If you would like to connect to a running Streams application via REST, you can use the new Streams jobs as a service feature that's available in Cloud Pak for Data (CPD) v3.5.
You can use this feature to retrieve data from a running Streams application via GET requests and send data via POST requests. This article has a video demo and more background information.
This tutorial demonstrates how to use this new feature to add REST input and output endpoints to SPL (Streams Processing Language) applications.
To learn how to do so in Python applications, see this tutorial. The documentation also has more reference information.
Table of Contents
Prerequisites
- To follow along in this tutorial, some familiarity with IBM Streams and SPL is required. If you are not familiar with SPL, see the SPL Quick Start.
- To run the sample applications in this tutorial:
Overview
To connect to a Streams application via REST, you need to enable REST endpoints for the application with the new EndpointSource and EndpointSink operators. When you submit a job using either of these operators, the Streams runtime launches an HTTP server that accepts REST requests and forwards the requests to the operators. You can get the URLS for the endpoints from the CPD dashboard.
All data sent and received is formatted as JSON.
How to retrieve data from a Stream via REST
To access the tuples on a Stream via REST, pass the Stream to the EndpointSink operator, for example:
() as RESTSink = EndpointSink(ResultStream1; DataStream2){
}
Each Stream consumed by the RESTSink operator is assigned a REST endpoint at runtime. When the operator receives a GET request, it converts the tuples on the Stream to JSON and sends the JSON as a response.
How does this differ from views?
A view allows you to retrieve a sample of the data on a Stream. With the right configuration, it is possible to retrieve all the tuples in a Stream consumed by the EndpointSink operator. See the operator configuration section later in this tutorial.
How to ingest streaming data via REST
To ingest data in a Streams application via REST, invoke the EndpointSource operator, for example:
(stream<IncomingDataType> Messages; stream<MoreIncomingData> Quotes) as IncomingData = EndpointSource (){
}
Each output Stream of the
IncomingData operator has its own REST endpoint at runtime. You send data to the operator as JSON with a POST request. When the operator receives the request, it converts the JSON payload to tuples and submits them to the output Stream.
Sample application
The sample application is a simple calculator. It continuously ingests 2 numbers and adds them. To start, the application is using generated data and printing the result to the log and to a local file.
First, import and run the sample application to understand its behaviour.
Import the project and run the sample
- Download the sample application project from here.
- Extract the zip files into a folder.
- Import the application into VS Code:
- Go to File > Open... (or Add Folder to Workspace...).
- Browse to the project folder and click on Open (or Add).
To run this sample, open sample > BasicCalculator.spl. Right click anywhere in the file and click Build and submit job.
Select the instance for the build when prompted.
Once the build is finished, you will be prompted to submit the application. Give the job definition a name, like BasicCaclulator:
See the documentation for detailed steps to build and submit an application.
Once the job is submitted, click Show Job Graph to see the application graph.
Prompt to open the job
The Job Graph will open, showing the application's graph.
