始めまして、IBMテクニカルセールス、Turbonomic担当の中島洋平と申します。
こちらには初めての投稿になります。今後、Turbonomicの担当者として皆様のお役に立つ情報を発信していければと思います。どうぞ宜しくお願いします。
はじめに:
早速ですが、Turbonomicをお試し頂いたお客様の99%から頂くであろうご質問に「Tubonomicってパフォーマンスの最適化をどんどん提案してくれるが、そもそも何を"最適"と判断しているのか?」というものがあります。
思いつくところでは、例えば過去1週間程度の期間に記録されたCPUのピーク時でしょうか?もしくは平均使用率の値の1.5倍程度でしょうか?もしくは、、、と、色々な方法が想像できますが、結論から申し上げると、"95番目のパーセンタイル値" というのが、その根拠になります。
パーセンタイルとは…?
正直、あまり聞きなれない言葉ですね。調べてみます。
パーセンタイル(percentile)|用語集|企業年金連合会 (pfa.or.jp)
計測値の分布(ばらつき)を小さい数字から大きい数字に並べ変え、パーセント表示することによって、小さい数字から大きな数字に並べ変えた計測値においてどこに位置するのかを測定する単位。
例えば、計測値として100個ある場合、5パーセンタイルであれば小さい数字から数えて5番目に位置し、50パーセンタイルであれば小さい数字から数えて50番目に位置し、95パーセンタイルであれば小さい方から数えて95番目に位置する。
つまり、"95番目のパーセンタイル値" という事は、↑に記載の通り、取得した統計情報(メトリック)の小さい方から数えて95番目に位置する値が最適な値、として判断される事になります。
一つ例を見てみましょう。例えばクラウド上のとある仮想マシンで以下の様なCPU利用率の推移があったとします。
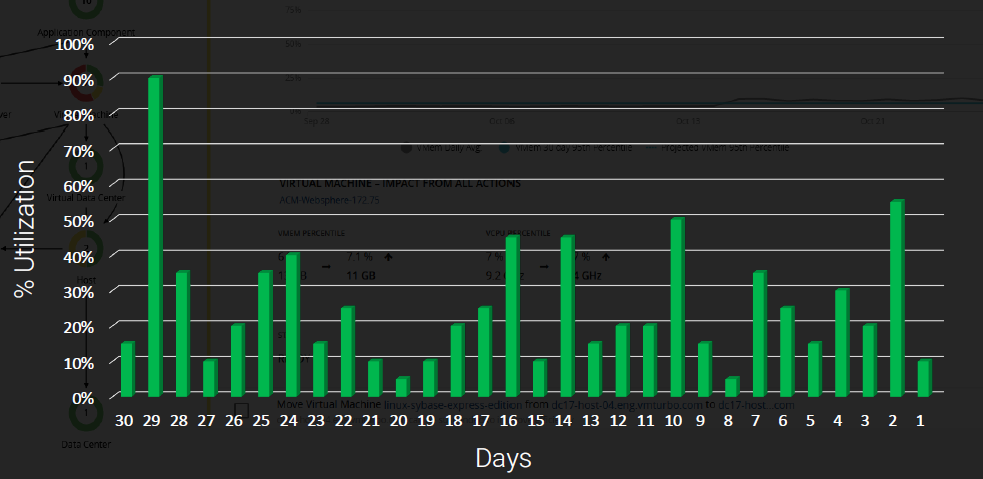
このグラフからは29日前に一度90%程度の使用率に達した事がありますが、それ以外については概ね50%以下の利用率に収まっている事が分かります。(例えば、この仮想マシンに修正プログラムを適用した際の突発的なピークだったのかもしれません)
この場合、適切なCPUの使用率を90%と判断してしまうと、あまりにも無駄が多い事になります。
※もちろんアプリケーションによっては必要なケースもありますが、一般的には無駄なリソースが割り当てられている状況と言えます。(*注1)
