This blog post gives an overview of the code experience for data scientists in Watson Studio on Cloud Pak for Data 4.6. We cover the new improved VS Code Desktop integration, JupyterLab- and RStudio- integration. VS Code desktop integration lets data scientists use a familiar IDE to run and debug code that runs on the Cloud Pak for Data cluster. This enforces permissions and privacy rules defined in Cloud Pak for Data, like when using built-in tools. We show how the new Watson Studio extension for VS Code makes it easy to connect to Python runtime environments within Cloud Pak for Data projects. We explain how to develop and run code therein, with secure access to data in the context of the project.
Code Experience in Cloud Pak for Data
With Watson Studio on Cloud Pak for Data, we support a range of tools and IDEs integrated with projects. Data scientists can work with Python and R, using a wide range of libraries. Watson Studio libraries give access to data connections and assets in a project. They also allow saving model- or data assets to the project, and provide access to spaces and catalogs. The following diagram shows the options for use of IDEs with Git-based projects on Cloud Pak for Data.
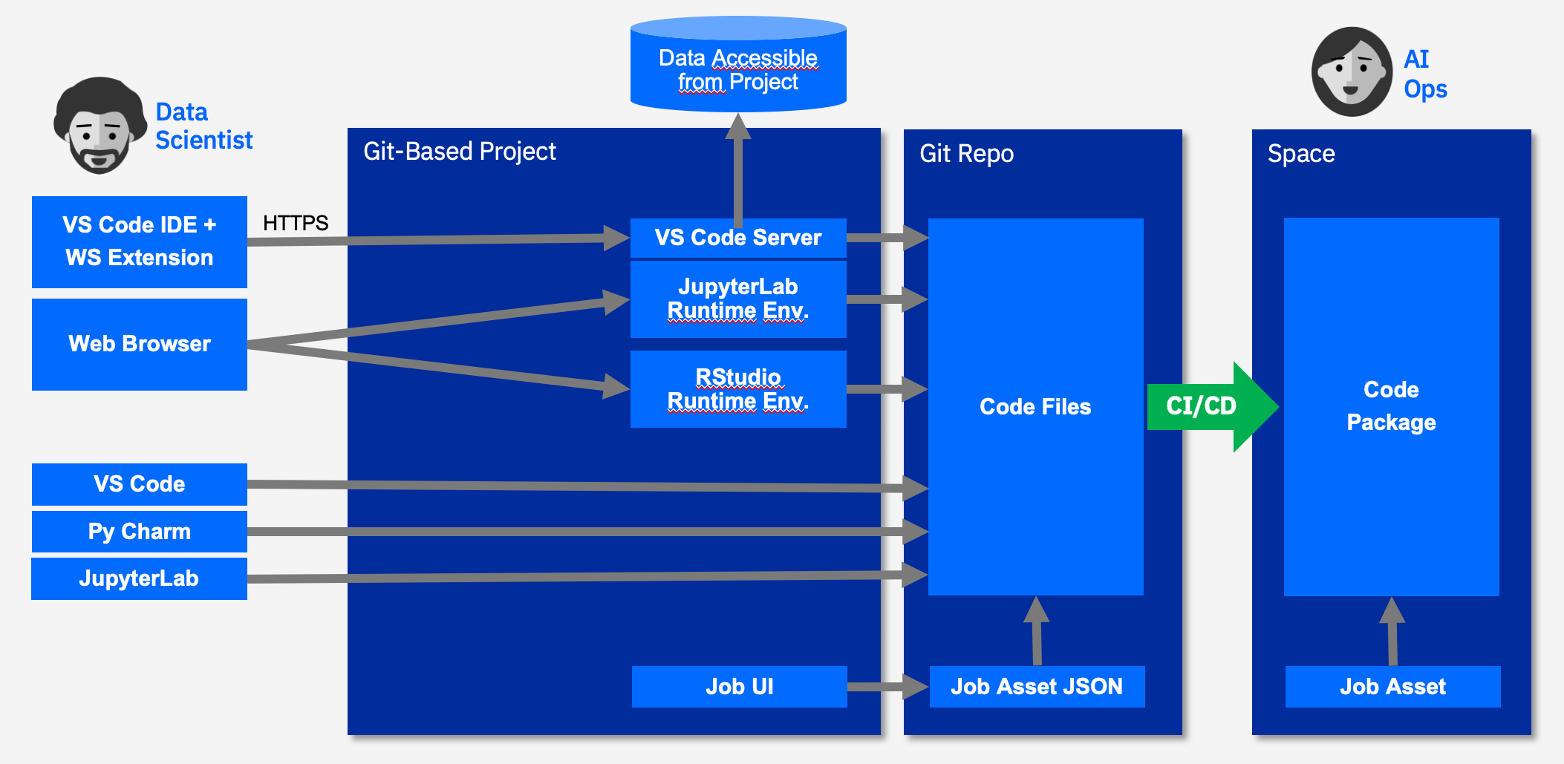 Git-based Projects with VS Code, JupyterLab, RStudio IDEs
Git-based Projects with VS Code, JupyterLab, RStudio IDEs
JupyterLab and RStudio in Watson Studio allow users to collaborate on code in Git-based projects. They exchange code via push/pull between per-user environments and the project’s Git Repo. They can also use VS Code, PyCharm, JupyterLab, … on their desktops to contribute code to a project’s Git repo.
