Decision Optimization integration in Planning Analytics
This post describes the new productized support for Decision Optimization integration into Planning Analytics Workspace. This new integration is much easier to setup than any previous similar integration, without any code or configuration file required.
This is a reproduction of a blog post originally posted here.
Decision Optimization and Planning Analytics
I talk a lot about Decision Optimization (DO). This is how IBM refers to its Operation Research (OR) product line, including the CPLEX optimization engine and the different tools and platforms to develop, debug, tune and deploy optimization models to be integrated into business applications.
In particular, we have integrated in the Cloud Pak for Data (CP4D) platform all the functionality required to correctly develop, deploy and integrate optimization models into business applications. The real benefit of optimization is obtained by Business Users who can add their human expertise on top of optimal alternatives such as plans and schedules given by optimization algorithms, to build the smartest response to business challenges. For this, interactive what-if Line of Business (LoB) planning tools are critical.
Planning Analytics (PA) is a perfect example of platform that provides Line of Business the ability to create plans, including what-if scenarios. In a previous post, I described the benefits of using Decision Optimization on top of Planning Analytics (PA). This is the perfect combination. In that post I also commented about the prototype integration and provided access to this library along with some examples.
I am really happy to now introduce the official productized integration of PA and DO, see the announcement. The integration is done through a new direct capability to run CP4D batch jobs, reading input and writing output directly in the TM1 cubes, and triggered from an action button in PA Workspace (PAW). You can read some more complete documentation.
What it looks like
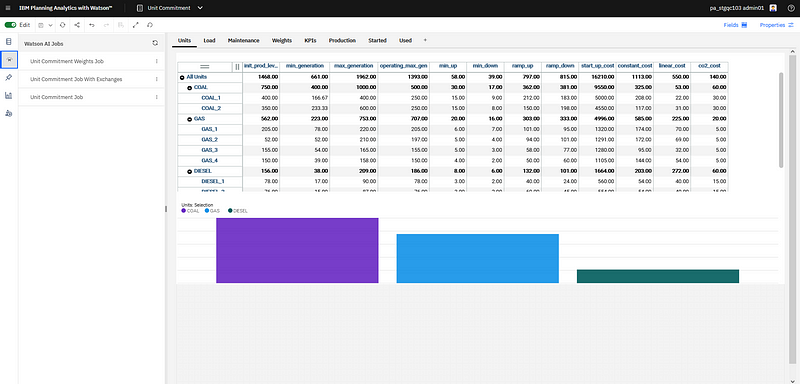
A PAW book integrated with DO looks like any PAW book. All of the usual PA functionality are available. Business Users can build and manage plans as usual. In our example, we start from a Unit Commitment application. I will not enter in this post into all the details of this particular business application and optimization problem. Let’s just say that given some electricity production units, some electricity demand, the problem is to define the optimal production planning, with respect to different objectives, such as minimizing the economical cost and/or the CO2 emissions.
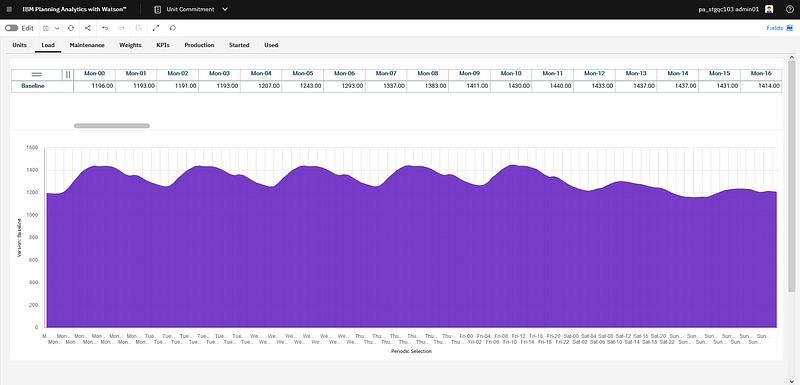 The weekly electricity demand to cover.
The weekly electricity demand to cover.
You see below some production plan for a set of units, with some charts to display the production over time per unit or unit time.
