Written by Ronald Nordhausen.
Your enterprise is using IBM Streams as platform for real-time data analytics and processing. To integrate AI capabilities to your enterprise’s analytics applications, a data scientist has created ML (Machine Learning) models to get new insights out of the real time data. Now your task as a Streams SPL developer, is to integrate these models into a Streams application.
This article describes how you can integrate PMML models into your real time analytics application by using the new PMML toolkit (com.ibm.streams.pmml). The integration is illustrated on a sample scenario.
In contrast to the Streams SPSS toolkit provided with the SPSS product, the PMML toolkit scores only PMML models. Use the SPSS toolkit to score models created using SPSS Modeler.
Table of Contents
Introduction to PMML
PMML means Predictive Model Markup Language. It is defined by the Data Mining Group (DMG) to allow simple transfer of models between model creation and scoring tools (and between vendors) so that you can use the tools of your choice.
For an introduction you may read PMML at Wikipedia.
The specification is available at PMML specification at DMG.
A PMML model is created by a model creation tool where the Data scientist chooses a certain algorithm, fields of interest as model input, and the output features. Processing the algorithm on a training data set will result in the PMML model we are talking about. It’s an XML file containing the complete description of a set of input data (names, types, valid content) to be processed by certain algorithm with certain parameters and the resulting set of output features.
This article is not about creating PMML models. But some aspects of PMML are of interest for a developer who shall integrate PMML model scoring in his application.
PMML specification supports the following model types:
The PMML specification allows putting multiple models in one file. It uses the MiningModel to specify how they should be used.
Although integrating PMML model scoring into an application doesn’t require knowing how to create a PMML model or understand the complete PMML specification, basic knowledge of some parts of the model is necessary. Specifically, you need to know the model’s input and output fields, as well as the target fields.
What input data does the model expect?
See PMML specification: DataDictionary and MiningSchema
The DataDictionary describes the data fields (name and type or even values) being used in the model file, in one or more models.
The MiningSchema defines the fields and their usage for a certain model in the file. These mining fields can be fields from input data, from transformations or models being processed before.
As a quick rule for single model without transformations one may look at the MiningSchema element and check for all fields having usageType=”active” and which also appear in the DataDictionary. These fields are the ones which have to be provided in the input data. The type of these fields is taken from DataDictionary. (We’ll see a sample below.)
What does a model predict?
These are the fields in MiningSchema which have usageType=”target”or usageType=”predicted”. But not all algorithms have a target.
Which output does the model provide?
See PMML specification: Output
A special Output element exists in the specification which describes explicitly the output fields being generated by the model: name, type and feature it contains. A feature is a scoring result value being generated by an algorithm. Scoring does not only generate the feature “predictedVale” (this is the one we expect) but also a bunch of other general or algorithm specific features as “probability”, “entityId”, “affinity”.
However, the Output element is not required and there is no default specified which of these features shall be generated additionally to the “predictedValue”. This depends on the vendors.
But if the Output element is defined then exactly this output has to be generated.
Is it that easy?
Yes and No, this was the quick explanation, it is OK for a single simple model defined in a PMML file. Having multiple models in one file or using all functions PMML allows will require you to dive deeper to get the information about input and output data.
Is there any tooling support?
Fortunately there is tooling support, model creation tools will show the relevant information of input data, target fields or output fields as they are defined within these tools. But these tools are used by the Data Scientist. So the Data Scientist should give appropriate information to you as the developer. But if you get a model without this information you have to look into the model XML file by yourself.
If you work in Watson Studio in IBM Cloud or Cloud Pak for Data, you can import a model XML file to your project to see the model details: the input fields and their type (but not the allowed content) and under “Label column” the target fields and types.
