 Photo courtesy of IBM Brand Image Library
Photo courtesy of IBM Brand Image Library
Data fuels analytics, machine learning and AI. Today’s data is becoming more diverse, distributed, and dynamic across hybrid cloud environments. The need for quality data, and today’s complex information architecture calls for a highly performant data integration solution.
DataStage SaaS is Next Generation DataStage on Cloud Pak for Data SaaS, architected for SaaS and the industry leader in data integration. DataStage’s performance starts with data connectivity. DataStage makes use of cloud-native connectors that make connecting to disparate data sources easy — simplifying data integration and freeing you to focus on designing data flows and deriving insights, instead of figuring out data connection configuration and installation.
How it works
DataStage supports many different types of data connectors.
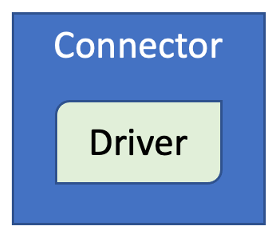 Connector relying on a 3rd party driver
Connector relying on a 3rd party driver
In data connectivity, generic JDBC-ODBC is commonly used with individual database systems’ native drivers. JDBC-ODBC acts as a medium to native database library to connect to and query individual database systems. It provides simple connectivity to data sources and enables a wide breadth of connection to various data sources.
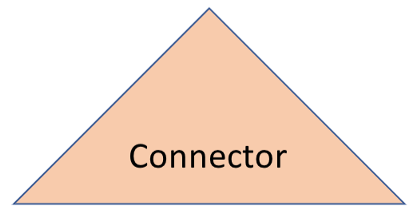 Native connector using data source’s API
Native connector using data source’s API
In addition to JDBC-ODBC connectors, DataStage also supports native connectors. DataStage native connectors use data source API to directly call client-side libraries to the individual database system. DataStage native connectors are dedicated connectors that support specific needs of data integration — high performance and additional features.
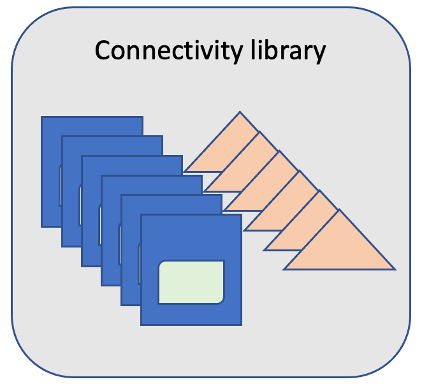 DataStage supports both generic and dedicated connectors
DataStage supports both generic and dedicated connectors
DataStage native connectors unlocks powerful data integration features such as bulk load which is a must-have when moving vast amounts of data. It also eliminates the hassles of data connection by providing ready-to-use connectors. In solutions where dedicated connectors are not provided, the user is responsible for the maintenance of required drivers and relevant modules — users must install the native driver, install database client libraries, configure database connections, and set-up additional environment variables. This could be further complicated for multi-cloud infrastructure which require additional steps to ensure drivers are installed correctly on Kubernetes pods and aren’t overwritten at runtime. Moreover, the user is responsible for determining compatibility, and for setting-up installs and patches when needed with every version release of the database system.
With DataStage native connectors, you get out-of-the-box data connectivity to enterprise applications and data sources such as:
- Cloud hosted sources
- Relational databases and NoSQL databases
- Mainframe databases
- Enterprise and web apps
- Real-time, streaming, and files
Data Integration preps you for AI
You can then use DataStage native connectors for to preview data and take data visualization to the next level by plotting information on a variety of charts and graphs. Then use built-in DataStage transformation functions to standardize, cleanse, and validate data. Dynamic schema and metadata discovery allow you discover relationships among data sources, define migration rules, and understand relationships.