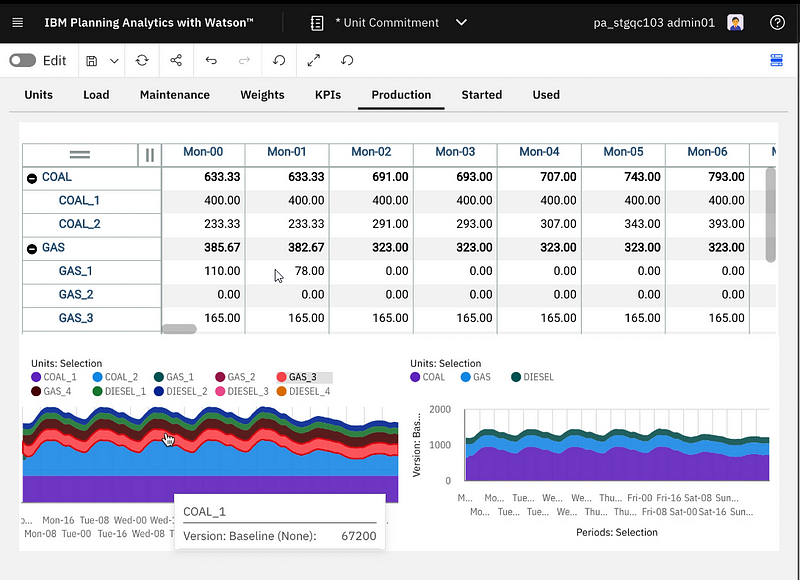 Unit production with some charts.
Unit production with some charts.
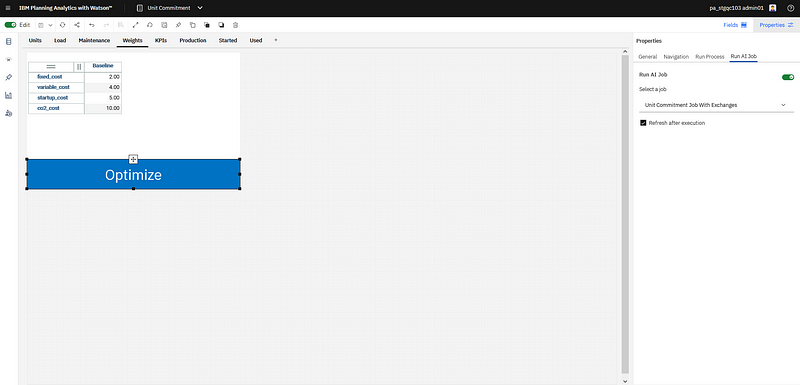
Instead of adjusting manually the production, you can set some importance factor weights and click on the optimize button. It will start some optimization model solving, and when finished the production and other output cubes will be updated.
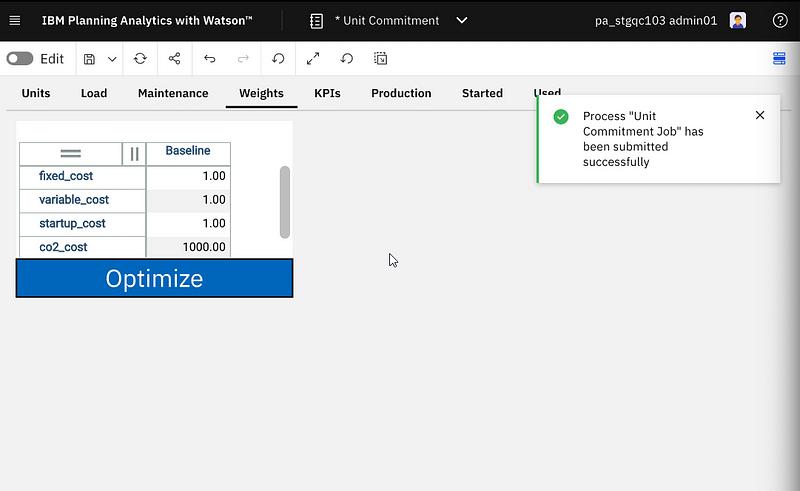 New “Optimize” button connected to DO job execution.
New “Optimize” button connected to DO job execution.
As usual, Planning Analytics cubes and dimensions can be used to that different versions of the plan are managed and compared. For example, a chart may be setup to compare the KPIs for the last horizon plan, the new horizon current proposed plan, and the new horizon optimal plan according to optimization.
Although this is not what a standard user would do, the following screen shot shows the different jobs started from PAW as they can be monitored in the CP4D deployment UI.
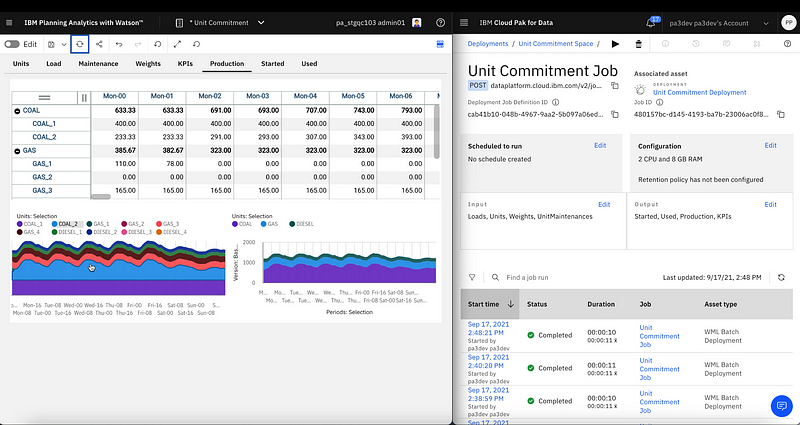 PAW on the left connected to CP4D on the right
PAW on the left connected to CP4D on the right
How it can be set up
In order to get some integration like the one shown above, you will need to follow these simple steps:
- get access a PA Cloud instance and CP4D as a Service
- get access or create some PAW book with some application on some cubes and dimensions
- set up the PA Views
- connect PA data from CP4D
- create the optimization model
- deploy the optimization model and create the job
- connect it from the PAW book
Get access to PA Cloud and CP4D as a Service
Currently the integration only works between the PA Cloud and CP4D as a service (aaS) versions. The integration between the on-premise versions should come later.
You need to set up or get access to an existing 2.0.68 release of Planning Analytics Cloud.
Getting access to CP4D aaS is much easier, as this is a managed platform, and, with an IBM id, you can get access and use some trial credits (Compute Unit Hours) to run your tests.
You might follow these step-by-steps videos to start with CP4D aaS.
Planning Analytics Workspace book
In order to add optimization capability to a PA application, you need to start from a PA application. In our case, the cubes and dimensions had already been created in PA, and a book with some views, pivot tables and charts created in PAW.
The input cubes are pretty simple:
- Units: the list of available units that can be used to produce electricity
- Load: the demand of electricity over periods
- UnitMaintenances: list of unit maintenances per period.
- Weights: the importance factors for the different objectives to optimize
Planning Analytics Views
In PA, data is stored on TM1 servers and represented using cubes and dimensions, while in the data science world, and with Decision Optimization, data is usually represented using tables, with rows and columns. Some mapping is hence necessary which can be very easily defined using PA views. A PA Cube view is an ordered list of dimensions (optionally filtered). The basic representation of a view applied on a cube is a table.
The first step to plug optimization into a PA application is to define the views which will be used to read input data and write back solutions. This is a very convenient way for the PA modeler and the data scientist to define what are the data that will be used as inputs and outputs for the optimization problem.
Creating a new view is extremely easy in PAW, as you just click on “Create a view” for one of your cube, drag and drop the different dimensions, set the desired filters and then save the view.
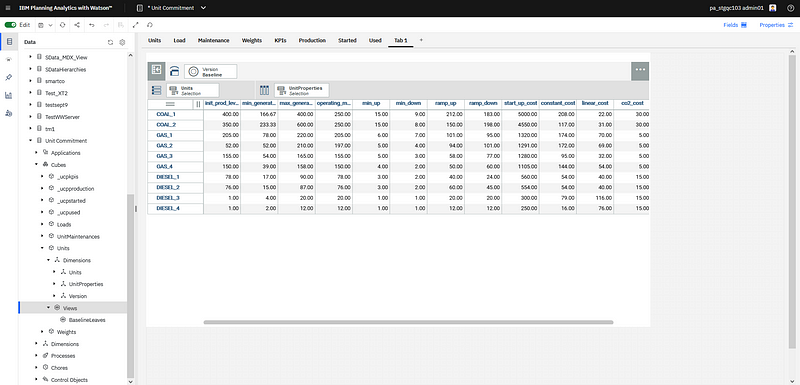 Creating a new view
Creating a new view
After the views are created, the PA administrator just needs to provide the credentials to access these views, and the list of views to the data scientist.