New in Cloud Pak for Data 4.6, we provide a Watson Studio Extension for VS Code. It allows use of VS Code desktop as the UI to run and debug code inside Python runtime environments in projects on the Cloud Pak for Data cluster. This allows using compute and secure access to data in that context. Like when using built-in tools, permissions, masking, privacy rules, … defined within Cloud Pak for Data apply.
Data scientists can release code via the project’s associated Git repository. They can create release tags for operations staff or CI/CD pipelines to consume. Consumers can extract code for a release tag from the repository. They can import it as a Code Package into a Space on Cloud Pak for Data and run the code as a job or deployment. Or they can deploy and use the code elsewhere as they see fit.
Notebooks
Data scientists can use Notebooks to prepare and analyze data, to train and evaluate models, and to visualize results. Notebooks consist of a sequence of code cells with Python or R code, output cells for results, and markup cells for explanation.
JupyterLab
For development of larger amounts of Python code with many files and/or Notebooks, Watson Studio embeds the JupyterLab IDE. In the context of a project, it integrates with a project’s Git repo for code management. The following screen shows a Notebook in JupyterLab in a project. The Notebook contains code generated by Insert-to-Code from the side bar, to access and display a data asset from the project.
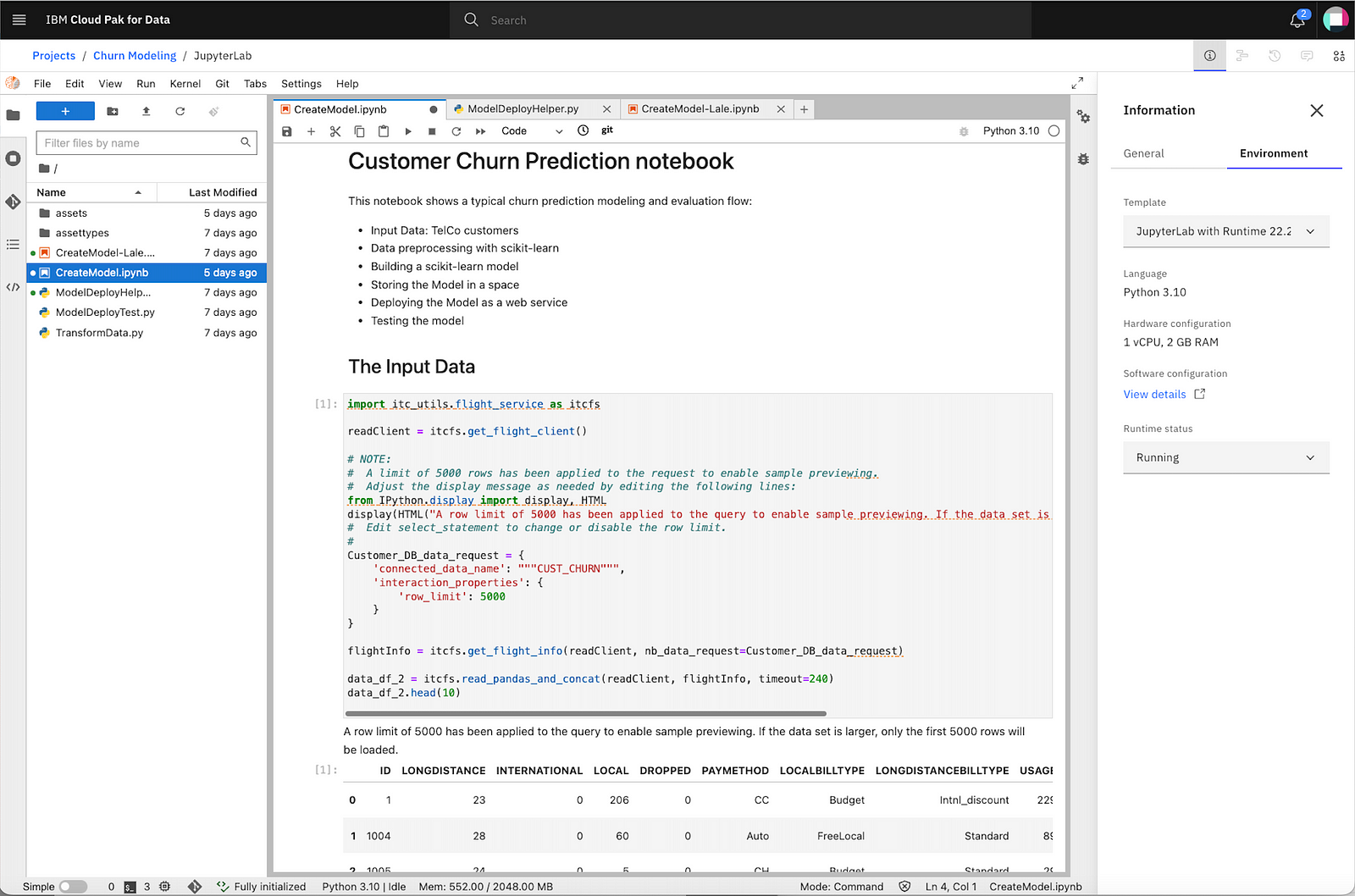 JupyterLab integrated in a project in Watson Studio on Cloud Pak for Data
