The purpose of this blog is to explore various connection types for analytics projects and in particular we'll focus on connecting to a cloud object storage type Amazon S3. We'll create a connection and connection data asset as part of a project and then expose the data for refining, profildemonstrate one of many data assets that can be used to work with data whether its database, file or through third-party like in this case Amazon S3.
So, the steps to bring in data from S3 as a data asset to a project which can then be refined, governed and/or cataloged is as follows:
1. Log into IBM Cloud Pak for Data Console and create a new project:

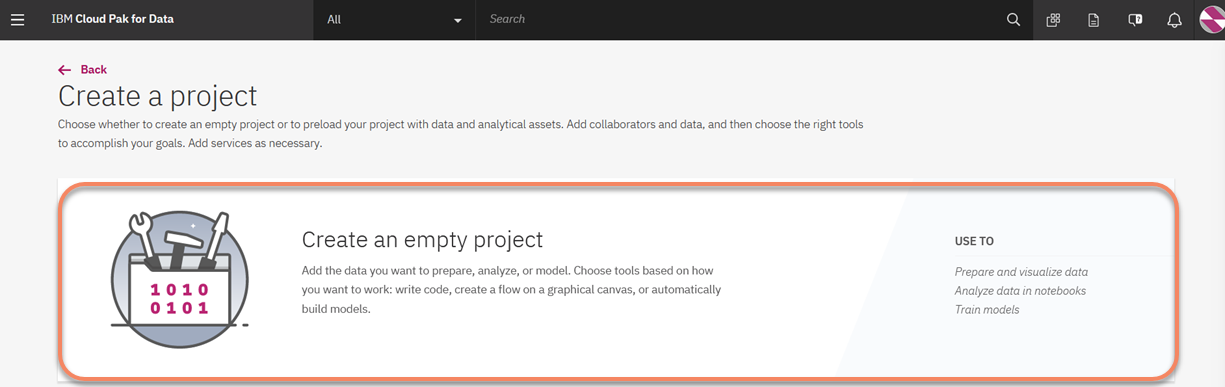
2. Select the empty project template
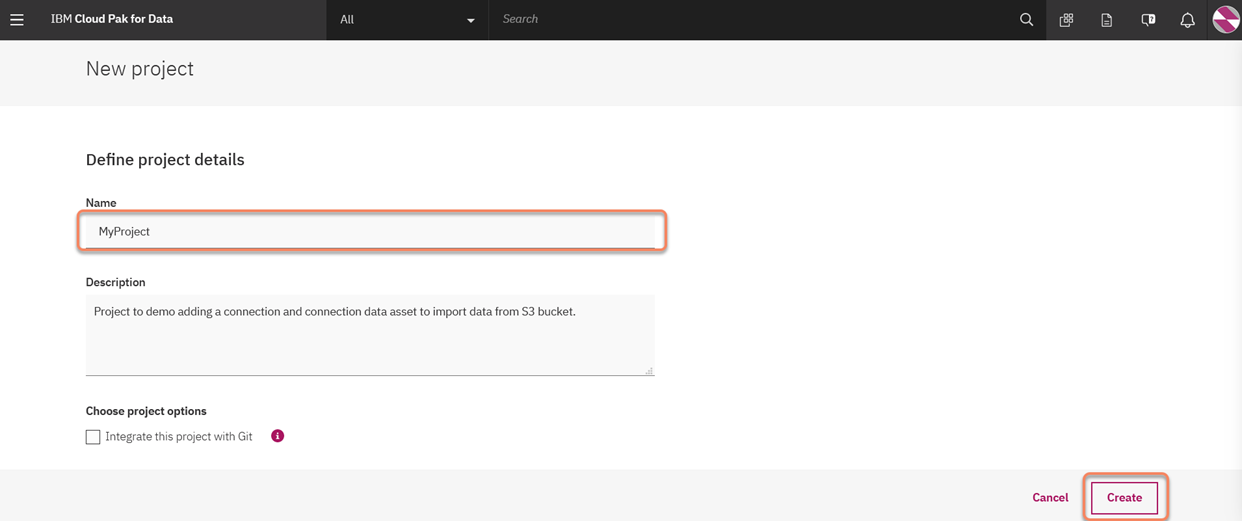
3. Give the project a name
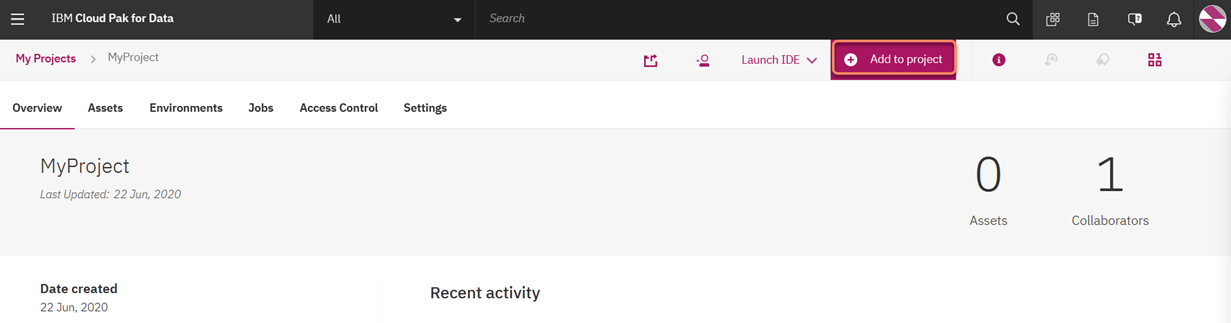
4. From within the project click on "Add to Project" and select the "connection" asset
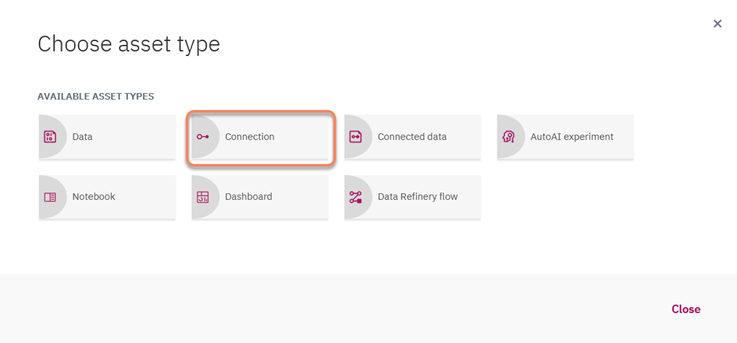
5. Select the Amazon S3 service under "Third-party services"
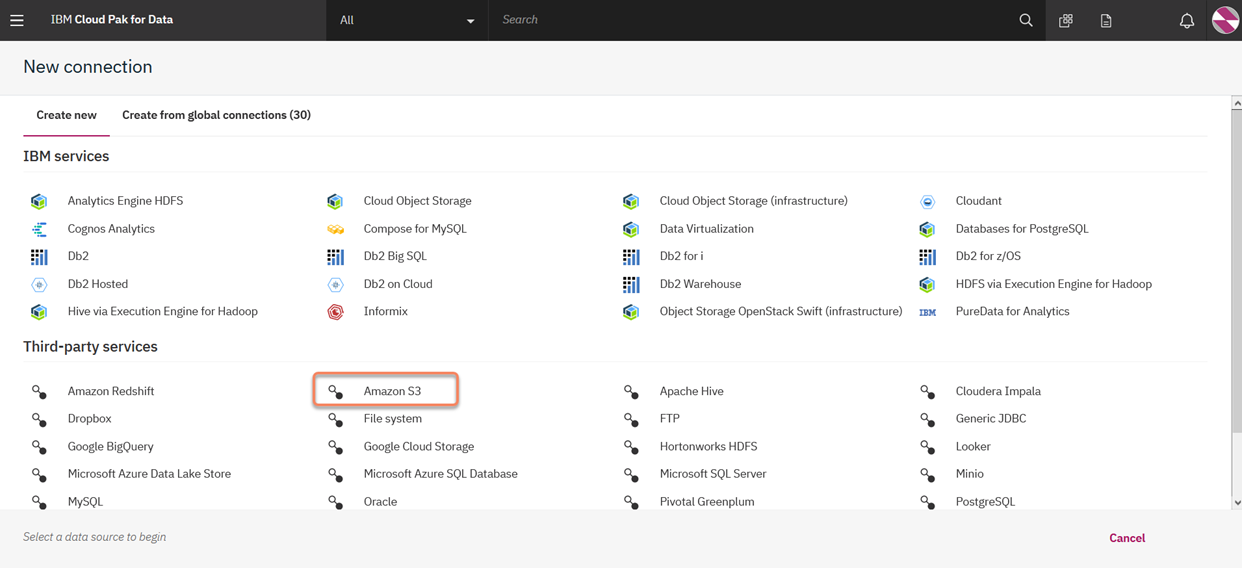
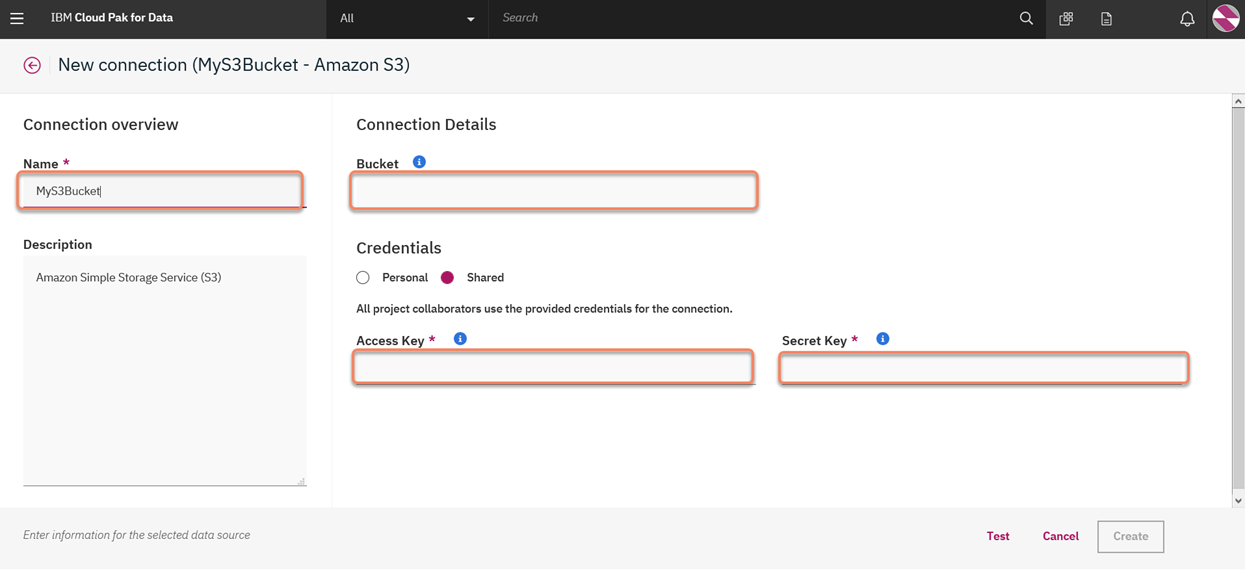
6. Here is where we need to gather details from AWS
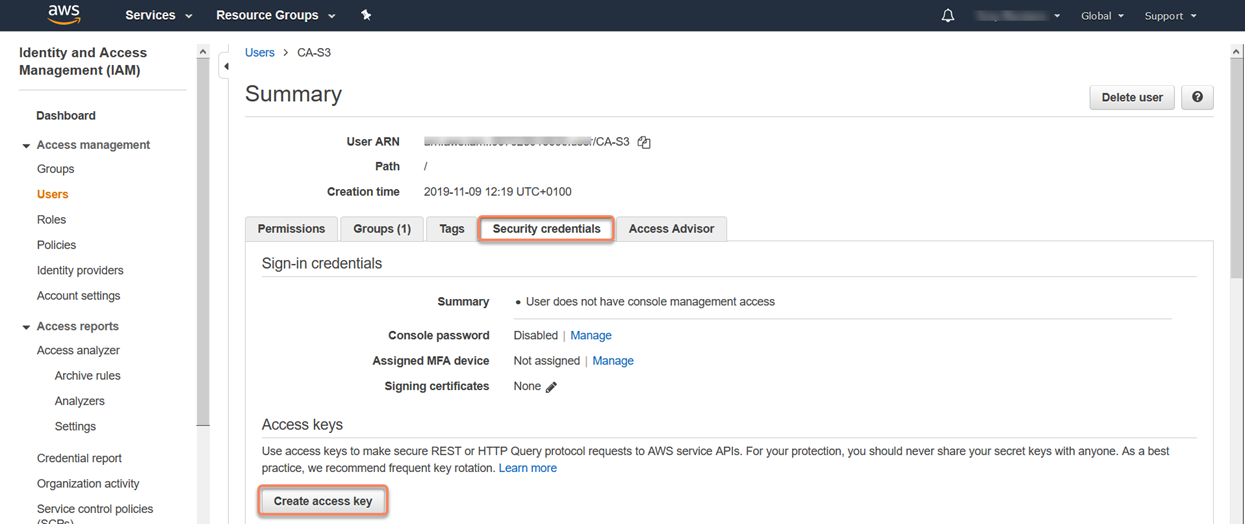
7. Switch to AWS Console and log in with your root account to create a new user and generate Access Key (API Credentials). From the AWS console select Services - IAM - Users. Here I've already created a user called 'CA-S3' and now will generate the API key pair by clicking on 'Security credentials' - 'Create access key'
8. Download the .csv file and open in notepad
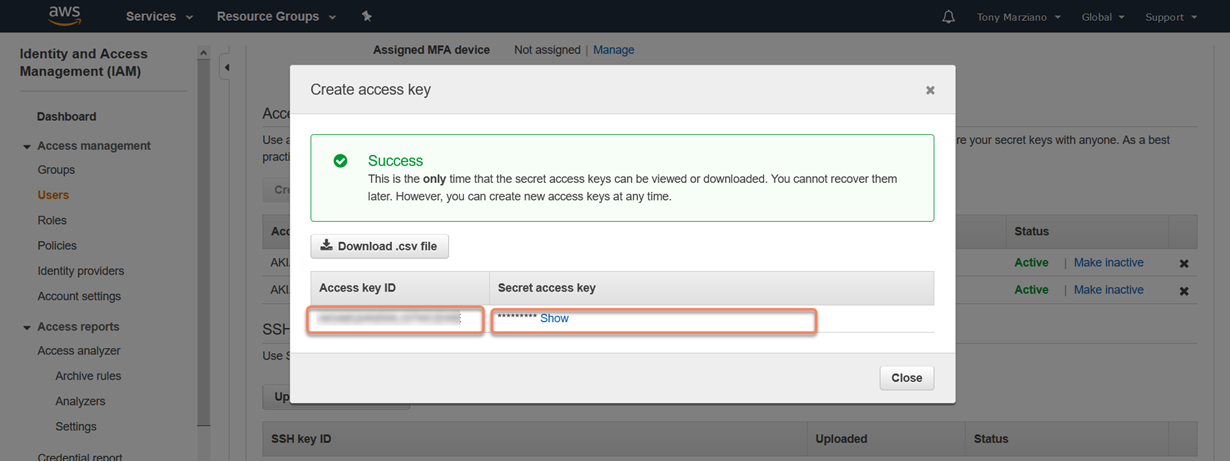