Data connection
The data scientist will then set up, in CP4D aaS, the data connection to the TM1 server.
In a project, a new Planning Analytics connection will be created with the provided credentials.
For details on the creation of connections in Watson Studio projects in CP4D, you might refer to this example with databases.
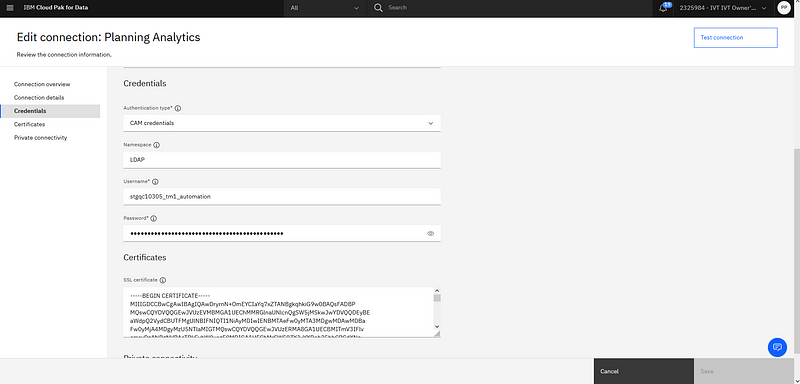 Example of Planning Analytics connection configuration in CP4D
Example of Planning Analytics connection configuration in CP4D
After this is done, and the connection is successfully tested, a new connected data asset can be created in the project for each of the input and output views. For each one, after a new Connected Data Asset has been created, you just need to follow the exploration, selecting the PA connection, and then the right cube in the list of cubes in this PA connection and the right view in the list of views for this cube.
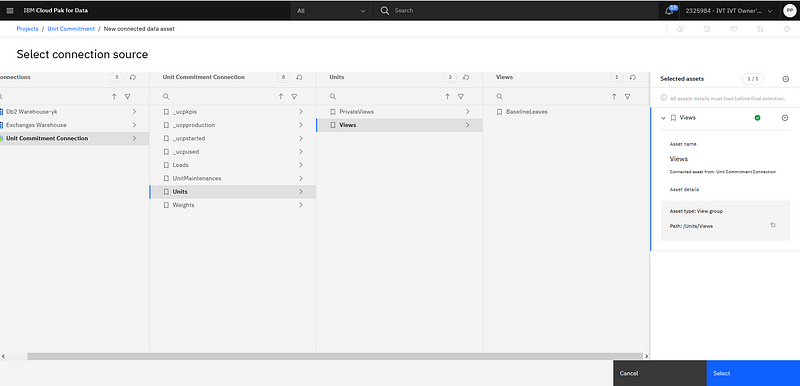 Selecting the PA view corresponding to a new connected data asset.
Selecting the PA view corresponding to a new connected data asset.
The created data assets are not including any real data, but only all the connection details, so that each time they are used, the data can be extracted from TM1 or written to TM1.
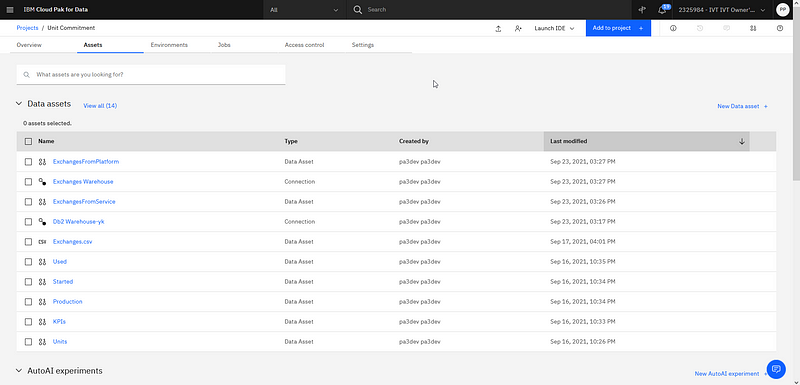 Different data connections (to TM1 and DB2) in the project with different connected data assets.
Different data connections (to TM1 and DB2) in the project with different connected data assets.
Optimization Model
Now the data scientist can process and create the optimization model. The easiest and recommended way is to use the Decision Optimization Experiments UI available in CP4D.
This post will not detail all the functionality and the typical usage flow of DO Experiments, please refer to several of my previous posts (overview, introduction).
