Identifiers and their use
Contents
Summary
Introduction
Namespaces and uniqueness
Identifier syntax
Examples of identifiers
Identifiers and SQL tracing
Example of identifiers in SQL
Relational members
Summary
Every object in a module has a label property and an identifier property. Both properties are editable, except for the identifiers of folders and of the module itself. The latter can be changed by changing the name of the module.
Although, initially, you might be confused about the existence of two, seemingly essentially identical properties, there is a purpose for their existence and there is nothing too obscure about their functions.
The label is the property which will display in the UI. The identifier will identify the object. It will be used, either by itself or in conjunction with parent object identifiers, in expressions, in authoring and dashboards, and in the generation of SQL queries. The existence of both objects allows for the separation of the roles of object identification and of object label.
This document will show how identifiers are used. It will describe their use in expressions and reporting applications and how they can be used to make reviewing, documenting, and tracing SQL queries easier.
Introduction
The label provides a human-friendly name for an object.
The identifier provides a way to uniquely identify an object in a Cognos Analytics module and the applications which consume modules. The identifier is used in expressions and in the generation of SQL.
The identifier is automatically generated. You can edit the identifier. This allows you to make it clearer what the object is and what its role is. This can be of help when you are tracing through SQL. The default identifier takes the text of the column or table and transforms it, eliminating spaces and other reserved characters. The source of the identifier will be the column and table names.
The identifier of an object is used in conjunction with the identifiers of the parent objects of the module, which also serve to identify an object.
The label and identifier are properties of an object.
Namespaces and uniqueness
An identifier is a string which is used to identify an object, either by itself or in conjunction with the identifiers of parent objects.
Unlike Framework Manager (FM), there is only one namespace in a data module. The namespace is defined by the name of the module.
The identifier must be unique in its context. As such, an identifier string may only be used once in that context. It can be used many times in a module, however. For example, only one query item in a query subject can have an identifier of any string. The label of many query items in that query subject could be the same. An identifier can only be used for one query subject, stand-alone calculation, or stand-alone filter. This is because their context is the module itself.
In the example below, we will see an example where query items in several query subjects each have the same identifier. Because their contexts are different –the query items belong to different query subjects – they can have the same identifier. The context -- the objects which are the parent objects of the objects in question -- contributes to the uniqueness in the module.
The identifier string must be one continuous string and cannot contain spaces nor certain reserved characters or consist entirely of a reserved keyword. Certain characters such as < and = and certain keywords are reserved and may not be used.
For example, Time is a keyword and thus you cannot use Time as an identifier. You can use Time_ instead. Nor can you have an identifier such as Time ship date. You can use Time_ship_date or TimeShipDate instead.
Time is probably the most common of the keywords which are both reserved and would also be something you would like to use as an identifier, so the keyword restrictions should not be too great a burden. The discipline also helps in the identifier naming. Assigning some indication of the role being played in by the object is always a good practice. Where the identifier string you wanted to use is a reserved keyword, it is probably a good idea to qualify the identifier with a role. For example, Time_ship_date or Time_order_date. As we will see later, this will be useful in tracing through SQL.
Just as in a Framework Manager model, folders are not name spaces nor are they incorporated into the multi-part identifier name of an object.
Identifier syntax
The syntax of an identifier consists of the contextual name parts and the naming structure.
In general, the expression rendering of the identifier will be a one-part name for objects where the object is referenced within the context of its parent, two-part names within the context of a module, and a fully qualified name, which usually will be displayed in expressions in authoring.
There are two basic structures of identifier. An object’s identifier can be displayed in either format, depending on where it is used. The identifier itself is the same, the only difference is the presentation of the identifier.
For example, the identifier of a query item in an expression in authoring is similar to the following, where the identifier elements are delimited by square brackets:
[C].[C_Coffee_Shop_Sales].[pastry_inventory].[transaction_date]
This is similar in principle to the identifier of a query item from a FM package, one of which is shown below.
[Sales (query)].[Products].[Product type]
Reading the parts from the right to left, transaction_date is the identifier of the query item, in this case transaction_date, pastry_inventory is the identifier of the query subject in which the query item is located. C.C_Coffee_Shop_Sales is the identifier of the module, in this case the sample Coffee sales and marketing module.
In other places, it will display as the following:
pastry_inventory.transaction_date
The two-part name which identifies a query item in an expression will be similar to this:
pastry_inventory.transaction_date
This consists of the identifier of the query subject (pastry_inventory) and the identifier of the query item ( transaction_date).
In general, although slightly confusing it should only be of passing interest to you.
Examples of identifiers
The following example attempts to show how an identifier is used in expressions and how it differs from a label. It uses the Coffee sales and marketing module, which is, if you have installed the samples deployment, located in the Samples/By industry /Retail/Data folder.
In order to best follow the exercise, it would be necessary to open the module.
Once you have opened the module, type date in the search control at the top of the module metadata tree.
The tree will change and only display the Sales Receipts, Pastry Inventory, Customer, Dates, and Staff query subjects. Under each of them will be query items with Date in their label.
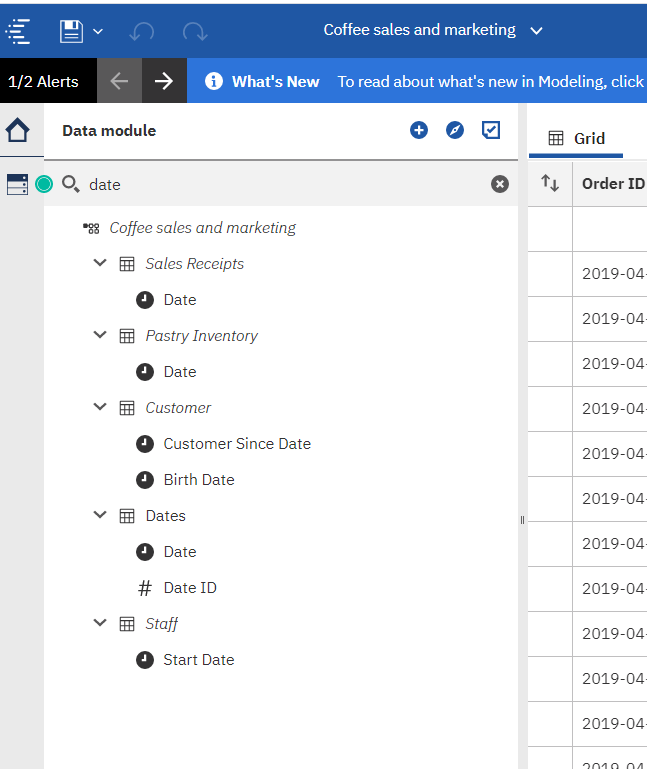
Select date for Sales Receipts and choose properties from the context menu. Expand the advanced section. You will see that the identifier for Date is transaction_date.
Select Date for Pastry Inventory and choose properties from the context menu. Expand the advanced section. You will see that the identifier for Date is also transaction_date.
Why is this? Each identifier is qualified by the identifier of its parent object.