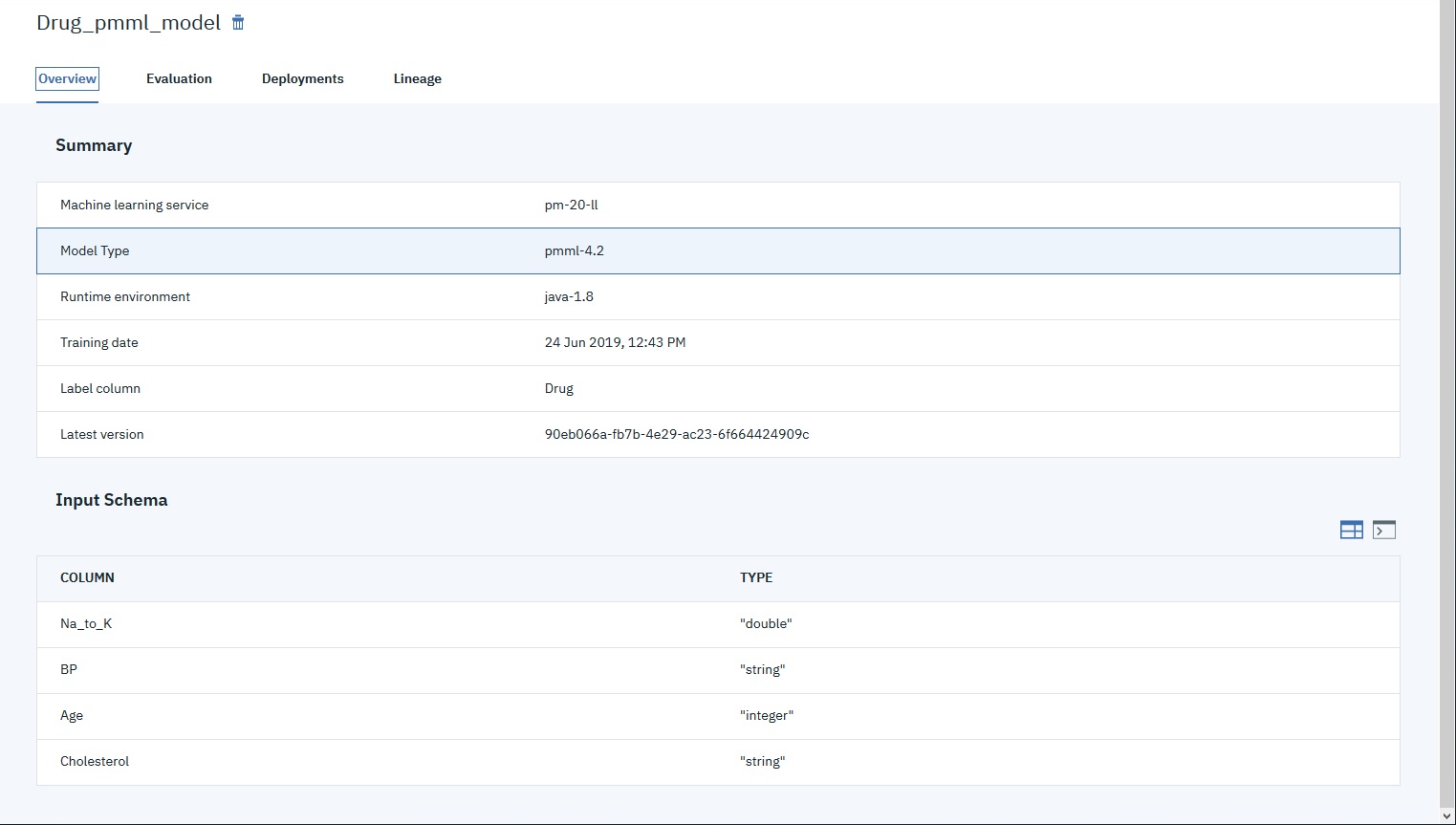
PMML model IBM Watson Studion in IBM Cloud
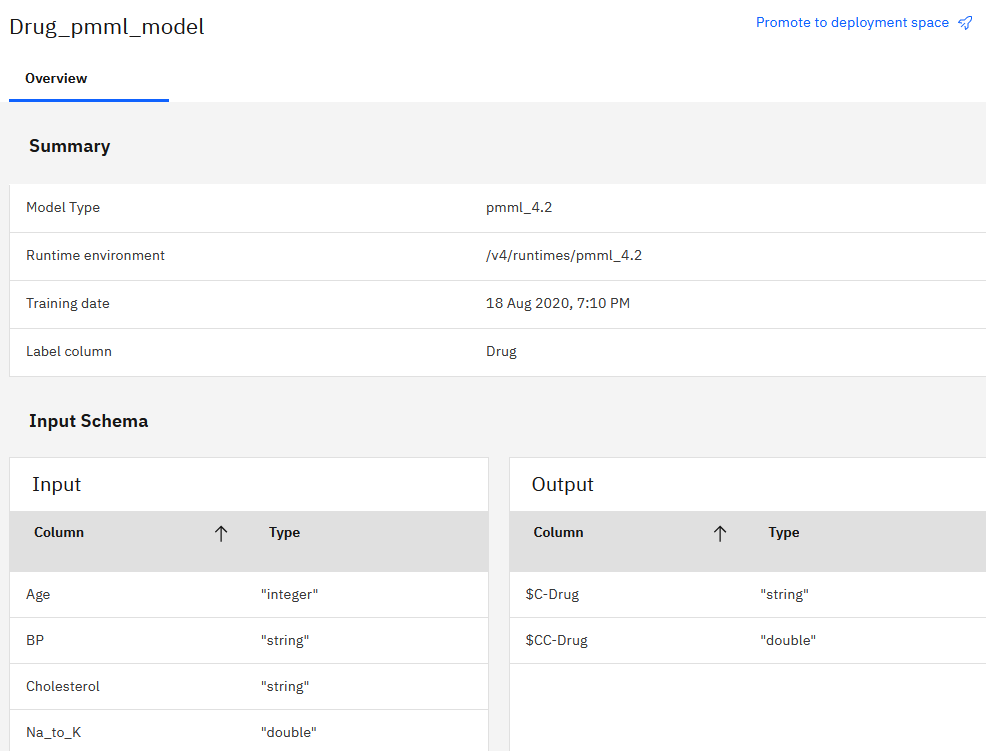
PMML model in IBM Cloud Pak for Data
Sample
The Scenario
Our scenario is about using heart disease patients health data and a PMML model to determine the best drug treatment. The model is based on the experience of other patients health records and their prescribed drug treatment (which are used as training data to create the model). The used patient data are: sex, age, blood-pressure, cholesterol, sodium concentration, potassium concentration.
The scenario was taken from IBM SPSS/ML tutorials which focused on creating models. Our focus is the usage of an existing model in a Streams real-time processing context.
You can download the data set and the PMML model here: Drug_dataset.csv, Drug_pmml_model.xml.
Application data
As developer you know the data schema of your application.
Table 1 Application input data (patient health record)
| age |
sex |
bloodPressure |
Cholesterol |
bloodSodiumConcentration |
bloodPotassiumConcentration |
| 23.0 |
F |
HIGH |
HIGH |
0.792535 |
0.031258 |
| 47.0 |
M |
LOW |
HIGH |
0.739309 |
0.056468 |
| 47.0 |
M |
LOW |
HIGH |
0.697269 |
0.068944 |
PMML models are transferable between tools and environments. So the names inside the model and those in you data schema doesn’t need to be the same. They will be mapped later. What is important is that the content is the same.
The model
As a developer you need to know the following information about the model you are going to use:
- the input data the model expects (name, type, possibly allowed values)
- the output the model generates
When opening the downloaded sample model file you find DataDictionary and MiningSchema, no transformations and no Output. According to the Quick Rule for input data (see above) we see that all MiningFields of usageType ”active” are in the DataDictionary (which defines their type and values).
<DataDictionary numberOfFields="5">
<DataField dataType="double" name="Na_to_K" optype="continuous">
<Extension extender="spss" name="storageType" value="numeric"/>
</DataField>
<DataField dataType="string" name="BP" optype="categorical">
<Extension extender="spss" name="storageType" value="string"/>
<Value property="valid" value="HIGH"/>
<Value property="valid" value="LOW"/>
<Value property="valid" value="NORMAL"/>
</DataField>
<DataField dataType="integer" name="Age" optype="continuous">
<Extension extender="spss" name="storageType" value="numeric"/>
</DataField>
<DataField dataType="string" name="Cholesterol" optype="categorical">
<Extension extender="spss" name="storageType" value="string"/>
<Extension extender="spss" name="flagTypeTrueValue" value="NORMAL"/>
<Value property="valid" value="HIGH"/>
<Value property="valid" value="NORMAL"/>
</DataField>
<DataField dataType="string" name="Drug" optype="categorical">
<Extension extender="spss" name="storageType" value="string"/>
<Value property="valid" value="drugA"/>
<Value property="valid" value="drugB"/>
<Value property="valid" value="drugC"/>
<Value property="valid" value="drugX"/>
<Value property="valid" value="drugY"/>
</DataField>
</DataDictionary>
<MiningSchema>
<MiningField name="Na_to_K" usageType="active" importance="0.431041"/>
<MiningField name="BP" usageType="active" importance="0.30367"/>
<MiningField name="Age" usageType="active" importance="0.18254"/>
<MiningField name="Cholesterol" usageType="active" importance="0.082749""/>
<MiningField name="Drug" usageType="predicted"/>
</MiningSchema>
The MiningField “Drug” is the field to be predicted so it’s no input data. The DataDictionary shows the type of “Drug” as “string” and “categorical” and all allowed values (being determined by model training).
The used algorithm is a “C5” “TreeModel”, this is only of interest to determine what output features we can expect as the model file itself doesn’t define an “Output” element.
We want only the name of the best drug, the feature “predictedValue” for the target field “Drug”.
Summary of our model analysis:
- The names of the fields in our application data schema are not the same as in the model.
- We have fields with “categorical” values, meaning that the model expects just these values.
- There is a field “Na_to_K” as model input required which we don’t have. Checking this with the DataScientist who created the model gives the result that it is the quotient of sodium and potassium, which we can calculate from our application data.
- “Drug” is the data field being predicted (target). We want to have the result feature “predictedValue” for this target “Drug”.
Implementation
Prepare application data to match the model input/output data
The above model analysis shows us 4 points we have to solve for implementation:
- The different names of model input and application data: No problem, this is done by providing a mapping to the scoring operator.
- Check that the application contains same “categorical” values (“BP” expects values “HIGH”, “NORMAL”, ”LOW” and “Cholesterol” expect values “High” and “NORMAL”). For our data this is the case. If the scoring engine detects wrong values it will generate an appropriate error.
- The value for model field “Na_to_K” has to be calculated and added to the scoring input data schema while “NA” and “K” can be removed. This is done with a SPL operator Functor (see below).
- The scoring will provide the result “predictedValue” of the target “Drug”, the scoring output schema need to be extended with an attribute “drug” containing the predicted drugs name. Further all input data should be contained in the output data too.
Table 2 Resulting input data schema for scoring
| age |
sex |
blood pressure |
cholesterol |
NA_to_K |
| 23.0 |
F |
HIGH |
HIGH |
25,3546 |
| 47.0 |
M |
LOW |
HIGH |
13,0925 |
| 47.0 |
M |
LOW |
HIGH |
10,1135 |
drug
Table 3 Scoring Result extension schema
| drugY |
| drugC |
| drugC |
| age |
sex |
blood pressure |
cholesterol |
NA_to_K |
Drug |
| 23.0 |
F |
HIGH |
HIGH |
25,3546 |
drugC |
| 47.0 |
M |
LOW |
HIGH |
13,0925 |
drugC |
| 47.0 |
M |
LOW |
HIGH |
10,1135 |
drugC |
So far, we have analyze what we need and implemented data schema and preparation. Next we want to score our data by using the Streams PMML toolkit.
PMML toolkit
The com.ibm.streams.pmml toolkit scores only PMML models and provides two SPL operators: PMMLScoring and WMLModelFeed.
Operator PMMLScoring
This operator is based on the SPSS PMML scoring engine which is also used by IBM Watson Machine Learning (WML). While WML provides the scoring functionality to an application via an online interface the PMMLScoring operator runs the complete scoring inside the operator. On that reason the operator provides the necessary performance for real-time analytics context.
