Tabular data is everywhere, from spreadsheets and databases to tables embedded in text documents. Table Question Answering in NLP refers to a specific task where the objective is to answer questions using the information provided in tabular data.
The questions are posed in natural language which means they are written in the way humans normally communicate, rather than in a structured query language like SQL.
The challenge in table question answering is to correctly interpret the question and then map it to the relevant parts of the table. This involves understanding the semantics of the question, identifying key terms, and figuring out how these relate to the data in the table.
Tables can vary greatly in their structure and content, and questions can be asked in many ways. A robust table question-answering system must be capable of handling this variability effectively.
There are two broad ways to perform Question Answering on tables:
1. Use Pre-trained language models like TAPAS, TabT5 developled by Google, TAPEX developed by Microsoft. However, these approaches have context length limitation as these models use transformer under the hood. Thus, these approaches cannot be used for tables whose size is more than the context length which in most cases is 512.
A. TAPAS Architecture – TAPAS model architecture is based on BERT’s encoder with additional positional embeddings used to encode tabular structure. Table is flattened into a sequence of words and is then concatenated with the question tokens before the table tokens.
B. TAPEX Architecture – TAPEX model is based on encoder-decoder architecture and uses GeLU activation function. Table is flattened into a sequence of words and is then concatenated with the question tokens before the table tokens.

In the above Figure, we can see that, question is concatenated with flattened table and the same is fed into the model to output the corresponding execution result (which in this case is “Pairs”).
2. Use Text to SQL approach. The core idea is simple: allow users to input a natural language question and then translate that question into a SQL query to retrieve the answer from a database.
This process has several benefits. First, it makes it possible for people who are not experts in SQL to query data. This can be helpful for businesses, researchers, and anyone else who needs to analyze data. Second, it makes data more accessible and engaging. When people can ask questions about data in their own language, they are more likely to be interested in the results. This can lead to better decision-making and understanding of the world around us.
Text to SQL task can be implemented in two ways:
1. 1. Few-shot learning – This method involves providing few shot examples of User Query, Table schema and Target SQL as context to LLM. Add user question to this context and LLM will generate a SQL Query which then can be executed over database table to obtain desired output. LLMs pretrained over coding data and queries can be utilized for this task as they have basic knowledge about the task and expected outcome from pre-training phase.
This approach can be used for simple queries and scenarios where queries pattern doesn’t change much, however for complex queries this approach will not be scalable. Besides, there is a good chance of hallucination from LLM.
2 2. Fine-tuning – This method involves fine-tuning a lighter language model like T5, BART, Flan – T5 in a supervised fashion, that utilizes encoder-decoder architecture under the hood. In this case, SQL generation is seen as translation task, hence encoder-decoder model performs well than encoder only or decoder only models.
Model Input:
Model Input or fine-tuning dataset has primarily 3 columns: User Query in Natural Language, Table column names and label is SQL Query.

Above training data is used to fine tune below T5 Model
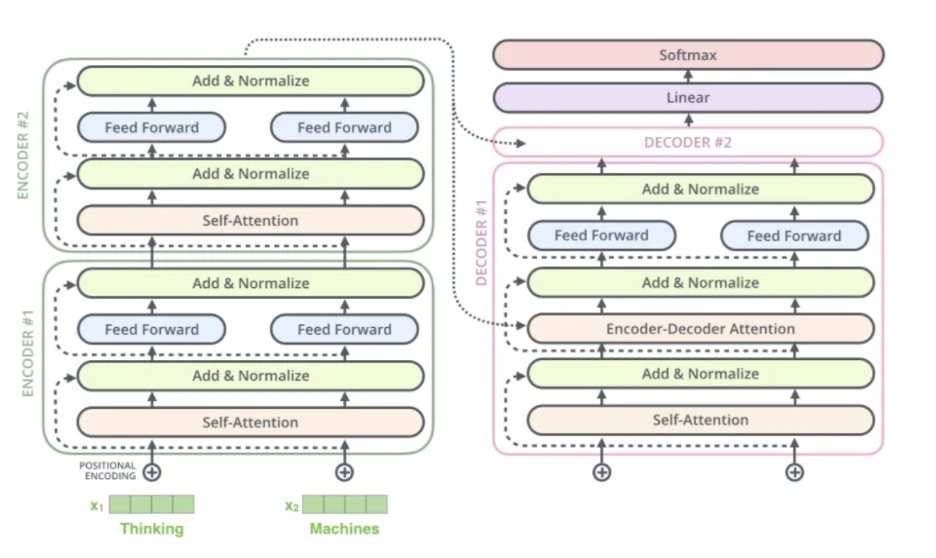
T5 Model Architecture
Fine-tuning Flan-T5 Model End-to-End flow:

Open-source datasets like Wiki SQl, Spider along with domain specific data is used to prepare dataset for fine tuning the model. Dataset which has User Question + Table Schema is used as input features for the model and SQL query is treated as a label for supervised learning. If a new question is prompted to the fine tuned model, it created a SQL query corresponding to User Question which then can be executed over database to generate the output table. The output table can then be shown to the user as a result.
An optional step here can be to further use a language model that can take table as input and generate text data or summary of that table in output. This step is optional as it would depend on specific use-case.
Conclusion:
In this post, I have mentioned about different approaches to solve Question and Answering on Tables. Using pre-tarined models like TAPAS, TAPEX has limitations, it cannot ideally handle large tables. Tables are flattened and send as input to model. . It works well when the table is relatively small, but it becomes infeasible when the table is too large to fit in memory. Other two approaches: Few- Shot prompting and fine-tuning the model seems more suitable for this task. However, choice of the approach will depend on few factors: 1. Computation resources, fine-tuning the model requires GPU which is not readily available to all the team in an organization. 2. Training dataset, one needs considerable amount of training data to carry out the fine-tuning of a language model. Lot of times, training dataset is not readily available, and effort goes in preparing the dataset, However, fine-tuning performs better than few shot prompting if above two constraints are met.
References:
TAPAS paper - https://arxiv.org/abs/2004.02349
TAPEX paper - https://arxiv.org/abs/2107.07653
T5 paper - https://arxiv.org/abs/1910.10683
Flan paper - https://arxiv.org/abs/2210.11416