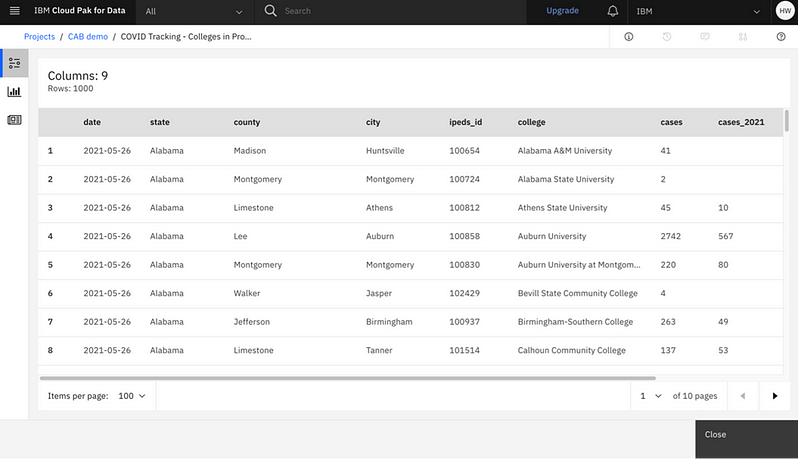 View data with DataStage SaaS
View data with DataStage SaaS
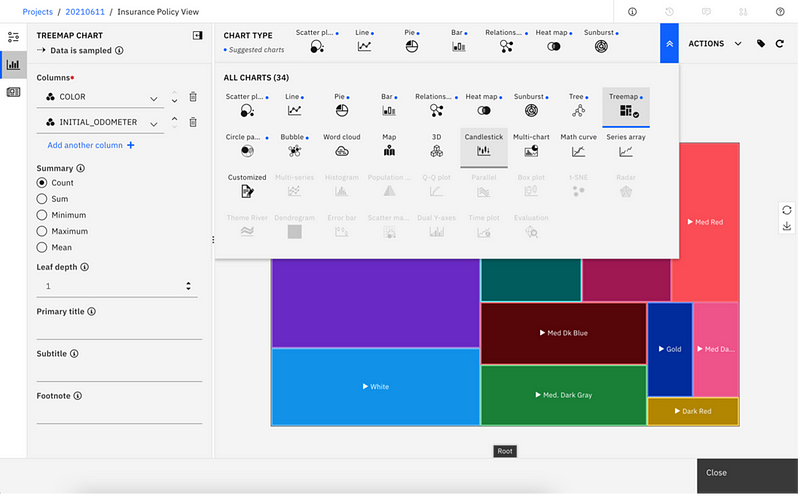 Data visualization (treemap) with DataStage SaaS
Data visualization (treemap) with DataStage SaaS
DataStage native connectors also support deep integration such as bulk operations and offer automatic workload balancing with best-of-breed parallel engine. Deliver massive amounts of data in real-time with superior performance to your business applications through bulk data delivery (ETL), virtual data delivery (federated), or incremental data delivery (change data capture). Multi-cloud scalability, elasticity, and runtime execution capabilities seamlessly match your information volume and workload requirements. And common canvas on Cloud Pak for Data makes for easy integration with IBM’s data and AI ecosystem.
With Next Generation DataStage, your business can access and use data in new ways to drive innovation and deliver business results faster, deriving more value from complex heterogeneous information and creating a unified foundation for enterprise information architectures.
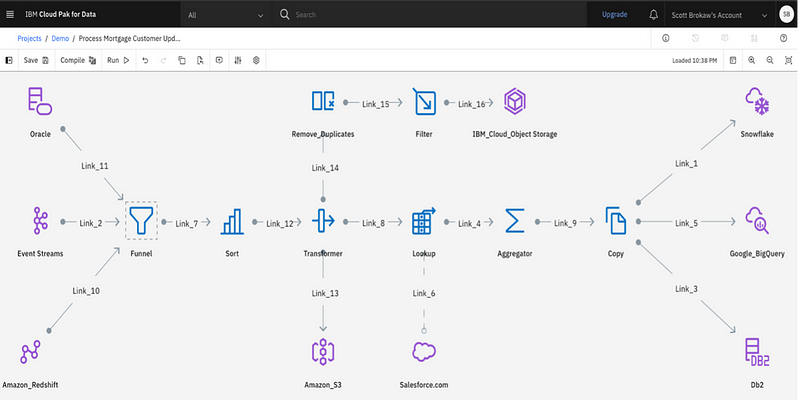 Design data flow with DataStage SaaS
Design data flow with DataStage SaaS
Conclusion
Data Integration allows you harness the power of data to build data science and artificial intelligence capabilities. Data Connectivity is a critical component of data integration. DataStage native connectors are dedicated, custom connectors with high performance and advanced connectivity features.
DataStage-native connectors simplifies connecting to data sources, unlocks built-in DataStage data discovery, transformation, visualization features, enables superior performance and unlimited scalability in data delivery, preparing your data for analytics, machine learning, and AI.
For more details on creating and using a DataStage native connector, visit IBM Developer Community Using Db2 native connectivity in IBM DataStage SaaS. To learn more about DataStage on IBM Data Fabric with Cloud Pak for Data SaaS, visit IBM DataStage.
#DataIntegration