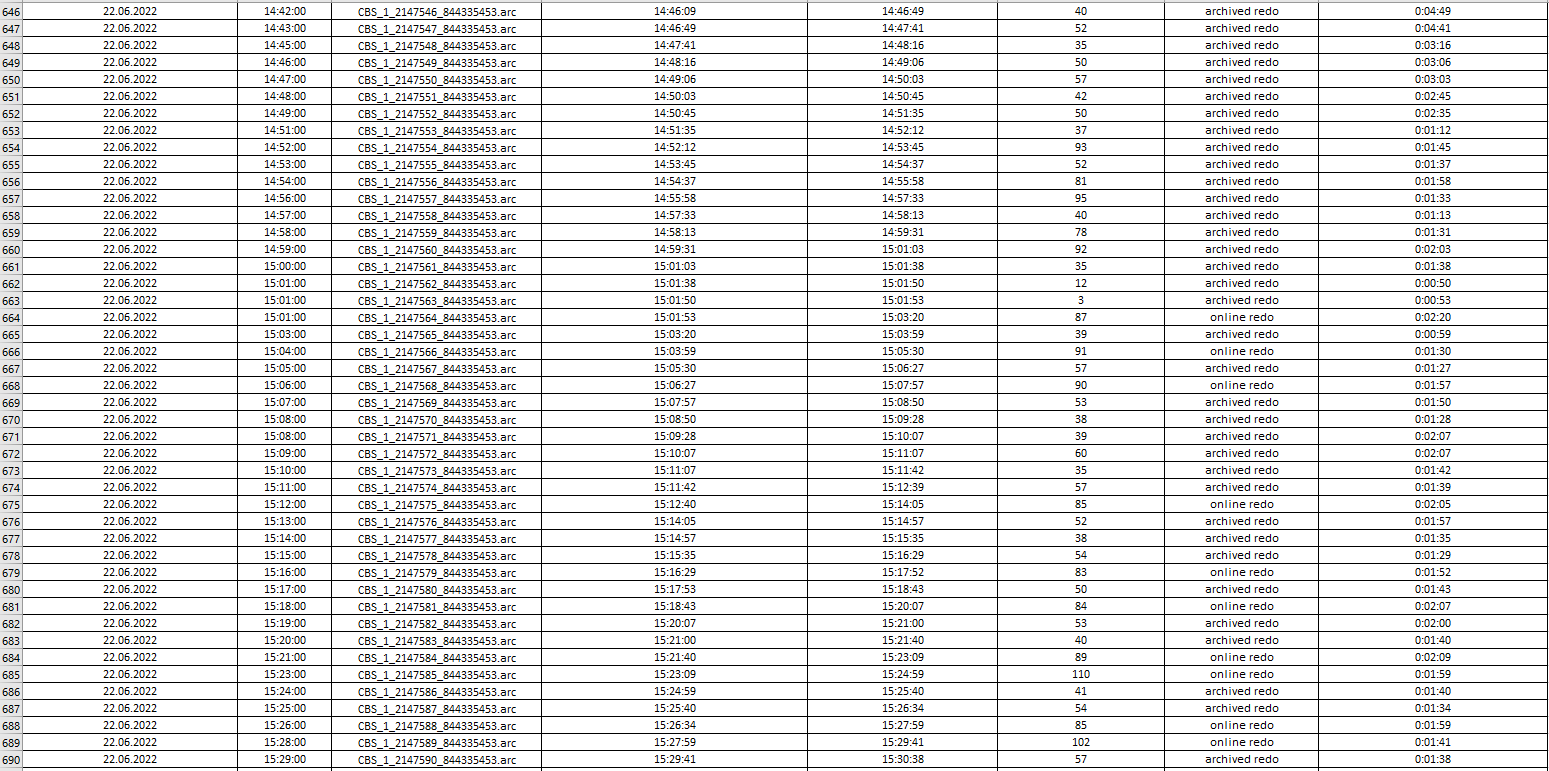 .
.
And this issue reoccur everyday at the same time.
About NFS: we checked read/write speed of log files on source and remote server. Results are almost the same.
For example, by dd command:
dd if=/CBS/arch/CBS_1_2047896_844335453.arc of=/dev/null bs=256k
4318+1 records in
4318+1 records out
1132132352 bytes (1.1 GB) copied, 10.0693 s, 112 MB/s.