一旦この数値を小さい方から順番に並べ替えてみます。
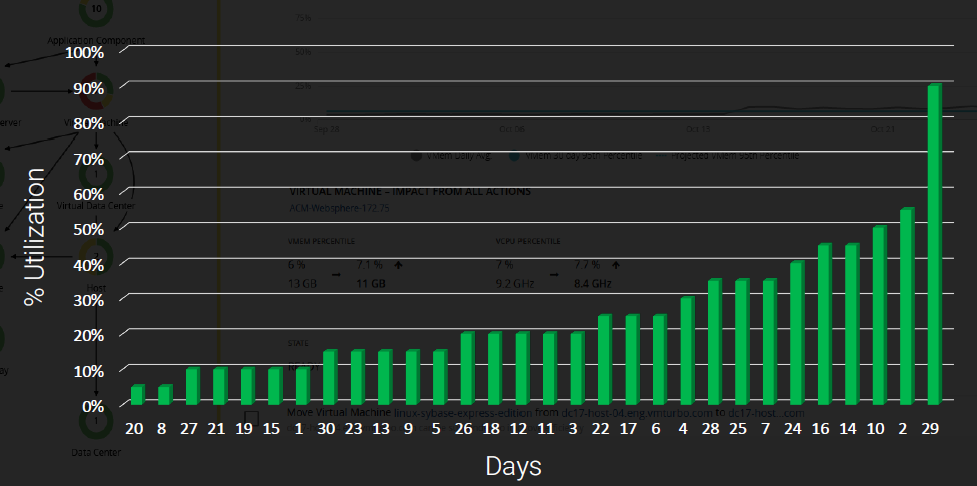
そしてここから100等分した場合の95番目に当たる数値がいくつであるか?考えてみます。
この場合、小さい方から29個目の値:CPU使用率55%のタイミングが該当します。
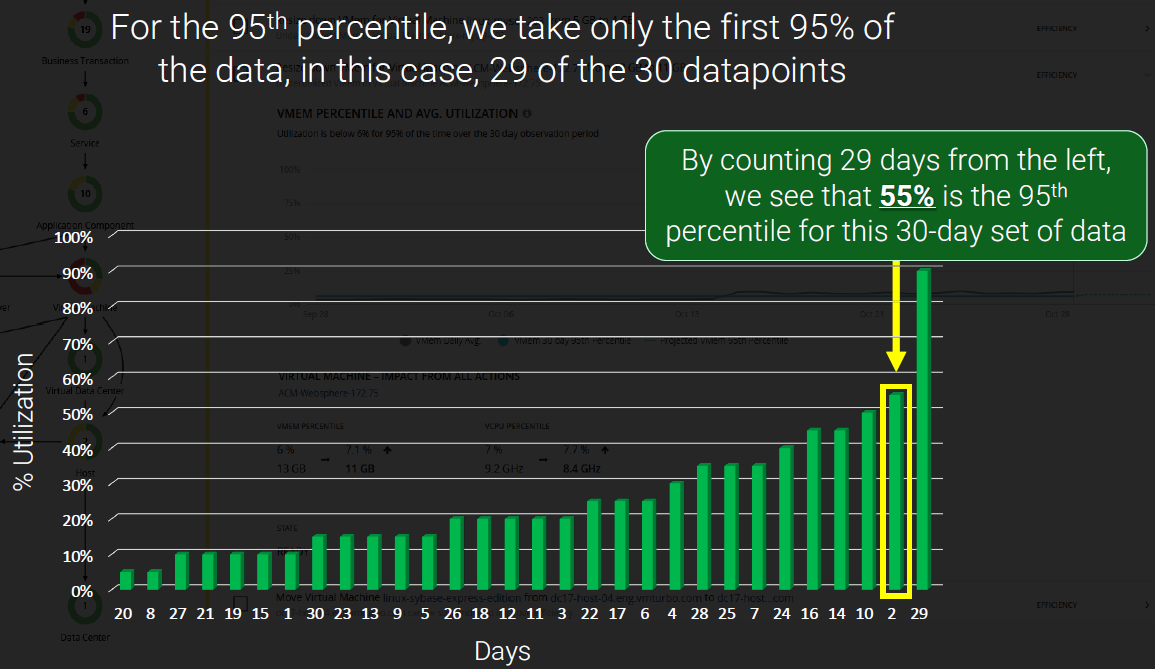
従い、この環境のCPU利用率の過去1カ月の"95番目のパーセンタイル値"は55%という事になります。
そして、これは同時に統計期間全体の95%については、この使用率以下しか利用されていない事になりますので、突発的なピークを除外するという観点では、かなり現実的な数値である事がお分かり頂けるかと思います。
そしてこの程度のCPU需要を満たすリソースを割り当てる事が、Turbonomic観点でのパフォーマンスの最適化という事になります。(*注2)
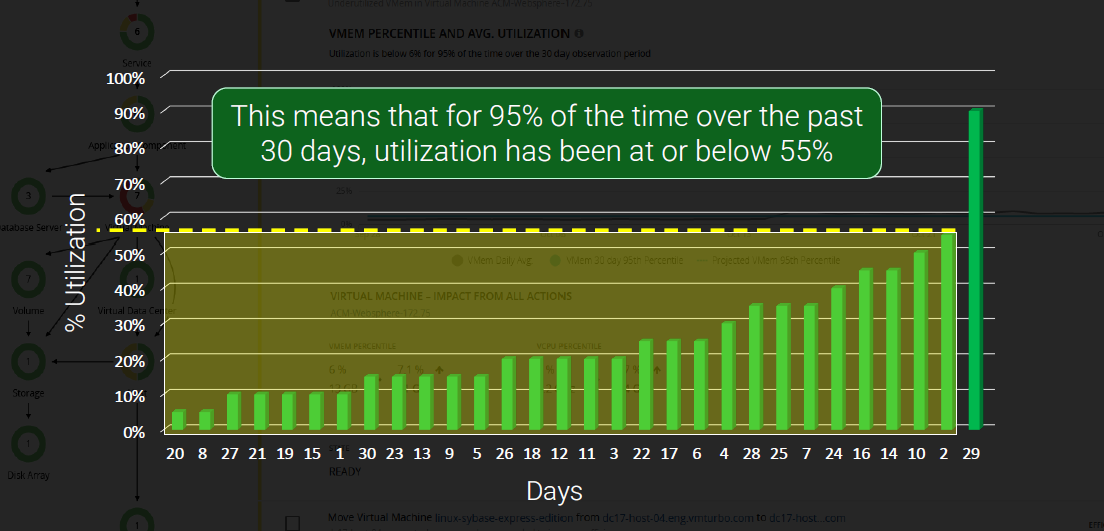
…では現状の55%分のCPUがあればよいか?
いいえ、話はもう少し複雑です。一般的に、CPUにしてもメモリにしてもストレージにしてもネットワークにしても、その上限値(使用率100%)に近づくにつれて、徐々に本来のパフォーマンス(レスポンスタイムなど)に影響が出てくる事は皆さんご認識かと思います。
これは以下のようなグラフで表す事が可能で、多くの環境では概ね70%程度までの使用率であれば特に問題の無いレスポンス(緩やかな上昇)で動作しますが、70-80%を超えたあたりから二次曲線的にレスポンスの劣化が見られるようになります。
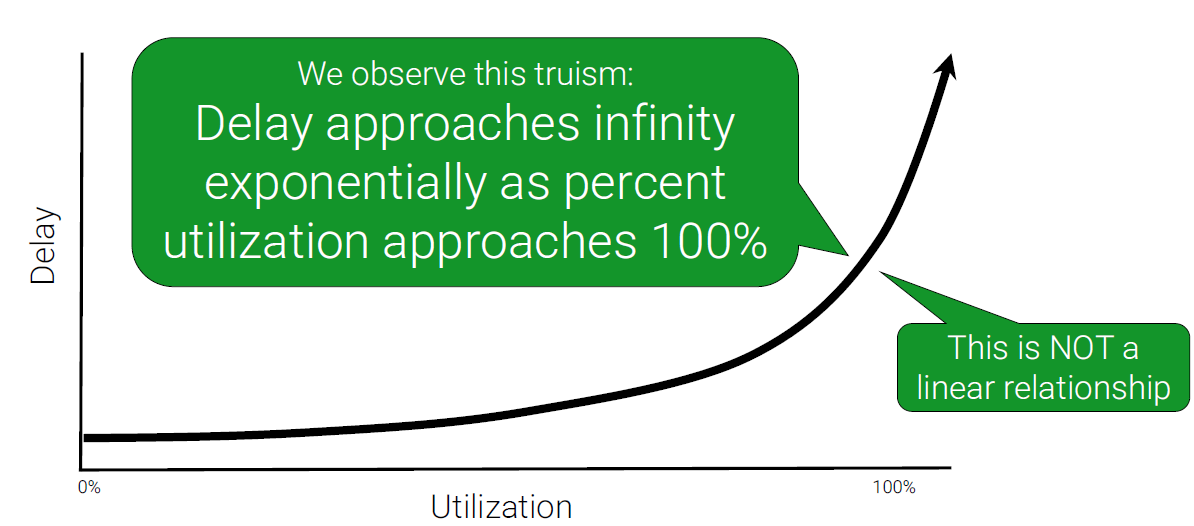
つまり、前述の95パーセンタイル値で割り出した最適なCPUの割り当てが、その時点での使用率100%になってしまってはやはりパフォーマンスに影響が出ると考えられます。
目標とする利用率(Target Utilization)
…では目標とする利用率(Target Utilization)はどこに置くべきか?という議論となりますが、この点、Turbonomicでは、世界中のお客様環境での実績も踏まえ、例えば対象がクラウド上の仮想マシンのCPUである場合、そのDefault値を70%としており、この70%に可能な限り近づく様、各種アクションをリアルタイムで繰り返し提案・実行し続ける事になります。