9. You can either click on the "Show" like to expose the secret access key and copy/paste both the Access key ID and Secret access key pair into notepad or download the .csv file.

10. Create an S3 bucket called 'mycp4d' and upload a data file (exported list from a gosales sample report) into the bucket:
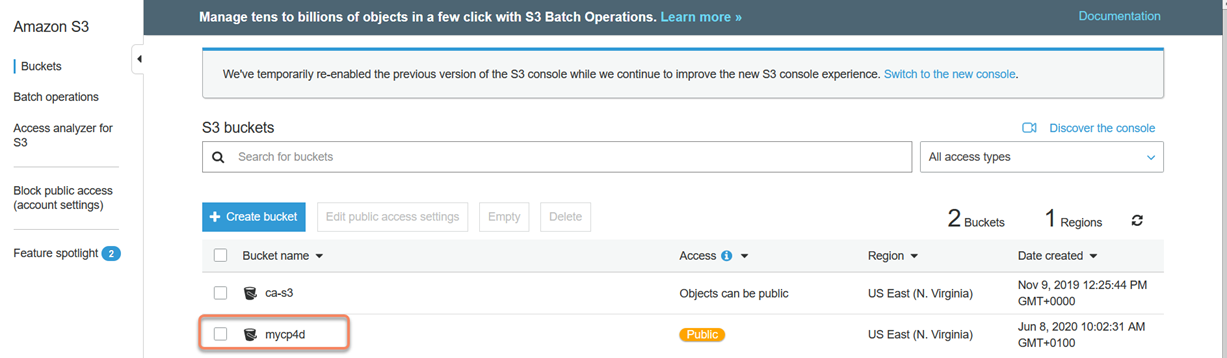
11. Click on "mycp4d" and then upload the CSV data file by clicking on "upload". Note: for the purpose of this example we are granting Public Access (not advisable) purely to demonstrate the feature but in the real world you would need to assign the S3 role read/list permissions.
12. Select "mycp4d" bucket and then uncheck "Block all public access":
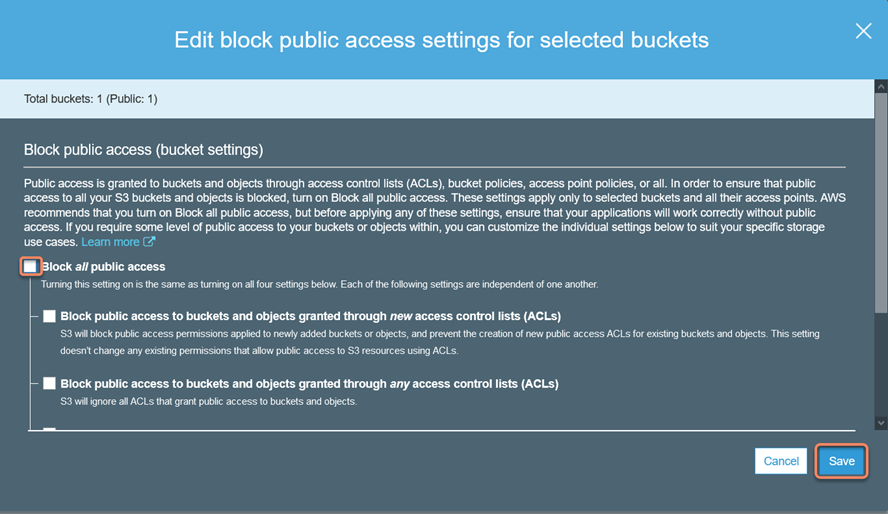
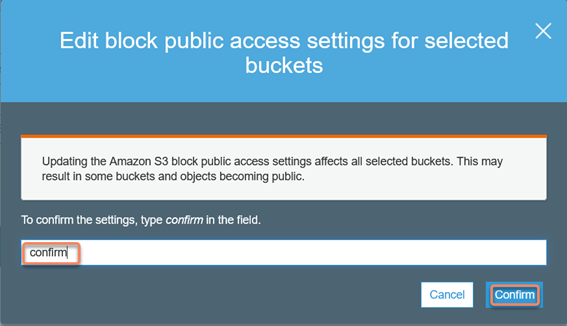
13. Click "Save" and they re-confirm by typing in the word "confirm":
14. To make sure the object is accessible grab the Object URL:
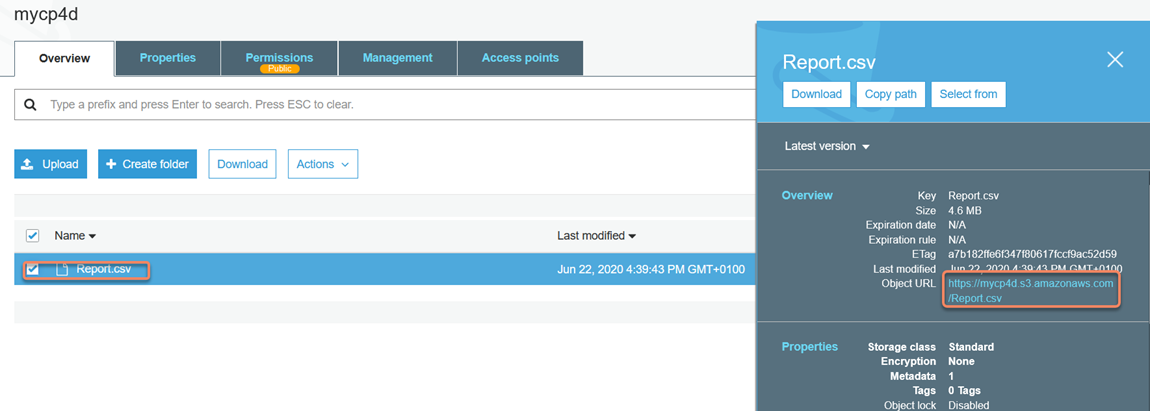
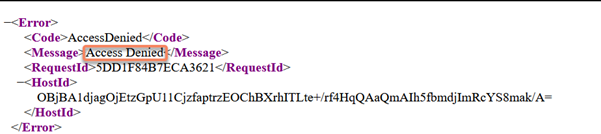
15. Open a browser session and paste the URL and if it fails with "Access Denied":
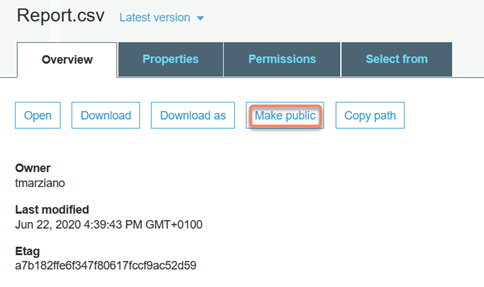
16. Click on the report object and click on "Make Public":
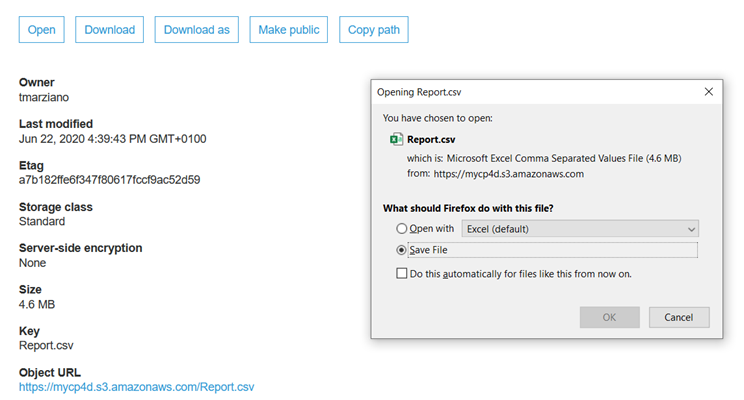
17. Now test the object URL again and it should be fully accessible
18. Grab the Access/Secret Key pair and go back to the Cloud Pak for Data Project and populate the credentials and Bucket name must be the same as the S3 bucket i.e. 'mycp4d' (in my case):
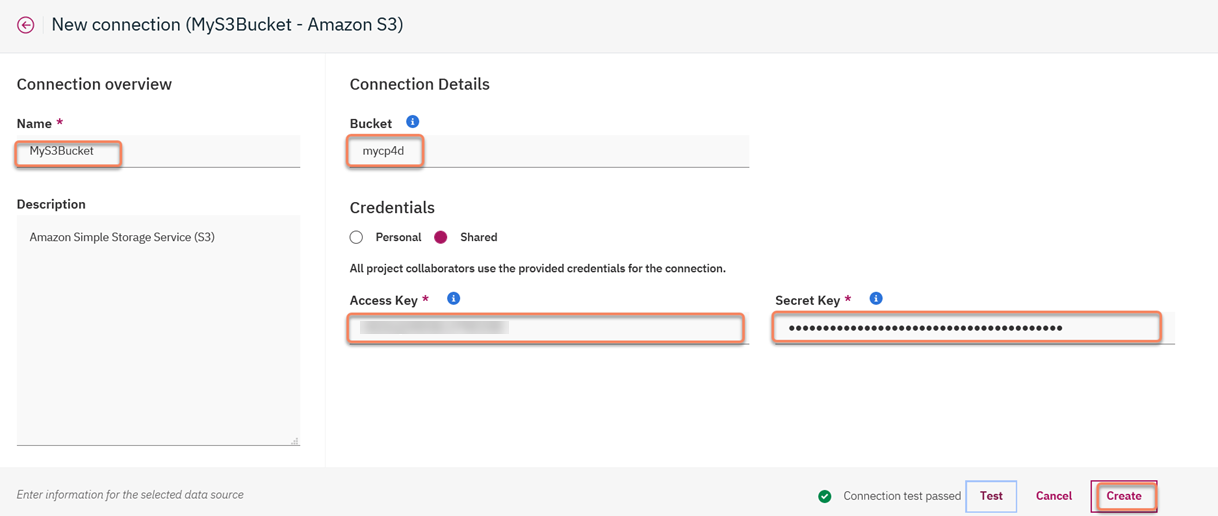
19. Click on "Create"
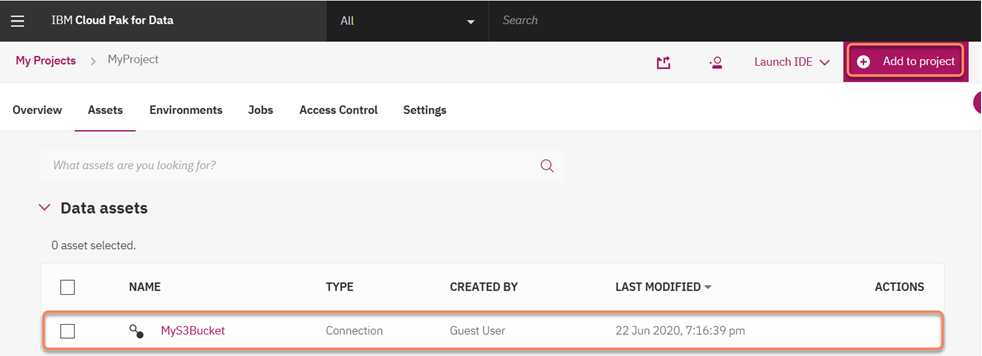
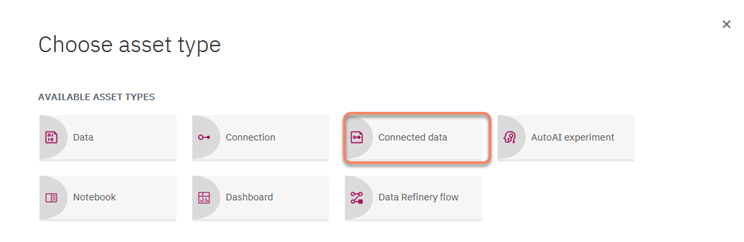
20. Next we click on "Add to Project" and select the Data Asset "Connection Data":
21. Next from the "Source" click on "Select Source" and select the Connection 'MyS3Bucket' and the name of the S3 object which here its "Report.csv":
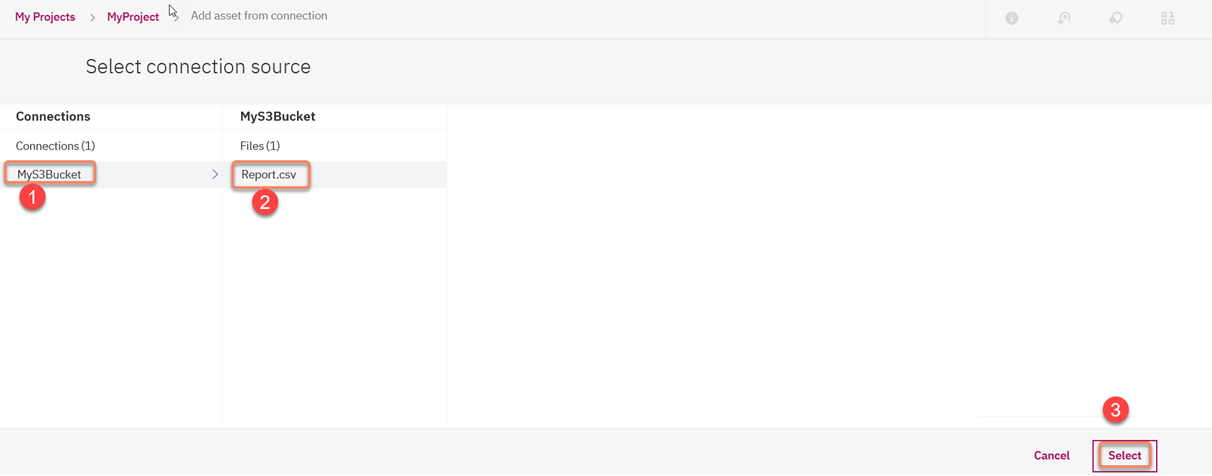
22. Click on "Select" and then "Create":
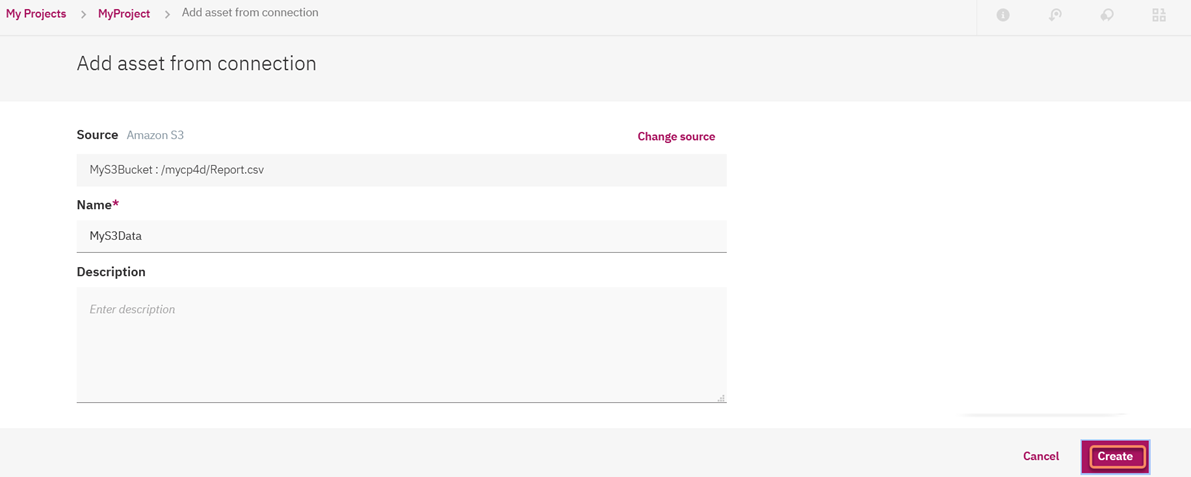
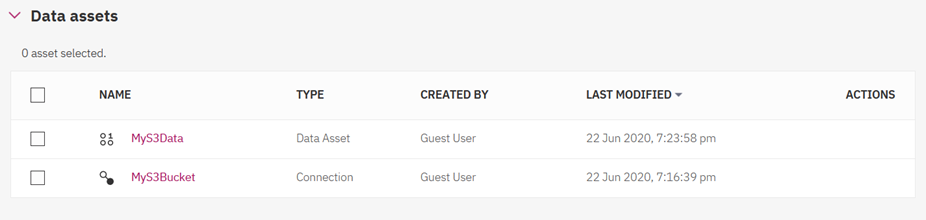
23. Finally to view the data click on the Data Asset "MyS3Data" or the 3 dots on the right side under Actions by hovering over the mouse cursor:
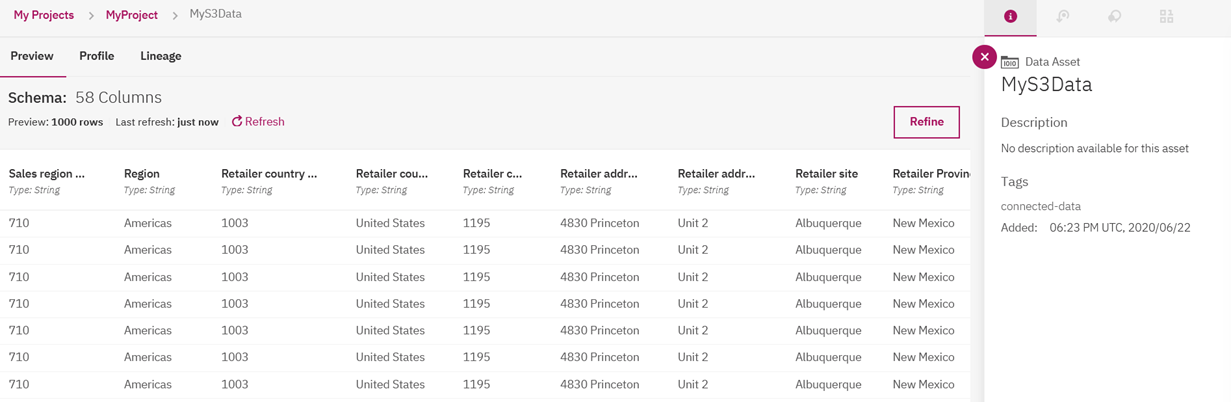
At this point you can apply Data Refinery (click on 'Refine') to clean and shape the tabular data by fixing or removing data that is incorrect, incomplete, improperly formatted, or duplicated. When you
shape data, you customize it by filtering, sorting, combining or removing columns, and performing operations.
Publishing to a catalog allows the persona i.e. Data Engineer/Data Stewart to share the assets across a larger community or other data personas to work on that project.
Additional Information:
Cloud Pak for Data Documentation
https://www.ibm.com/support/producthub/icpdata/
#Administration#CognosAnalyticswithWatson#LearnCognosAnalytics