As SPSS, WML and PMMLScoring operator are using same scoring engine they provide some functionality, with some exceptions for the PMMLScoring operator. Table 5 shows all supported PMML model types and their restrictions. Additionally it shows the available PMML output result features which can be used in case no “Output” element is defined in the model file. The most recent overview you can find in IBM Knowledge Center of last toolkit release (eg. release 4.3.0.1-prod20190605). There is a further table showing the appropriate SPL type for each output result feature (Table 6).
The scoring engine supports PMML version 3.0 to 4.3.
TypeRestrictionsResult Features available w/o Output defined
Table 5 PMML toolkit supported model types, restrictions and default Result features
| Association Rules |
Transactions are not supported |
EntityId, EntityAffinity |
| Baseline Models |
Only ‘zValue’ teststatistic supported. All others need transactions. Transactions are not supported |
PredictedValue |
| Bayesian Network |
none |
PredictedValue, StandardError |
| Clustering |
none |
ClusterId, ClusterAffinity |
| Gaussian Process |
none |
PredictedValue |
| General Regression |
none |
PredictedValue |
| k-Nearest Neighbors |
none |
RecordID (SPSS-specific), EntityAffinity |
| Naive Bayes |
none |
PredictedValue, Confidence, Probability per Category |
| Neural Networks |
none |
PredictedValue, Probability per Category, Confidence, Extended |
| Regression |
none |
PredictedValue, Confidence, Probability per Category |
| Ruleset |
Known issue: EntityId is not mappable via <target>.EntityId but only like an outputfield with SPSS specific string ‘ruleset-firstid’. In case of multiple targets it can be mapped only once |
PredictedValue, Confidence, EntityId |
| Scorecard |
none |
PredictedValue |
| Sequences |
Not supported |
n/a |
| Text |
Not supported |
n/a |
| Time Series |
Not supported |
n/a |
| Decision Trees |
none |
PredictedValue, Confidence, Probability, Probability(per Category), EntityId |
| Support Vector Machine |
none |
PredictedValue |
FeatureSPL typeComment
Table 6 Output features used for mapping and the SPL type they expect
| PredictedValue |
rstring |
|
| Probability |
map<rstring,float64> |
|
| Confidence |
list<float64> or float64 |
|
| StandardError |
float64 |
|
| ClusterAffinity |
list<float64> or float64 |
|
| EntityAffinity |
list<float64> or float64 |
|
| EntityId |
list<rstring> or rstring |
|
| ClusterId |
list<rstring> or rstring |
|
| Affinity |
list<rstring> or rstring |
|
| Extended |
map<rstring,float64> |
SPSS proprietary |
| RecordId |
list<<rstring> or rstring |
SPSS proprietary |
Using PMMLScoring operator is fairly simple if you have done the steps before:
- Determine the model to be used
The operator supports loading a model at application start from PMML xml file and loading a model at runtime which is received on a separate input port. You may implement your own logic to feed a model at runtime (database, file system).Note:If your model is stored in IBM Cloud WML service you can use the WMLModelFeed operator to load a model from WML model repository and feed it into the PMMLScoring operator.For our scenario we will use the model file direct, no runtime loading. The model file is included into the built application bundle and is so available at the runtime environment.
- Determine the input mapping
As model data fields can have different names than your actual application schema you define a mapping for each model data field to an attribute of your input data schema.For our scenario we have collected all mapping relevant information before.
- Determine the output schema
As the scoring engine generates a number of output values you need explicitly define which output value you want to write to which attribute of your data schema. Output values are either the output fields defined in the “Output” element of your model file or in case of missing “Output” element the per model type available result feature. “Output” element fields are referenced just by their name. Result features (Table 5) are related to a “target” or “predicted” data field.For our scenario we decided that we need only the predicted drug itself, no further result features. As explained above, referencing this value is done by “Drug.PredictedValue”
Putting all collected information together our code would look like the following snippet, which shows schema definitions and pre-processing and scoring.