https://www.ibm.com/docs/en/tarm/latest?topic=cloud-vm-policies

従い、例えば対象の仮想マシンが16vCPU構成であった場合、単純計算では以下の様なロジックが用いられている事となります。
トポロジ・統計情報より:
・現状の構成:16 vCPU
・パーセンタイル95の値:55%
・実質利用されているvCPU数: 16 * 0.55 = 8.8 vCPU
Turbonomicが考える理想的な状況:
・Target Utilization 70%を踏まえたあるべきCPU数:8.8 / 0.7 = 12.57 vCPU を確保すべし
・CPUに関して設定される目標:16 vCPU -> 13vCPU に減らす
・最終的に生成されるアクション:13vCPUを満たす最適なインスタンスタイプに変更
まとめ
今回は一例として仮想マシンのCPU割り当ての最適化の背景についてご紹介させて頂きましたが、この考え方はCPUだけではなく、Turbonomicのあらゆるパフォーマンスのメトリックの判断に於いて類似したロジックが用いられています。(対象によってそのDefault値等は多少異なります)
ただ、アプリの利用状況などで刻一刻と各種リソースの利用状況が変化し続ける中、CPUの "Target Utilization" だけではもちろん適切な構成は決められませんので、実際に生成されるアクションはその他の各種メトリック(メモリ、ストレージ、ネットワークを始め、オンプレ環境であればSocket/Core比率やReadyQueなど、クラウドであればインスタンスファミリーやReserved Instance等の利用状況 etc...)も含めた情報をリアルタイムに多次元分析する事によって、最適なアクションを提案・実行し続けている、という事になります。
如何でしょう、これらの計算が、例えば特定の環境内で 10や20程度であれば人手でもどうにかなりそうですが、100以上の対象、ましてやマルチ・ハイブリッドやk8s環境なども入って常時実行し続けるとなると、、、信頼性のあるアクションを提案する事は容易ではない事、ご想像頂けるかと思います。
また、これらの処理は、これまで一般的に利用されてきた従来型の閾値監視による ”異常を検出してから” の事後対応ではなく、常に "異常が発生する前に" あるべき姿に近づけるプロアクティブなアプローチとなりますので、管理者様の運用負荷を抜本的に軽減する事にも繋がります。