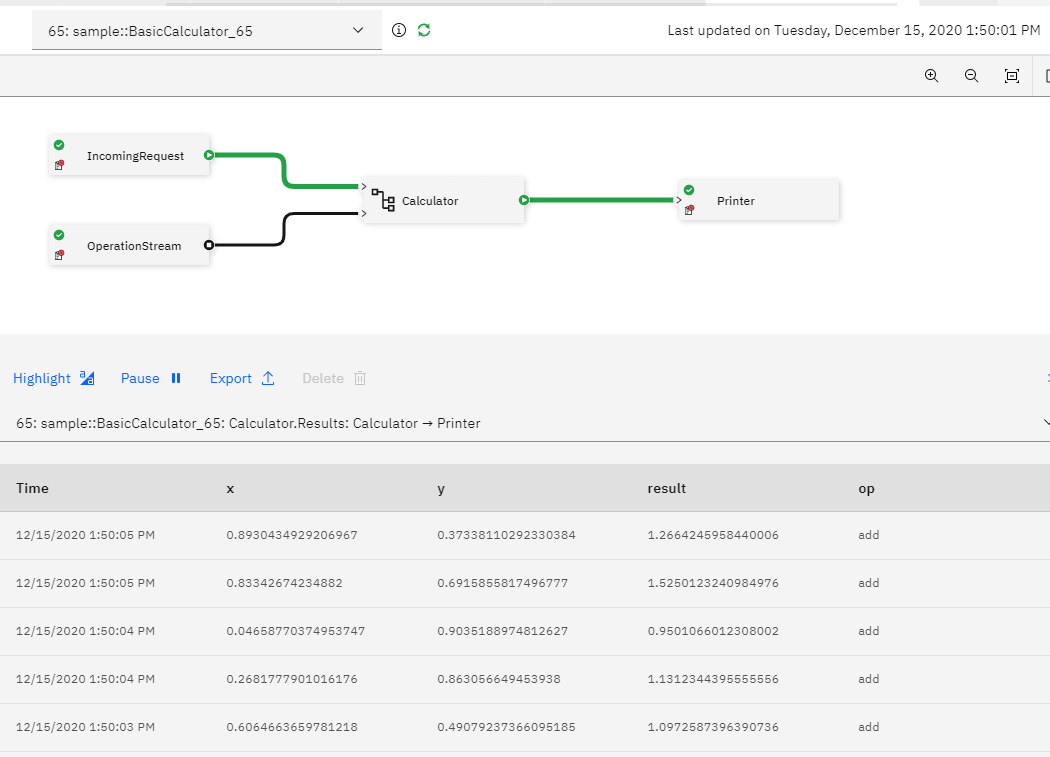
Sample overview
As shown in the preceding image,
- The
IncomingRequest operator is a Beacon that generates the numbers, and OperationStream operator specifies which arithmetic operation is currently being performed.
- The
Calculator operator performs the calculation using the data from the IncomingRequest operator and the OperationStream.
- The
Calculator sends its result to a Printer operator that prints the results.
The application also has a view that shows a sample of the output of the Calculator operator. Each result tuple shows the two numbers, x and y, the operation that was performed, and the result of the operation.
Add the operators to the sample
The results of the application are only available from the log file or from std out. In this next step, I'll modify the application to:
- Accept the 2 numbers via REST, and allow retrieving the results of addition via REST.
- Change the operation it performs on the numbers from addition to any other basic arithmetic (subtraction, multiplication, etc), on the fly.
First, I'll use the EndpointSink operator to enable accessing the result data via REST requests.
Enable a REST endpoint to GET data from the application
Recall that the way to retrieve REST data from an SPL application is to send the data Stream to the EndpointSink operator.
So, edit BasicCalculator.spl to use the EndpointSink operator to consume the Results Stream from the Calculator. Add the following lines of code:
() as CalculationResult = EndpointSink(Results) {}
At runtime, you will have a REST endpoint that you can use to retrieve the data from the Results Stream. Data is returned as JSON.
Next, modify the application so that it can accept data as input.
Enable a REST endpoint to POST data to the application
Use the EndpointSource to add a POST endpoint.
Add the first POST endpoint. Comment out the IncomingRequest operator, and replace it with this code:
(stream<Request> Operands) as IncomingRequest = EndpointSource()
{
}
What does this do?
-
The Operands Stream is the output stream of the IncomingRequest operator. At runtime, a REST endpoint will be created for the Operands output stream of the operator. JSON Data sent to this endpoint will be converted to tuples and consumed by the Calculator operator.
-
The schema of the Operands Stream is Request. This type is defined in Types.spl as Request = tuple<float64 x, float64 y>. All JSON data sent to the REST endpoint must have these two attributes.
That is all that's needed. Note that JSON data that does not match the schema will not be accepted.
So far, the application has two REST endpoints, one to POST in the numbers to add, and another to GET the results of the addition.
The final change you'll make is to also allow changing the operation the Calculator is performing via REST. This requires another POST endpoint.
Add a second POST endpoint to change the operation
To add another POST endpoint, add another output Stream to the IncomingRequest operator.
First, comment out the declaration of the OperationStream operator.