Select Date for Pastry Inventory and choose properties from the context menu. Click on the expression view or edit button. The expression editor for the query item will appear. In it, the expression of the query item will be transaction_date.
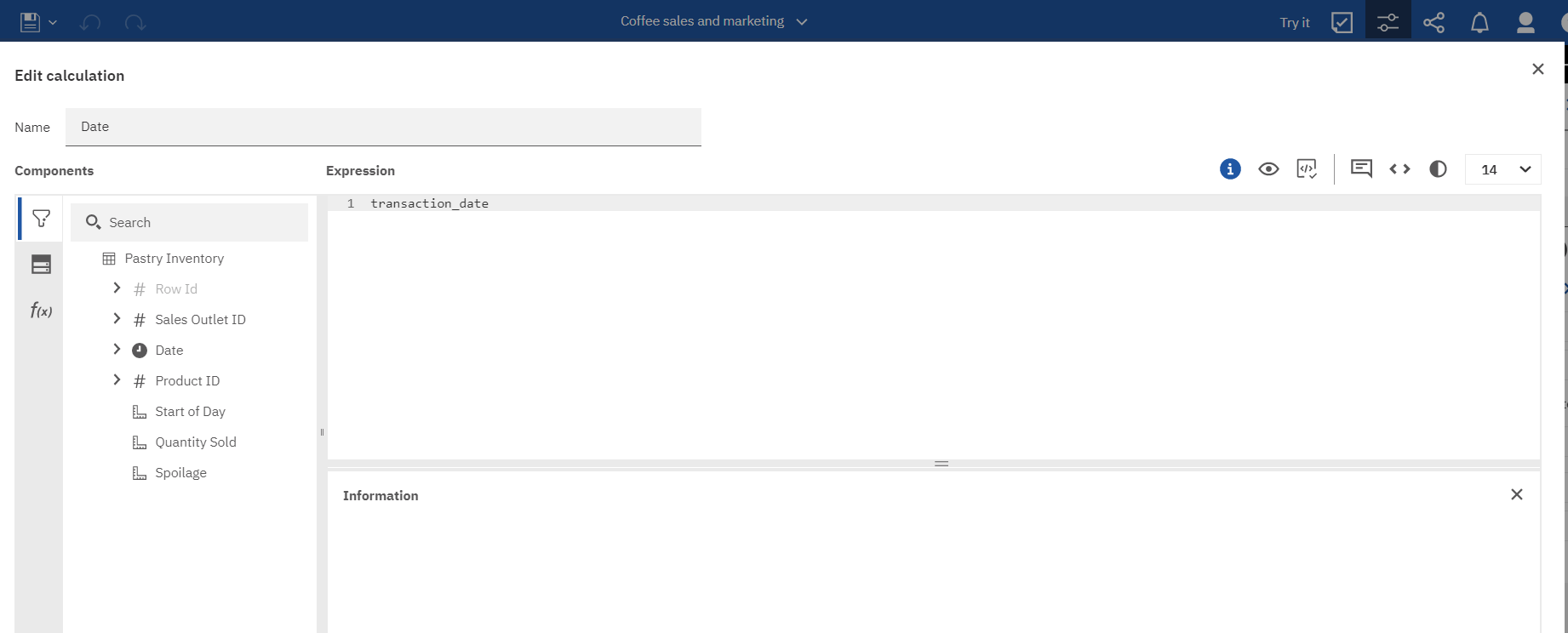
Select Pastry Inventory and choose new calculation from the context menu. Drag date into the expression editor canvas. The expression will be transaction_date.
In both of these cases, the context for the identifier is its parent query subject so it only needs the one-part name.
Select the module root node and choose new calculation from the context menu.
Select Pastry inventory.Date and drag it into the expression editor. Press the enter key a couple of times. Select Sales receipts.date and drag it into the expression editor.
What you should see is something like this.
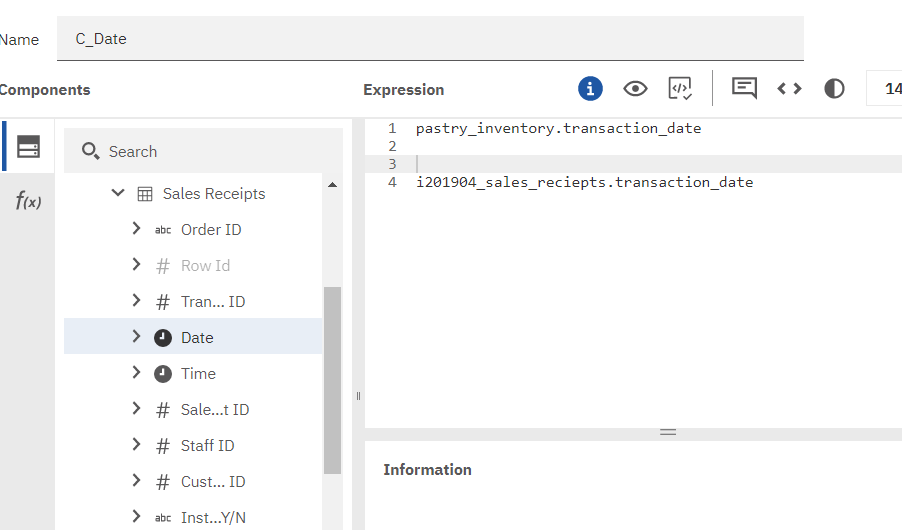
pastry_inventory.transaction_date and i201904_sales_reciepts.transaction_date
You will see that each object has a two-part name. One part is the identifier of the query subject. The second is the identifier of the query item or column.
Select the Sales Receipts query subject and choose properties from the context menu.
Expand the advanced section.
You will see the identifier. The identifier for Sales Receipts is i201904_sales_reciepts (sic).