、、、以上、Turbonomicというとインフラ "コスト" の最適化が注目されがちですが、こういったところにもこの製品の価値の一端を感じて頂ければ幸いです :)
*注1
------------------------------------------------------------
パーセンタイルのDefault値は "95" となりますが、例えば重要な本番システムなので、より厳しい値(パーセンタイル値を上げたい)といった場合や、逆に、検証環境なのでもっとアグレッシブにリソース割り当てを制限したい(パーセンタイル値を下げたい)といった場合は、運用に合わせて変更頂くことが可能です。(また、対象も自由に選択可能)
https://www.ibm.com/docs/en/tarm/latest?topic=cloud-vm-policies
設定画面例:

*注2
------------------------------------------------------------
本記事では、”30日分” のメトリック統計からのパーセンタイル値を指標としてご紹介しておりますが、こちらはアクションを生成する際に参照される、取得済みメトリックの “最長” 期間のDefault値になります。
実際には以下の ”最長” 値と ”最短” 値が存在し、この期間内のメトリックからパーセンタイル値が計算されます。(これらの値は設定にて変更可能)
・最長:90日間
・最短:None(なし)
従い、メトリック収集開始後、何らかのメトリックが採取され次第、Defaultではすぐにアクションが生成される事になります。
一方で、取得したメトリックが余りにも少ない状態でのアクションは無視したい、といった場合は、このMin Observation Periodを1日などに変更する事で、最低限1日分のメトリックを採取した後に最適化アクションが生成される事になります。
(接続したら直ぐに何らかの効果が見たいところですので、Defaultでは敢えて"None"が初期設定となっていますが、実際の運用では7日などに変更されるケースが多いかもしれません。)
※なお、Noneの状態で実際にアクションが実行された後は、最低4時間は次のアクションは生成されないものとなります。
設定画面例:

