Introduction
A Product Information Management (PIM) solution provides the capability to collect, manage and enrich the products all in a single place. PIM provides improved data quality and faster time to market, but many organizations end up having unmanaged duplicate data. One of the main reasons for this is, the data coming into the system by multiple users and from multiple sources, leading to data inconsistency and inaccuracy.
Data duplicates are a common business problem, causing many wasted resources and leading to bad customer experiences. To handle this problem the PIM application must have a system in place that can identify the duplicate record as soon as the record enters the application and flags the user to take appropriate action on the data.
IBM Product Master provides out-of-the-box Suspect-duplicate processing feature. This feature eliminates redundant data in a data set, by identifying and removing extra copies of the same data, leaving only one high-quality data set to be retained. Suspect duplicate processing is the process of searching, matching, and creating associations or suspects between the master data and incoming new data. Associations are made based on how well the entered data matches with the master data and tagging the new data as a duplicate of an existing master data, which is a golden copy.
The Suspect duplicate processing feature ensures good quality of a single accurate record of the data. High-quality data is critical, and it is important to consider how the users can efficiently manage that data.
Configuring Suspect duplicate processing
Suspect duplicate processing can be configured on any catalog by using simple steps and handling most of the configurations automatically within the application.
· Trigger the Suspect duplicate processing script to create the Operational catalog, Look up table and import of the Suspect duplicate processing algorithms
· Configure the “Minimum match” and “Response size” parameters in the Look up table
· Configure the “Workflow” details to handle the Suspect duplicate processing
Based on the configurations, if the minimum match is set to 30% and response size is set to 3, then if the newly entered data matches for more than 30% of the attributes it is flagged as a duplicate of a master record and up to three matches are available to the user for comparison.
Users can then take appropriate action on the data. If the user marks an entry as a duplicate, a record gets created in the “Operational Catalog” that is tagged as a duplicate to the entry in the “Master Catalog”. If the user marks an entry as a “No Match” then the entry is directly created into the “Master Catalog” and is considered as the “Golden Copy”. Thus, ensuring that there is always only a single accurate record of the entry.
Automating Suspect duplicate processing
Users can choose to have an automated suspect duplicate processing in place where the match happens automatically based on the matching score or choose to manually select the match and mark the product entered as duplicate or a golden copy. The process also enables the user to merge any data from the duplicate to the master data ensuring the master data has complete information.
The following example illustrates data in systems that do not have a de-duplication process in place versus a system that runs a suspect duplicate processing on data before the data is stored for consumption
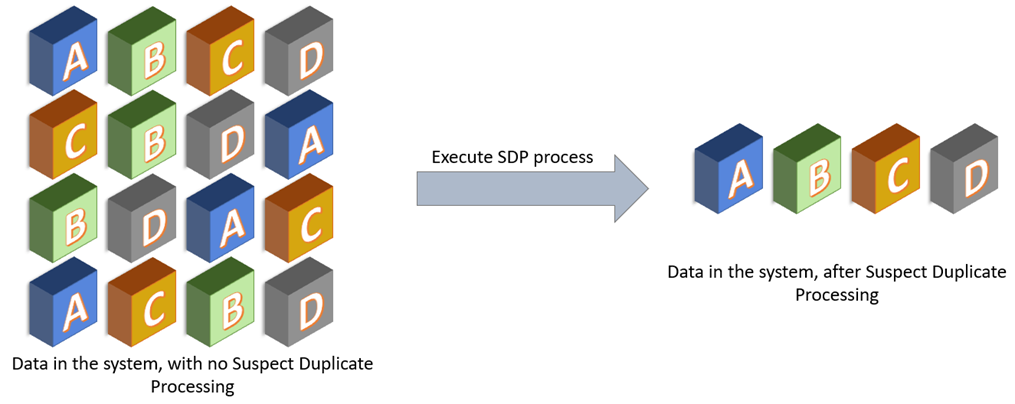
Sample - IBM Product Master Suspect duplicate processing:
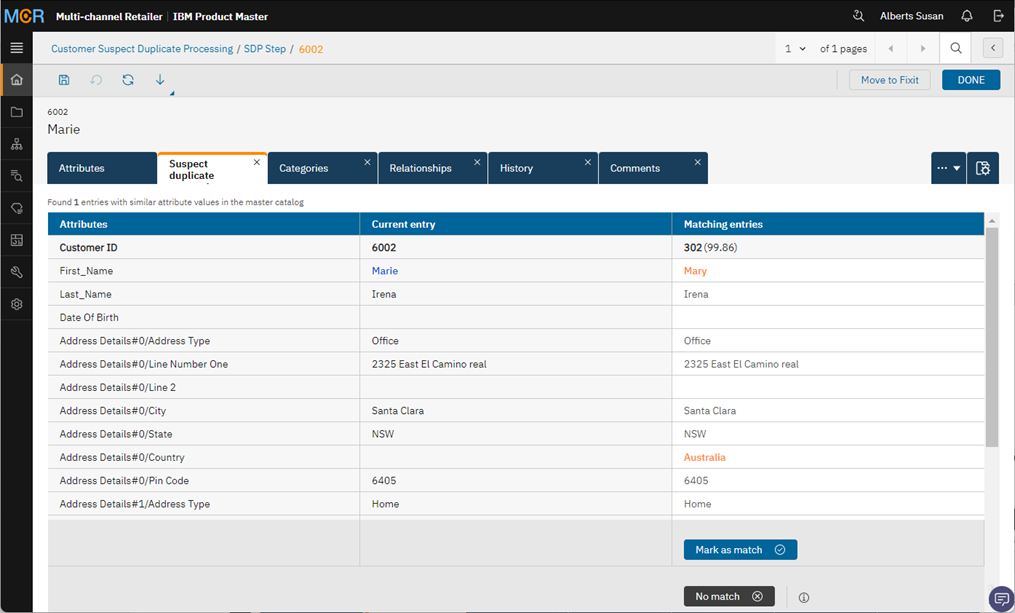
Following is an example from the IBM Product Master running a Suspect duplicate processing process on the new entry, and the confidence score of the newly entered record with an existing record is 99.86%. The user can mark the record as a match, and once done can merge any attribute data from the new record to the master record, like a name change or an address change might be required on the master data. So now the PIM has 1 single record for Mary instead of two records due to Suspect duplicate processing.