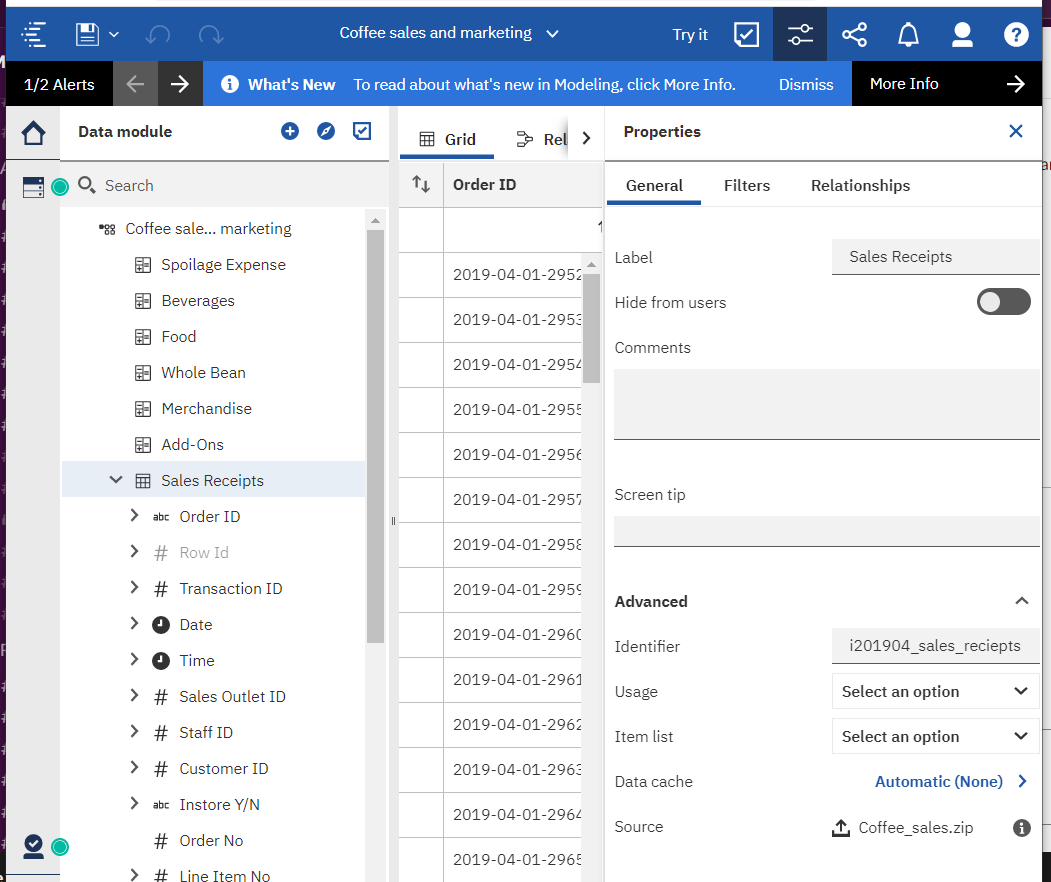
In the following picture you will see the identifier for a stand-alone calculation which references a query item from Sales Receipts.
Select one of the calculations such as Whole Bean and choose edit calculation from the context menu.
You will see an expression similar to this, which is the expression for Whole Bean.
IF ( product.product_group = 'Whole Bean/Teas') THEN ( i201904_sales_reciepts.line_item_amount ) ELSE ( 0 )
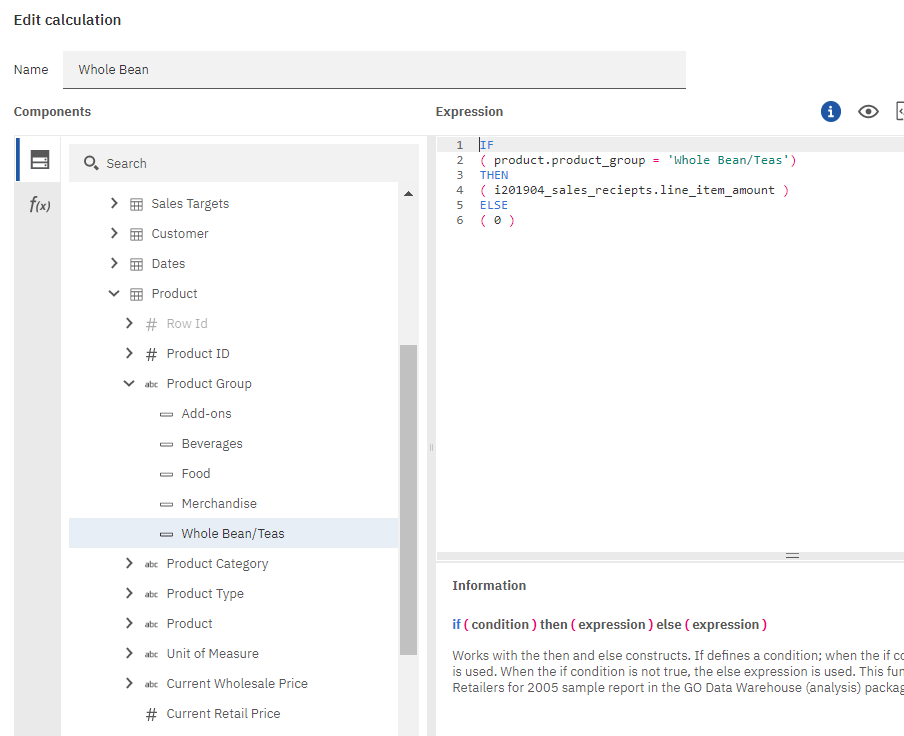
Select Whole Bean and view its identifier.