RawPatientData =
int32 age,
rstring sex,
rstring bloodPressure,
rstring cholesterol,
float64 bloodSodiumConcentration,
float64 bloodPotassiumConcentration;
ScoringInputSchema =
int32 age,
rstring sex,
rstring bloodPressure,
rstring cholesterol,
float64 NA_to_K;
ScoringResultExtension = rstring drug;
ScoringOutputSchema = ScoringInputSchema,ScoringResultExtension;
stream<ScoringInputData> InputRecords = Functor(RawData) {
output
InputRecords:
NA_to_K =
bloodSodiumConcentration/bloodPotassiumConcentration;
}
stream<ScoringOutputSchema> DrugTreatments = PMMLScoring(InputRecords)
{
param
modelPath: getApplicationDir() + "/etc/Drug_pmml_model.xml";
modelInputAttributeMapping: "Age=age,BP=bloodPressure,Cholesterol=cholesterol,Na_to_K=NA_to_K,Sex=sex";
modelOutputAttributeMapping: "drug=Drug.PredictedValue ";
}
The output of this snippet is shown in Table 4.
A similar application sample is provided on your system with the IBM Streams installation at the following location …
cd $STREAMS_INSTALL/samples/com.ibm.streams.pmml/DrugTreatments/
In addition to the mapping of a single output result feature you can get the complete scoring engine output in JSON format. This is very useful to see what the scoring engine provides for your model before you do the final mapping. You can get this JSON string if you specify the operator parameter rawResultAttributeName with an attribute name of your output schema which has type rstring.
This code snipped shows just the difference to the one above.
ScoringResultExtension = rstring drug,
rstring jsonRawResult;
stream DrugTreatments = PMMLScoring(InputRecords)
{
param
modelPath: getApplicationDir() + "/etc/Drug_pmml_model.xml";
modelInputAttributeMapping: "Age=age,BP=bloodPressure,Cholesterol=cholesterol,Na_to_K=NA_to_K,Sex=sex";
modelOutputAttributeMapping: "drug=Drug.PredictedValue ";
rawResultAttributeName: jsonRawResult;
}
The raw Json string is a JSON array where each element describes one scoring output value. The output values may be single values or building a map over categorical values. Checking this raw output shows what you may get from your model. The JSON below shows us that we can get for target “Drug” following features: “PredictedValue”, “Confidence”, “Probability” (for the PredictedValue), “Probability” (map over all possible drugs and their probability) and “EntityId” (the trees node-id for the “PredictedValue”). Remember, when we analyzed the model we saw that the model type was “Tree” with “C5” algorithm. Table 5 is the summery of available default features (w/o “Output” element) and shows just what we see here in JSON.
[{
"scoreResultDescriptor":
{
"measureLevel":"unknown",
"predictorNo":0,
"feature":"PredictedValue",
"index":0,
"rank":1,
"targetStorage":"string",
"isFinalResult":true,
"storage":"unknown",
"target":"Drug"
},
"fieldValue":"drugY"
},
{
"scoreResultDescriptor":
{
"measureLevel":"unknown",
"predictorNo":0,
"feature":"Confidence",
"index":1,
"rank":1,
"targetStorage":"string",
"isFinalResult":true,
"storage":"unknown",
"tag":"confidence",
"target":"Drug"
},
"fieldValue":"0.875"
},
{
"scoreResultDescriptor":{
"measureLevel":"unknown",
"predictorNo":0,
"feature":"Probability",