JupyterLab integrated in a project in Watson Studio on Cloud Pak for Data
Customers can extend JupyterLab in Cloud Pak for Data by creating custom images. Derived from the Watson Studio JupyterLab/Python base image, they can can add JupyterLab Extensions as needed.
VS Code
VS Code supports Python development with debugging, code completion, and many useful extensions. Its Git-integration allows development and contribution of code from VS Code to Git-based projects in Cloud Pak for Data.
The new Watson Studio Extension for VS Code allows to also connect to Python runtime environment in Git-based projects on Cloud Pak for Data. It creates a secure HTTPS connection from the user’s desktop to the Cloud Pak for Data cluster. Users can work in the familiar VS Code IDE. From that UI they can run and debug their code in Python runtime environments — such as CPU, GPU, Spark, custom environments — on Cloud Pak for Data. Running in that context, their code can use the Watson Studio project library to access assets and data connections within in the project. They can use runtimes environment configurations with large amounts of compute and memory if needed.
Because the user’s code runs in the context of a Python runtime environment in a project in Cloud Pak for Data, all permissions, masking, privacy rules … as defined in Cloud Pak for Data are enforced.
Users can downlaod the Watson Studio Extension for VS Code from the Cloud Pak for Data cluster and install it via the VS Code extension install UI.