You will notice that the identifier for Whole Bean is beverages_sale_2.
Select the module root and choose new calculation from the context menu. Drag Whole Bean onto the expression editor canvas.
You will see that that identifier is beverages_sale_2.
This is because the context of the stand-alone calculation is the module, so the identifier does not need to specify the parent object’s identifier.
The identifier of the module is C_Coffee_Shop_Sales. You can change the module identifier by choosing save as and entering a name which you want to use.
Open the module in authoring.
Select Pastry inventory.date in the metadata tree and choose properties from the context menu.
The Ref property will be this:
[C].[C_Coffee_Shop_Sales].[pastry_inventory].[transaction_date]
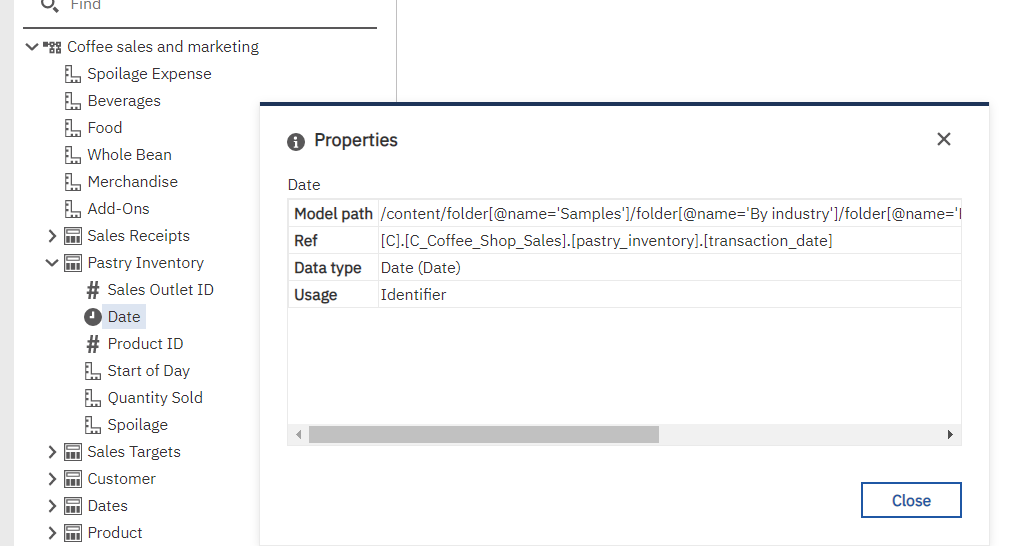
If you added Pastry inventory.date to the report or to a calculation you would see a similar format of identifier.
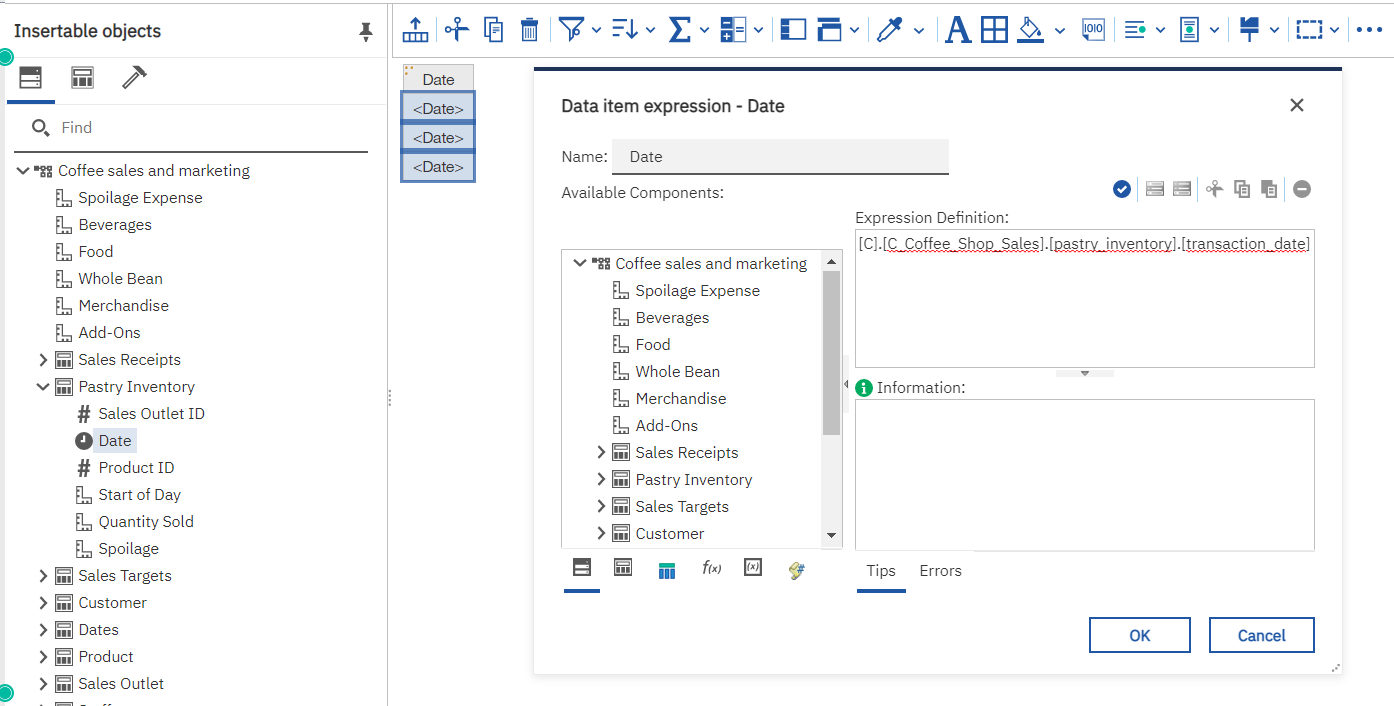
The identifier is also used in SQL generation. This will be dealt with in detail in the next section, Identifiers and SQL tracing.
Select the Coffee sales and marketing module and choose new report from the context menu and choose to create a new list report.
Drag Pastry inventory.date into the report.
Choose more/show generated SQL/MDX.
Change the option to IBM Cognos SQL. You will see SQL similar to this:
SELECT
pastry_inventory0.transaction_date AS Date0
FROM
3943038890...pastry_inventory pastry_inventory0
GROUP BY
pastry_inventory0.transaction_date
As you can see, the SQL makes use of the identifier.
A report which has Whole Bean in it would generate SQL similar to that above. The identifier will be used as the alias of the calculation.
In the next section we will examine more closely an example where the identifier can be used to trace through the SQL.
An object from a module which is used in another module will tend to behave, and will have the same identifier, as if it was created in the destination module. For example, I brought the Coffee sales module into another module and then used it in authoring. The expression of Pastry inventory.date was this:
[C].[C_My_module_name].[pastry_inventory].[transaction_date]
In some cases you will see references to things such as M1 or C (as we saw earlier) etc. in expressions. They are arbitrary identifiers for data sources or source data modules and should not worry you too much.
Identifiers and SQL tracing
Perhaps the most useful application of identifiers is in tracing through SQL. In cases such as where columns are reused for role-playing, it is useful to be able to identify which instance of the column is being used in any particular context.
This is to investigate a technique which Cognos has taught for FM, where if you have a copy alias (rather than a shortcut) then you can rename objects so that the generated SQL is easier to trace.
Here is an example of role-playing in which a source query subject is used in more than one dimension. The data base used is the Cognos sample Great Outdoors Warehouse Data Warehouse (GOSLDW).
As you can see in this picture, there are two instances of Go Region Dim. One of the tables, with the identifier of GO_REGION_DIM_Retailers is being used in the Retailers dimension and the other, GO_REGION_DIM_employee, is being used in the Employee dimension. Because Go Region Dim belongs to both the Employee and Retailers dimensions, some way of defining an unambiguous query path needs to be implemented. We do this by creating an alias. In this case, it is a copy. Each instance of Go Region Dim has only a relationship to the other query subjects in its dimension.