The created connection data assets in the project will be directly available as data that can be imported in the default scenario of the experiment. When the data is imported a snapshot of the data at this moment is created and added to the scenario. Even if the data changes in TM1, this scenario is not altered. You can, if needed, create another scenario and import new snapshots or update the default one if you want to use alternative data. In general optimization modeling may benefit from using different snapshots to ensure the model will work as expected on different data sets. This is a major benefit of using the different scenarios in a DO experiment, and the direct integration of TM1 data makes it really straightforward to use.
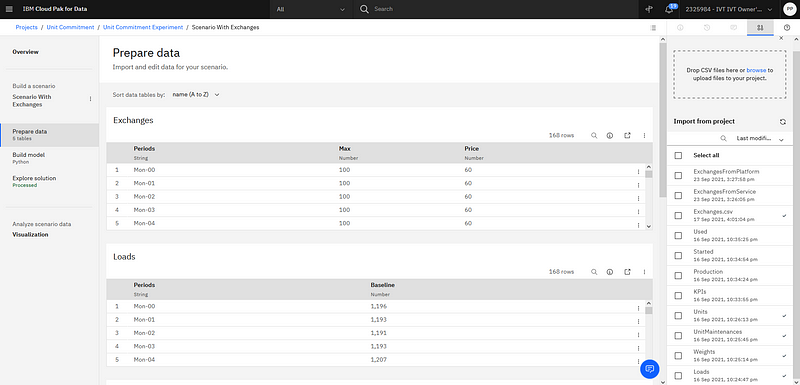 Import data from the project into the scenario
Import data from the project into the scenario
After the data is imported, you can write an optimization model, test it, debug it, etc. You can create visualizations to validate your model. You can compare using scenarios different formulations of your model and see how some formulation behaves with different data sets, imported as different snapshots of the same TM1 cubes. As usual, optimization models can be formulated in different ways, including OPL or Python docplex.
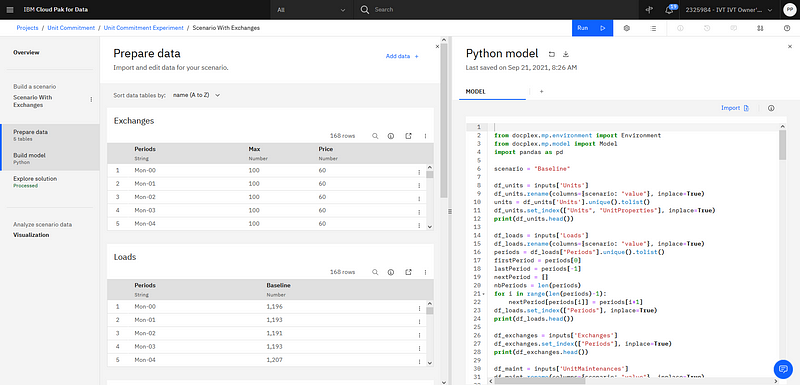 DO experiment UI with input data and optimization model in Python.
DO experiment UI with input data and optimization model in Python.
Deployment and Job
When the optimization model is finalized and its outcome could be validated by the business stakeholder in charge, you are ready to deploy it and make it available for integration into business applications.
For details, you can refer to this post about the flow to “save model for deployment” from experiments, then “promote” the model from the development project to the deployment space, and then create deployment and jobs in the deployment space.
In this case, the platform job can be associated with the same connected data assets from the project that have also been promoted to the space. As a consequence, each new run of this job will use the TM1 repository as data source. In the production case, there is no snapshot, each run will directly use TM1 live data.
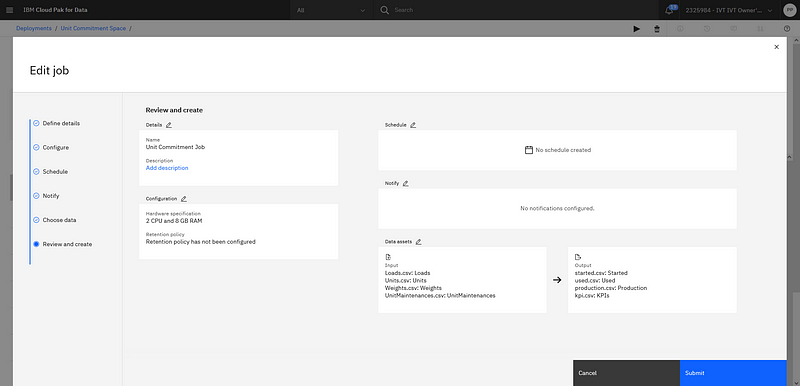 Job configuration where input and output can be connected with TM1 connected data assets.