Change the IncomingRequest operator definition as follows:
(stream<Request> Operands; stream<Operation op> OperationStream) as IncomingRequest = EndpointSource()
{
}
The new OperationStream Stream will also have a POST endpoint.
Summary
You can add as many POST endpoints as you want to your application by adding new output streams separated by a semicolon to your EndpointSource operator:
(stream<IncomingDataType> Messages; stream<MoreIncomingData> Quotes) as IncomingData = EndpointSource () {}
The same goes for the EndpointSink, add input streams separated by a semi colon to the operators input will create a GET endpoint for each input Stream:
() as sink = EndpointSink (Stream1; Stream2; Stream3; Stream4){}
Build and run
After making the changes, run the application. Save the file, right click, and select Build and submit job. You can give this new job run a new name, like RESTCalculator.
Once the application is running, examine the job graph.
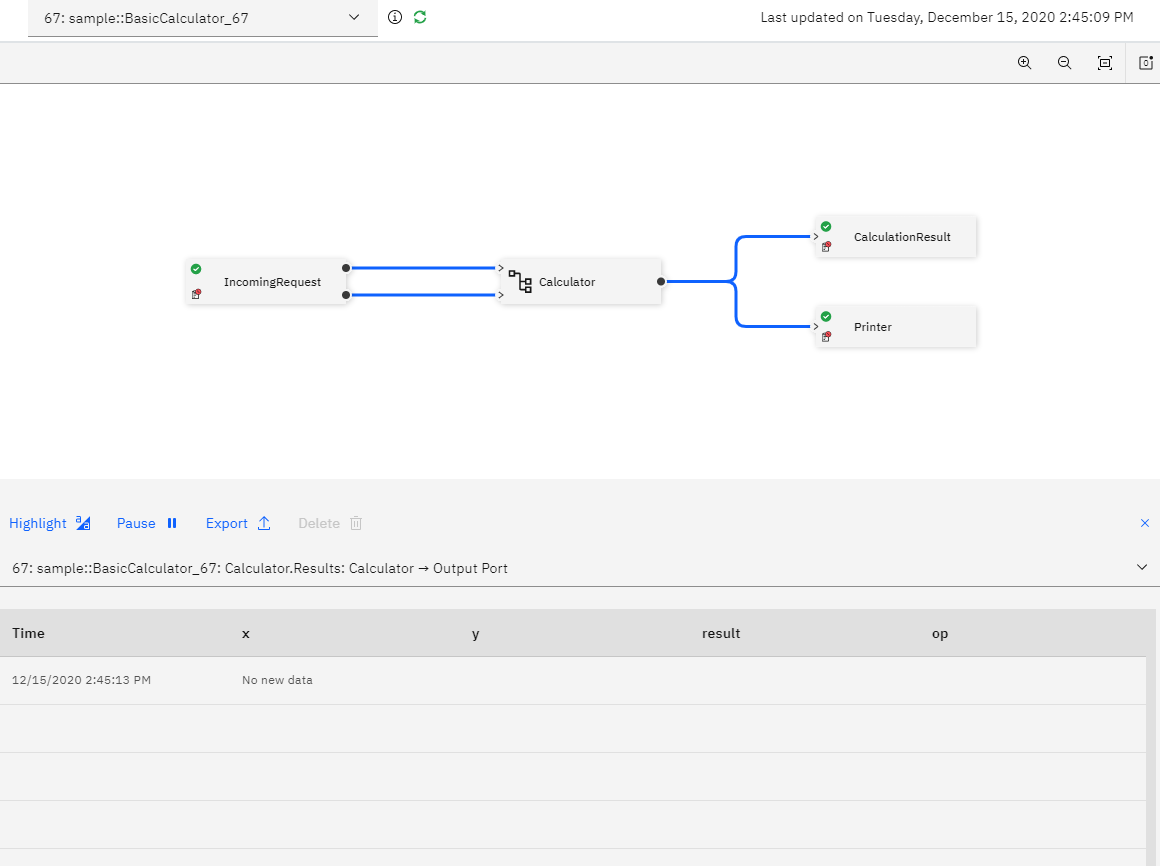
You can see the IncomingRequest operator sends 2 streams to the Calculator, one for the input and one for the operation. But there is no data in the view yet, because the application has not received any data to calculate.