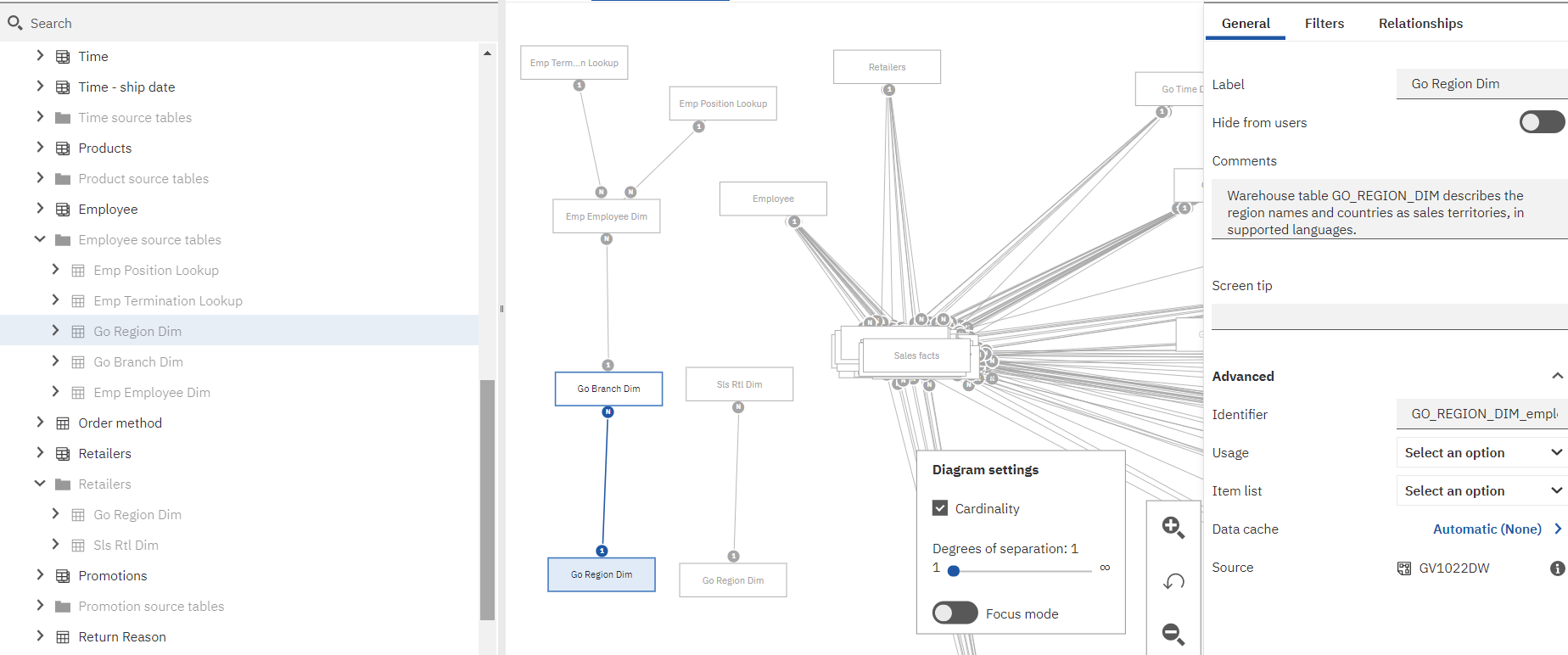
As you can see in the picture, the Employee dimension instance of Go Region Dim, GO_REGION_DIM_employee, has been selected and that selection has been indicated in the metadata tree and the diagram. On the right of the picture, you can see (most of) the identifier in the properties slide out. In the centre, you can see the relationship diagram of the module. On the left you can see part of the module metadata tree.
In the metadata tree you can see the Employee dimension, which is a view, which incorporates Emp Position Lookup, Emp Termination Lookup, Go Region dim, Go Branch dim, and Emp Employee Dim. Just below it is the Retailers dimension, which is also a view, created from SLS RTL DIM and the second instance of Go Region Dim. It is role-playing to provide the region and country names in which retailers are located.
Returning to the diagram, you can see a relationship between the Retailer dimension source tables, SLS RTL DIM and Go Region Dim. You can also see relationships between the Employee dimension source tables, Emp Position Lookup, Emp Termination Lookup, Go Region dim, Go Branch dim, and Emp Employee Dim. In both cases, there are no other relationships between the source tables and other tables in the module. Just to the upper right of the diagram you will see the Employee and Retailers dimensions. They have relationships to other tables, including the Sales Fact table.
This is part of the role-playing technique, which ensures that only one possible query path can be drawn between any two objects and that source tables for a dimension, unless it consists of a perfectly normalized set of tables, be incorporated into a denormalized structure so that column dependency can be specified and the dimension grains are correctly modelled. If you have taken Cognos modelling training, studied Cognos proven practices, or are familiar with the sample Framework Manager models, this will be quite comfortable territory, with the only new concept being column dependency, which replaces the FM determinant functionality.
I created the second instance of Go Region Dim by making a copy of the other in the module. I then changed the identifiers of both query subjects to correctly describe the roles that they would play. You will recall in one of the earlier illustrations that most of the identifier of GO_REGION_DIM_employee was visible in the properties slide out. I created relationships between the aliases and the other query subjects in the dimension.
Once the dimensions had been identified and the query paths laid out, I created views, which each incorporated the tables of one dimension. The source query subjects of each dimension have had the relationships between them and any other table removed, so that they only have relationships between other tables in the dimension and that there is only one possible query path between any two tables in the dimension. The removed relationships were then created between the dimensions and the other tables. This is also a technique taught in Cognos proven practices and Cognos training.