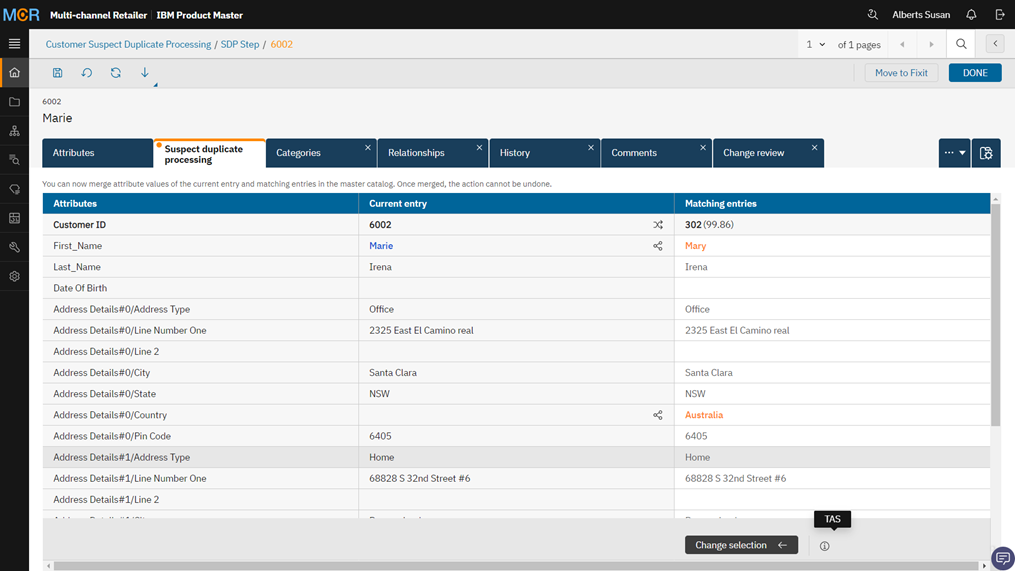
The following illustration displays and example where a user can “Merge” data by selecting “Mark as match”, thus ensuring that the final copy of data in the system is a true “Golden copy” of the data.
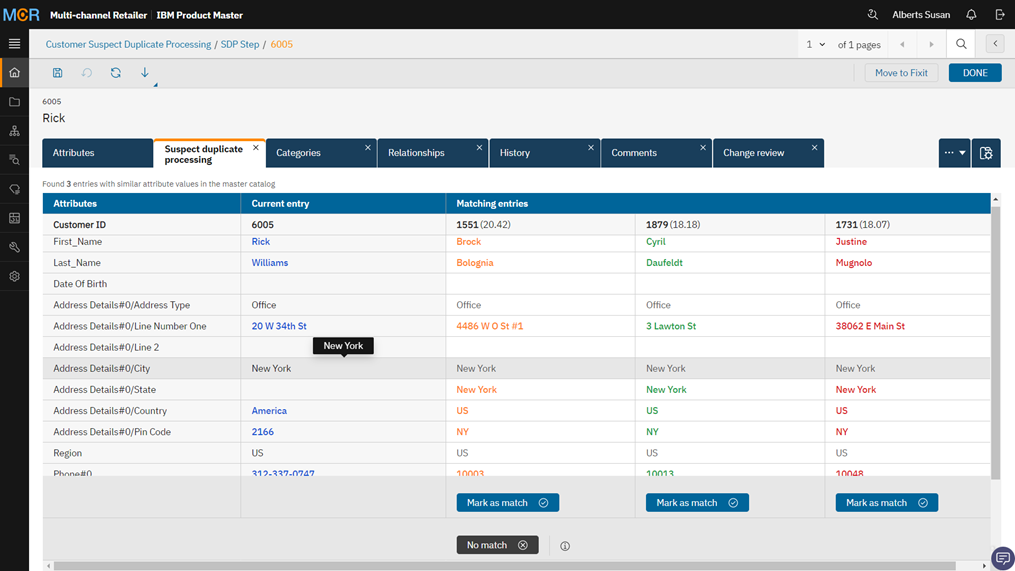
Similarly, the following illustration displays an example where the new entry can easily be marked as a “Golden copy” since the matching percentage is low and once user compares the attribute values, the user can conclude that the entry needs to be marked as a “No match”
Summary
IBM Product master’s out-of-the-box Suspect duplicate processing feature thus ensures to provide a good high-quality single accurate record for each product. The process provides an easy-to-use interface to maintain a consistent and single source of truth of the data. Suspect duplicate processing is the process of searching, matching, and creating associations or suspects between the master data and incoming new data, ensuring that the data which is finally available in the Master catalog is a single accurate and of good quality.
#data-highlights-home