Job configuration where input and output can be connected with TM1 connected data assets.
After the job is created, you can execute a first test run from the CP4D UI, that will read data from TM1, solve the optimization model and push the solution back into TM1. You can also monitor all runs of this job in the CP4D UI.
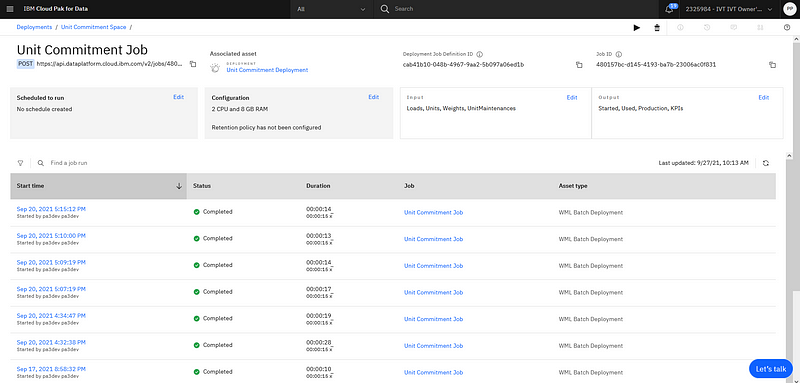 Monitoring of the different runs.
Monitoring of the different runs.
Of course, you don’t want the PA modeler to be required to log into CP4D to run these jobs as shown above.
Final Integration
You will need first to set up in the administration panel the credentials (API key) and the deployment space you want to link.
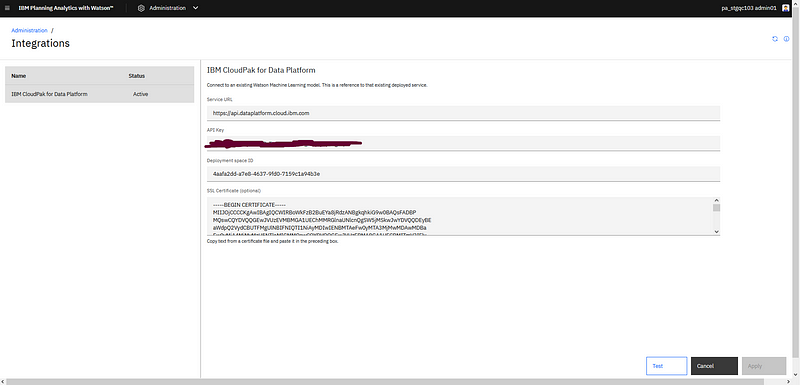 Set up CP4D integration credentials
Set up CP4D integration credentials
Then, as a modeler or administrator, from the edition mode, you can run CP4D jobs as Watson AI Jobs, as shown in the following screenshot.
 Run jobs from PAW
Run jobs from PAW
Of course, in practice, you will prefer to create an action button (in any page of the book) and associate it with the desired CP4D Job.
 Actin button linked to the CP4D job.
Actin button linked to the CP4D job.
You can use different optimization jobs for different actions in your book.
Conclusions and next steps
This post hopefully convinced you of how easy it is to setup this integration, without any code to create the data integration, the data mapping, or the optimization execution and monitoring. There is no additional configuration file and the basic functionality of PA and CP4D has been used.
Among all the steps listed above (I tried to cover every single detail), only the data model creation in Planning Analytics and the optimization model creation in Decision Optimization require some real effort. Each other step should be a matter of a few minutes. And in general, one would start from an existing PA data model and application and only create and integrate a new optimization model, or, in the other way, start from an existing optimization model, and create a PA application for business users to interact with it.
In practice, not only DO models can be run but any AI model deployed as a batch job in CP4D. It can be any type of AI developed, e.g. as a notebook and then deployed.
All this was possible mostly thanks to some key people in the PA team, Lee McCallum and Martin Philips to name two, in particular as it has been a real pleasure to work with them during these last months.
For more stories about AI and DO, or DO in Cloud Pak for Data follow me on Medium, Twitter or LinkedIn.
#PlanningAnalyticswithWatson