Connect to the running application with the REST endpoints
When the job is submitted, the Streams runtime will create a new web service for that job. To send data to the job, you need to get the REST endpoints of the web service. The endpoints accept and receive data formatted as JSON.
You can get the REST endpoints from the web service instance in Cloud Pak for Data. and the Swagger documentation for each endpoint is accessible from the CPD dashboard.
Find the REST endpoints
Open the CPD dashboard.
From the main menu, click Services > Instances.
-
Click on the hamburger (☰) menu icon in the top-left corner of your screen and click Services > Instances.
-
Look for a new instance of type streams-application with a name in the format <streams-instance-name>.<openshift-project-name>.<job-id>, where the job id is the job id displayed when submitting the job, and the OpenShift project name is the name of the project your Cloud Pak for Data instance is installed onto. This is not the same as a project in the Cloud Pak for Data.
For example, in the screenshot below, the streams instance name is sam-auth-tracing, project name is tooling-55-cpd, and the job ID is 74.
-
Click on the name of the web service.
This opens a page listing the available endpoints, any documentation you may have added, and the schema for each endpoint. Documenting the endpoints is discussed further along in this article.
Under Data access endpoints you will see there are 2 POST endpoints and 1 for GET:
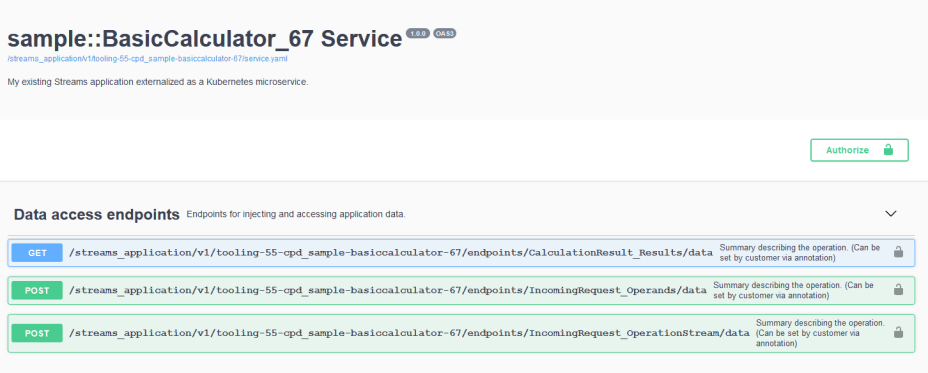
The full URL for each endpoint is CPD_URL + <endpoint>
Note: If you use the annotations to document the endpoints (discussed below) your endpoints will be grouped by the tag used in the annotation.
Test the endpoints
Send a POST request with some data to be calculated, then use a GET request to retrieve the results.
-
Click the POST IncomingRequest_Operands endpoint. This is the endpoint to send operands, or numbers to be added.
-
Click Try it out.
-
In the Request body text field, paste this data:
{
"items": [
{
"x": 10,
"y": 20
},
{
"x": 1,
"y": 2
},
{
"x": 1000,
"y": 1000
}
]
}
- Click Execute.
- Under Responses, the Code should be
204, indicating success.
-
Click the GET CalculationResult_Results endpoint.
-
Click Try it out.
-
Click Execute
-
Under Responses, the Code should be 200.
-
The Response body should have some data like this:
{
"items": [
},
{
"op": "add",
"result": 30,
"x": 10,
"y": 20
},
{
"op": "add",
"result": 3,
"x": 1,
"y": 2
},
{
"op": "add",
"result": 2000,
"x": 1000,
"y": 1000
}
]
}
You can try changing the operation using the POST endpoint for IncomingRequest_OperationStream.
Sample Python client
The Try it out feature is just for demonstration purposes. To programmatically send or receive data, you can import and run this Python notebook.
Operator Configuration and Documentation
You can add documentation to the operators with annotations and configure their behaviour with parameters.
Controlling tuple retention
By default, the EndpointSink operator will keep only the most recent 1000 tuples received from the input Stream. If you want to change this value, you can use the bufferSize parameter, as follows:
() as CalculationResult = EndpointSink(Results)
{
param
bufferSize: 1500;
}
In the case of the EndpointSource operator, the bufferSize parameter is used to indicate how many tuples can be accepted in a single request. The default value is 100. You can change this value by specifying the bufferSize parameter.
Using the annotations to document the endpoints
Within the SPL application, you can use the @endpoint annotation to document each endpoint. Each Stream produced or consumed by the Endpoint* operators may be documented with its own @endpoint annotation.
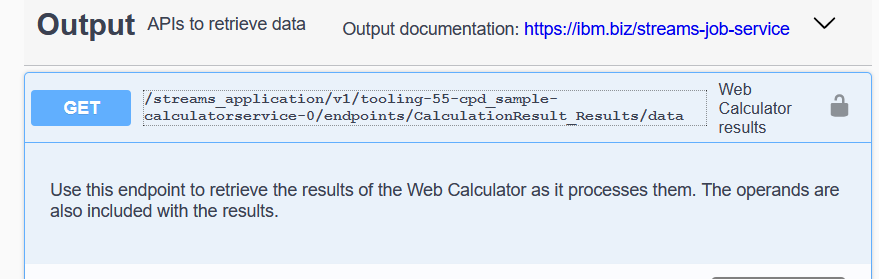
The sample application contains a completed version of the sample in a file called CalculatorRESTService.spl that uses these annotations. For example, here is the annotation for the Results endpoint:
@endpoint(port = Results, summary = "Web Calculator results",
tags = "[\"Output\"]",
description = "Use this endpoint to retrieve the results of the Web Calculator as it processes them. The operands are also included with the results.",
attributeDescriptions = "{\"x\": { \"description\": \"The first operand.\" },
\"y\": { \"description\": \"The second operand.\" },
\"operation\": { \"description\": \"The operation to perform on the operands.\" },
\"result\": { \"description\": \"The calculated value.\" },
}")
This is displayed in the Swagger documentation:
Access control for endpoints
The full URL for each endpoint is CPD_URL + ENDPOINT. You can share this URL with others so that they can access the data programmatically.
Each user must be added to the Streams instance in Cloud Pak for Data as a user or an administrator.
Multiple endpoints within an application
As noted in the examples above, you can add multiple POST/GET endpoints to an application by having multiple input/output streams for a single instance of the Endpoint* operators. Or, you can have multiple instances of the operator. Which is the better option?
When you have multiple endpoints in the same operator, all share the same buffer size and the operator runs on a single resource. This might be a sufficient in some cases, but in others, you might want to have more fine-tuned control over the performance of the operators.
In that case, you could use multiple instances of the EndpointSink or EndpointSource operators. This has two advantages:
1. Using separate operators would allow you to specify different buffer sizes, thus allowing each endpoint to consume different amounts of data in each request.
2. Each separate operator could potentially run on different resources, depending on resource configuration and operator memory requirements. This also allows you to optimize performance.
Your design decision will depend on your application's needs.
Summary
As mentioned, when you submit a job with either of the EndpointSource/EndpointSink operators, the Streams runtime creates a HTTP server to handle REST requests. The runtime also creates a CPD web service that lets you manage the REST endpoints.
Important points to note:
- At runtime, there is a REST endpoint for each output Stream produced by the
EndpointSource operator. Similarly, there is a separate endpoint for each input Stream consumed by the EndpointSink operator.
- The web service provides REST endpoints that you can use to send and receive data to/from the running job.
- The endpoints accept and receive data formatted as JSON.
- The URLs and Swagger documentation for each endpoint are accessible from the CPD dashboard after launching the application.
Visualize data from a REST endpoint
You can use the streams-rest-viewer Python application to connect to a GET endpoint and continuously display the data from the endpoint. Try the application on GitHub.
Links
See the Python tutorial for a Python example of using the endpoint operators.
For more technical information about the job services see the documentation.
#CloudPakforDataGroup