Among other things, by incorporating the objects of the dimension into one object it is possible to define valid column dependency, as the dimension has now been defined in a denormalized structure. The column dependency will allow you to properly normalize the metadata. In addition, by placing the dimension objects in one place they are easier for report authors and users to find them, understand their purpose, and to use them.
That identifier renaming for role-playing trick only works if you do it on a view. If you do it on a query subject you will get into a mess, so don't do it.
Example of identifiers in SQL
Here are two fragments of the generated Cognos SQL for a report which uses both the employee and the retailers dimension. If you were tracing through the SQL, you would be able to use this to confirm that the SQL is generating correctly, at least in regard to the role-playing. For the purposes of clarity and concision, I have omitted the complete SQL statement and included only the two fragments.
In this first fragment, you see that the Retailers dimension’s instance of GO Region Dim is identified, with the identifier in the select and group by clauses and as the alias in the from clause.
(
SELECT
SLS_RTL_DIM0.RETAILER_SITE_KEY AS RETAILER_SITE_KEY,
SLS_RTL_DIM0.RETAILER_KEY AS RETAILER_KEY,
SLS_RTL_DIM0.RETAILER_TYPE_CODE AS RETAILER_TYPE_CODE,
GO_REGION_DIM_Retailers.COUNTRY_CODE AS COUNTRY_CODE,
GO_REGION_DIM_Retailers.REGION_KEY AS REGION_KEY,
SLS_RTL_DIM0.RTL_CITY AS RTL_CITY,
SLS_RTL_DIM0.Prov_state AS Prov_state,
MIN(GO_REGION_DIM_Retailers.COUNTRY_EN) AS COUNTRY_EN
FROM
GOSLDW_DNB_DB2..GV1022DW.GO_REGION_DIM GO_REGION_DIM_Retailers
INNER JOIN SLS_RTL_DIM0
ON GO_REGION_DIM_Retailers.COUNTRY_CODE = SLS_RTL_DIM0.RTL_COUNTRY_CODE
GROUP BY
SLS_RTL_DIM0.RETAILER_SITE_KEY,
SLS_RTL_DIM0.RETAILER_KEY,
SLS_RTL_DIM0.RETAILER_TYPE_CODE,
GO_REGION_DIM_Retailers.COUNTRY_CODE,
GO_REGION_DIM_Retailers.REGION_KEY,
SLS_RTL_DIM0.RTL_CITY,
SLS_RTL_DIM0.Prov_state
),
This is the second fragment, where the Employee dimension’s instance of GO Region Dim has been incorporated into the SQL.
(
SELECT
EMP_EMPLOYEE_DIM0.EMPLOYEE_KEY AS EMPLOYEE_KEY,
MIN(GO_REGION_DIM_employee.COUNTRY_EN) AS COUNTRY_EN
FROM
GOSLDW_DNB_DB2..GV1022DW.EMP_POSITION_LOOKUP EMP_POSITION_LOOKUP0
INNER JOIN EMP_EMPLOYEE_DIM0
ON EMP_POSITION_LOOKUP0.POSITION_CODE = EMP_EMPLOYEE_DIM0.POSITION_CODE
INNER JOIN GOSLDW_DNB_DB2..GV1022DW.EMP_TERMINATION_LOOKUP EMP_TERMINATION_LOOKUP0
ON EMP_TERMINATION_LOOKUP0.TERMINATION_CODE = EMP_EMPLOYEE_DIM0.TERMINATION_CODE
INNER JOIN GOSLDW_DNB_DB2..GV1022DW.GO_BRANCH_DIM GO_BRANCH_DIM0
ON GO_BRANCH_DIM0.BRANCH_CODE = EMP_EMPLOYEE_DIM0.BRANCH_CODE
INNER JOIN GOSLDW_DNB_DB2..GV1022DW.GO_REGION_DIM GO_REGION_DIM_employee
ON GO_BRANCH_DIM0.COUNTRY_CODE = GO_REGION_DIM_employee.COUNTRY_CODE
GROUP BY
EMP_EMPLOYEE_DIM0.EMPLOYEE_KEY
)
Relational members
Relational members have their own identifier syntax. It is similar, in a broad sense, to the member unique name of DMR (Dimensionally-modelled relational, which is the dimensional objects modelled in Framework Manager) and OLAP members. Here is the identifier for one member, in this case Whole Bean/Teas, of the product group column of the product table of the Coffee sales and marketing module.
product.product_group->[Whole Bean/Teas]
#CognosAnalyticswithWatson