Best wishes,
Anuar
------------------------------
Anuar Akhsambayev
Original Message:
Sent: Thu June 23, 2022 02:36 AM
From: Robert Philo
Subject: IIDR Log reader bottleneck: latency issue
Hello. I suspect your NFS mount is the cause of the log reader bottleneck. I suppose you could test a simple read of the Oracle redo and archive logs on the database server, and then on the CDC server via the NFS mount point to establish if there are any significant differences.
Regarding contention between Oracle and CDC over writing and reading the redo logs concurrently, one option you may have is to switch to archive log only mode. There will be latency of course as CDC can only start to replicate transactions once they have been archived. On the other hand in a high volume environment the system will probably archive the redo log in a few minutes and a few minutes' latency might be more acceptable than the many hours you are current experiencing. Archive log only mode will also give you more configuration options as you can consider duplexing the archived logs (optimising the second stream for CDC access perhaps) or even log shipping.
One comment I have seen : "Oracle's recommendation is to store all logs and data files on non-cached files systems for high volume environments. This is because Oracle implements its own caching, and therefore additional caching by the OS file system is not required, and could lower performance if enabled. However we do recommend storing archive logs can benefit from a separate cached file system which is not shared with the online logs. This way, disk access by CDC does not affect Oracle log writing throughput. This is because they are only written once and never read back by Oracle unless it is recovering during backup/restore whereas CDC benefits from archive logs being stored on a cached file system as this allows CDC to read the archive log out of cache if it was recently written.
Online logs are a source of disk contention in that both Oracle and CDC are accessing them simultaneously. Therefore, the operating system must share the underlying device between reader (CDC) and writer (Oracle). In this case, if the physical disks do not have sufficient IO operations per second, both products will be constrained. Oracle will find that writes will queue and take longer to complete, and CDC will stall on disk reads. So you may even consider having flash drive."
You can also refer to the following IBM documentation:
Disk contention for the CDC Replication log reader
If the NFS mount point is the cause of the problem and you need low latency (a few seconds) then you may need to consider installing CDC locally on the database server.
Hope this helps
Robert
------------------------------
Robert Philo
Original Message:
Sent: Tue June 21, 2022 10:59 AM
From: Anuar Akhsambayev
Subject: IIDR Log reader bottleneck: latency issue
Hello, Robert!
Thank you for your answer.
1) What is your source database type?
Both source and target database type is Oracle.
2) Is your source engine installed on the local database server or cluster, or is it installed remotely on a separate server?
Source engine is installed on a separate server. Source engine reads archived/redo logs remotely by NFS mounted on server where source engine is installed.
If your source engine is remote, then comms between the source database server and the source CDC server could well be the cause of the bottleneck.
We'll check it.
If your source engine is Oracle there might be contention between CDC reading the log and Oracle writing the redo log.
How can we test/check it or should we increase server resources?
Best regards,
Anuar
------------------------------
Anuar Akhsambayev
Original Message:
Sent: Tue June 21, 2022 10:32 AM
From: Robert Philo
Subject: IIDR Log reader bottleneck: latency issue
Hello
1) What is your source database type?
2) Is your source engine installed on the local database server or cluster, or is it installed remotely on a separate server?
If your source database is DB2 LUW or DB2 on z it could be that the log reader is the bottleneck because the archived transaction logs are having to be retrieved from secondary storage (.e.g tape) as they are no longer on-line.
If your source engine is remote, then comms between the source database server and the source CDC server could well be the cause of the bottleneck.
If your source engine is Oracle there might be contention between CDC reading the log and Oracle writing the redo log.
Regards
Robert
------------------------------
Robert Philo
Original Message:
Sent: Tue June 21, 2022 12:22 AM
From: Anuar Akhsambayev
Subject: IIDR Log reader bottleneck: latency issue
Hi, everyone!
Does anyone face a problem of latency in replication/mirroring tables when a lot of archived log files are generated at source database. Latency goes up to 4-6 hours and we get data too late due to this problem. Latency issue occurs every business day (from Monday to Friday) when large data are generated. IIDR Management Console performance statistics show that problem with log reader (bottleneck due to log reader). Who did solve this problem or made IIDR to read logs faster?
------------------------------
Anuar Akhsambayev
------------------------------
#DataReplication
#DataIntegration