"index":2,
"rank":1,
"targetStorage":"string",
"isFinalResult":true,
"storage":"unknown",
"target":"Drug"
},
"fieldValue":"1.0"
},
{"scoreResultDescriptor": {"measureLevel":"unknown", "predictorNo":0, "feature":"Probability", "index":3, "rank":1, "targetStorage":"string", "isFinalResult":true, "storage":"unknown", "category":"drugA", "target":"Drug"}, "fieldValue":"0.0"},
{"scoreResultDescriptor":{"measureLevel":"unknown", "predictorNo":0, "feature":"Probability", "index":4, "rank":1, "targetStorage":"string", "isFinalResult":true, "storage":"unknown", "category":"drugB", "target":"Drug"}, "fieldValue":"0.0"},
{"scoreResultDescriptor":{"measureLevel":"unknown", "predictorNo":0, "feature":"Probability", "index":5, "rank":1, "targetStorage":"string", "isFinalResult":true, "storage":"unknown", "category":"drugC", "target":"Drug"}, "fieldValue":"0.0"},
{"scoreResultDescriptor":{"measureLevel":"unknown", "predictorNo":0, "feature":"Probability", "index":6, "rank":1, "targetStorage":"string", "isFinalResult":true, "storage":"unknown", "category":"drugX", "target":"Drug"}, "fieldValue":"0.0"},
{"scoreResultDescriptor":{"measureLevel":"unknown", "predictorNo":0, "feature":"Probability", "index":7, "rank":1, "targetStorage":"string", "isFinalResult":true, "storage":"unknown", "category":"drugY", "target":"Drug"}, "fieldValue":"1.0"},
{"scoreResultDescriptor":{"measureLevel":"unknown", "predictorNo":0, "feature":"EntityId", "index":8, "rank":1, "targetStorage":"string", "isFinalResult":true, "storage":"string", "tag":"tree-nodeid", "target":"Drug"}, "fieldValue":"4"}]
WMLModelFeed operator
This operator is a connector to an IBM Watson Machine Learning (WML) instance, either running in IBM Cloud or in IBM Cloud Pak for Data. It is using the WML REST API to connect to the instance, to query the repository for available models and filter for the model you want to use.
Updating models at runtime
Although models stored in WML repository have versions, the operator always reads the most recent version. The operator can query the WML repository to enables a runtime update of the model used in PMMLScoring operator. This may occur only if the model retraining is done by different tooling as the PMML toolkit doesn’t provide retrain capabilities.
Connect to WML repository
To connect to WML the credentials provided by the WML instance need to passed to the operator. This can be done on several ways, most simple is copying the credential JSON string and paste it into an ApplicationConfiguration property named jsonCredentials. The name of the ApplicationConfiguration has to be set as parameter connectionConfiguration at the WMLModelFeed operator.
For detailed information see WMLModelFeed SPL documentation.
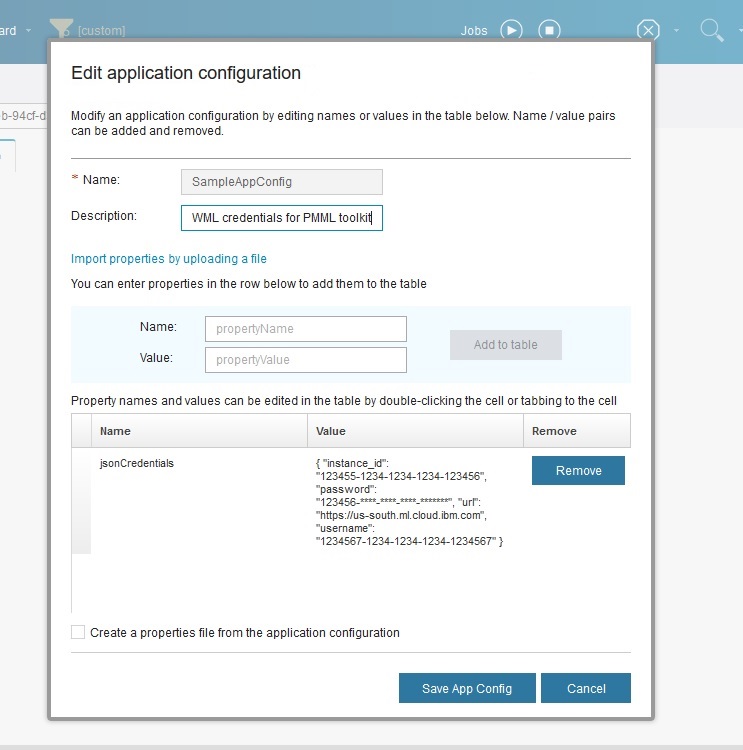
Creating PMML scoring application with Python
The PMML toolkit provides a Python package: streamsx.pmml.
A sample Jupyter notebook is available. It demonstrates the usage of the streamsx.pmml package when creating streaming analytics applications with Python. The notebook is available on GitHub.
This video walks through using the sample notebook to score a PMML mode in Python:
Further Resources
#CloudPakforDataGroup