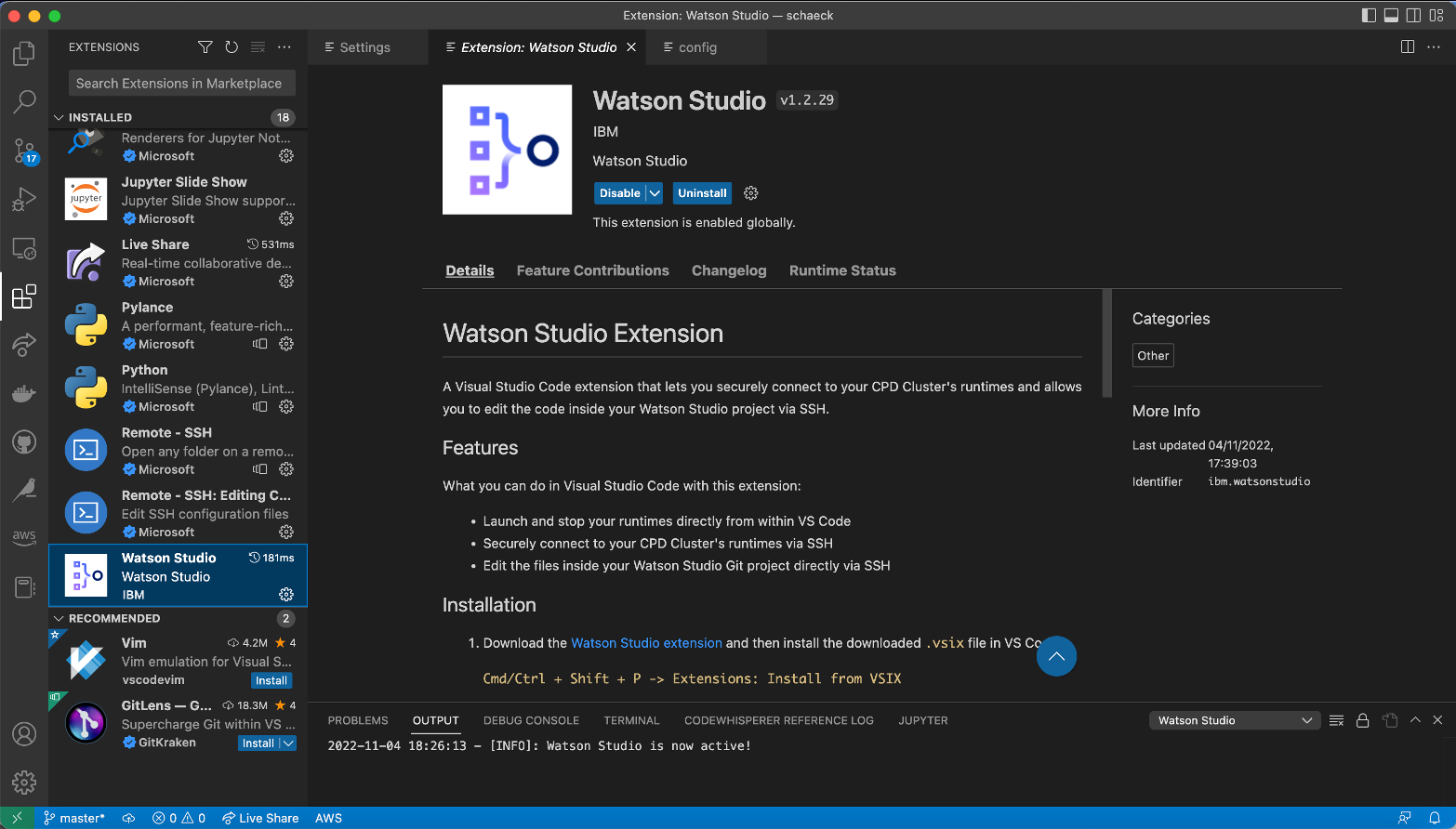 The Watson Studio Extension for VS Code
The Watson Studio Extension for VS Code
The user needs to configure the Watson Studio extension with their Cloud Pak for Data cluster URL, personal API key, etc.
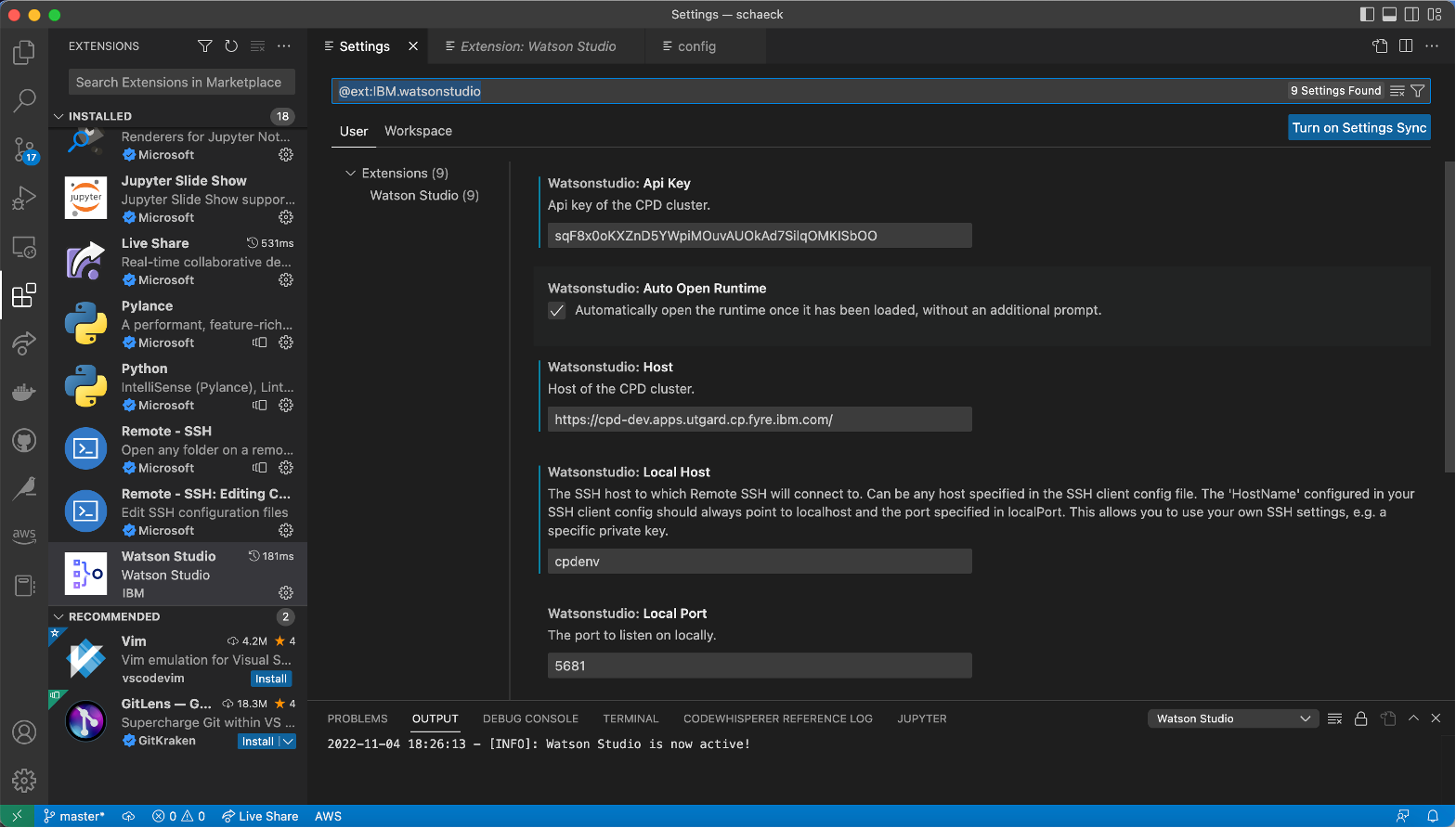 Configuring the settings of the Watson Studio Extension for VS Code
Configuring the settings of the Watson Studio Extension for VS Code
Now the Watson Studio Extension lets the user connect to a new or running Python runtime environment in any Git-Project they have access to. The user selects the project to use, and the Python runtime environment definition or running Python runtime environment in it.
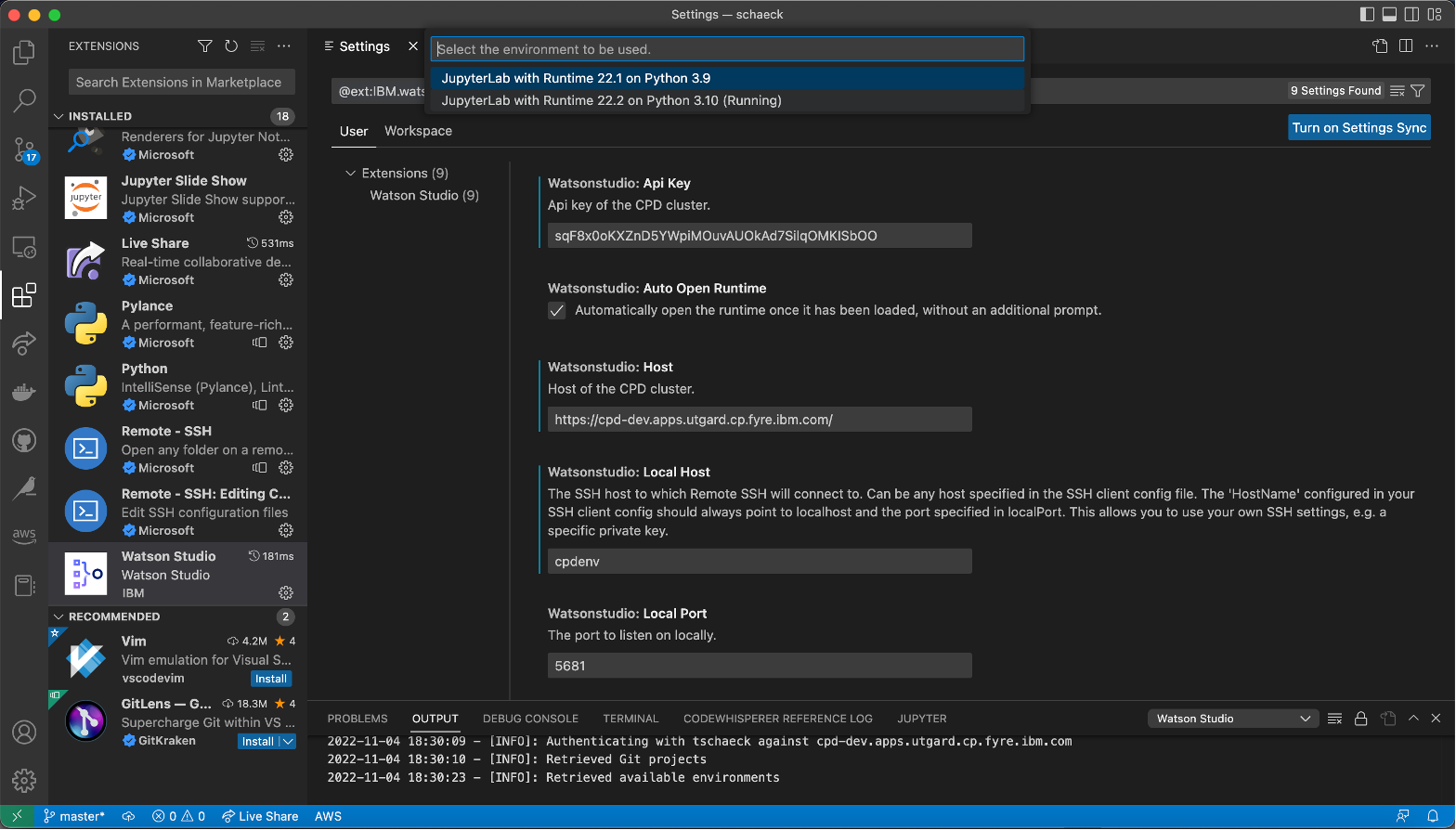 Selecting project and Watson Studio Python runtime environment on Cloud Pak for Data to connect to
Selecting project and Watson Studio Python runtime environment on Cloud Pak for Data to connect to
The user can develop, run, and debug Python code, directly in that runtime environment in the project on the Cloud Pak for Data cluster. The following picture shows debugging Python code that runs in the context of a project, accessing data via a Cloud Pak for Data connection to Db2. Likewise, it is possible to access all data from any of the many other data sources that Cloud Pak for Data supports. The user can commit and push code to the project’s Git repository, to collaborate with project members and make code available to deploy.
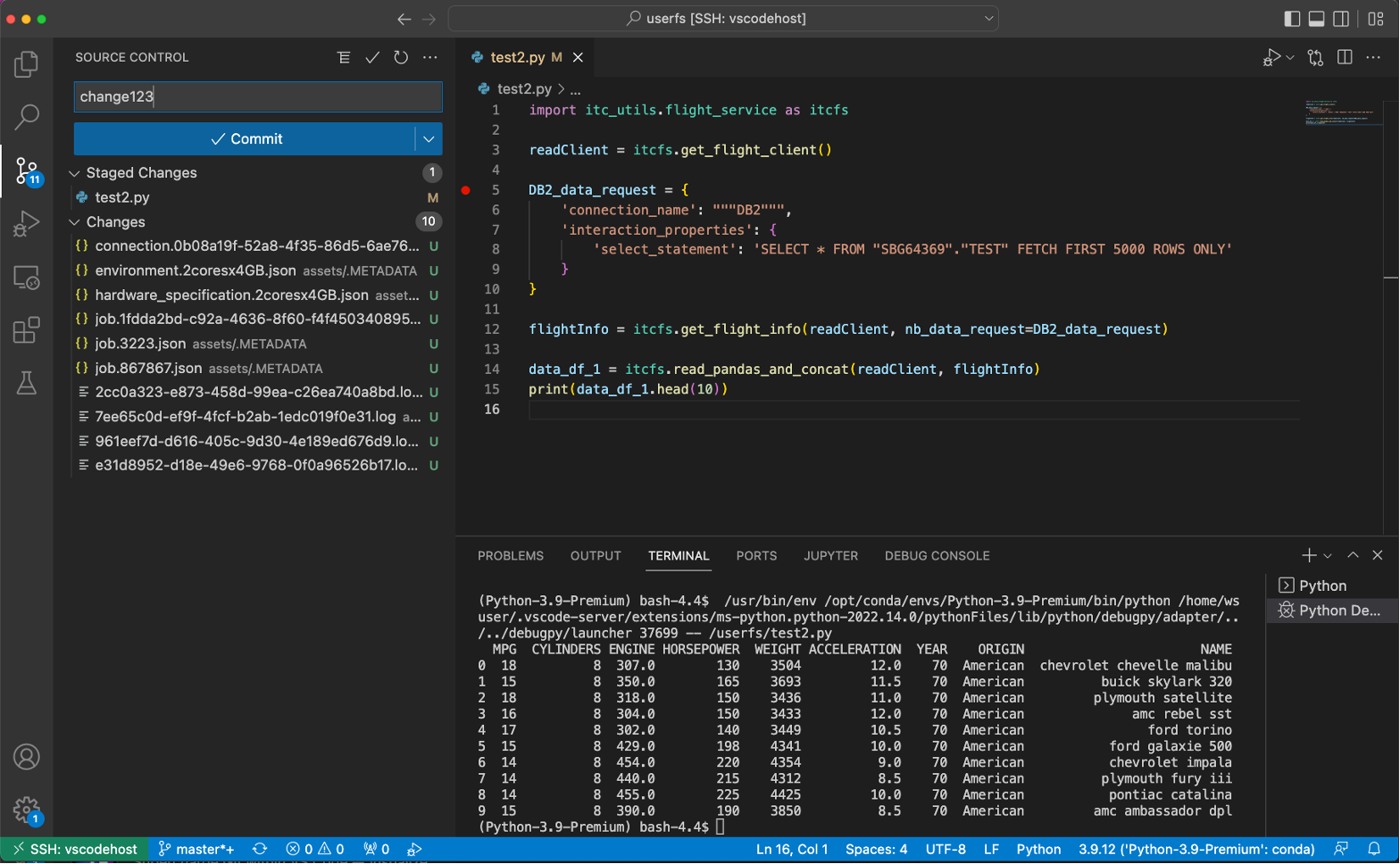 Running your Python code and accessing data in the project on Cloud Pak for Data
Running your Python code and accessing data in the project on Cloud Pak for Data
The above also works together with other VS Code extensions. For example, developers can use GitHub Copilot in the context of developing code that runs in a Python runtime environment on Cloud Pak for Data.
Conclusion
VS Code desktop integration with Python runtime environments in projects adds a key piece to the code experience of Cloud Pak for Data. It brings together the best of VS Code as a leading IDE for Python with ability run and debug code in the secure context of projects on Cloud Pak for Data.
We encourage everyone to give it a try and let us know your thoughts:
Cloud Pak for Data 4.6 Docs: Watson Studio Extension for VS Code
https://www.ibm.com/docs/en/cloud-paks/cp-data/4.6.x?topic=models-visual-studio-code
#Highlights-home#Highlights#data-ai-highlights-home