Releasing in Robotic Process Automation (RPA) 30.0.0, OCP version 3.0.0, is a complete re-write of the existing RPA operator which brings enhanced rollout performance and greater levels of serviceability. This new operator introduces a complete Custom Resource (CR) overhaul and a bump of the API version from v1beta1 to a stable v1 version. For a full breakdown of the new CR, please refer to installation documentation.
This new operator is a clean break from the previous operator and it does not offer backwards compatibility with previous operand releases. This means that once the operator is upgraded, the operand must also be updated to the lasted 3.0.0 version. The migration is not seamless, for more information, please refer to the migration section in this blog and the migration steps in the RPA documentation.
New Architecture
The new operator is a complete re-write of the existing RPA operator making use of a framework-based approach for simplified and standardised resource deployment. This approach utilises a direct acyclic graph (DAG) based architecture which delegates rollout ordering to an algorithm, as opposed to manually deploying as was required in the previous operator. The algorithm can determine when a resources dependencies are satisfied and automatically begin the deployment of that resource. This is a parallelised process, and all resources are checked for satisfiable deployment conditions on every reconcile, which leads to massive performance improvements over the previous operator’s linear rollout.
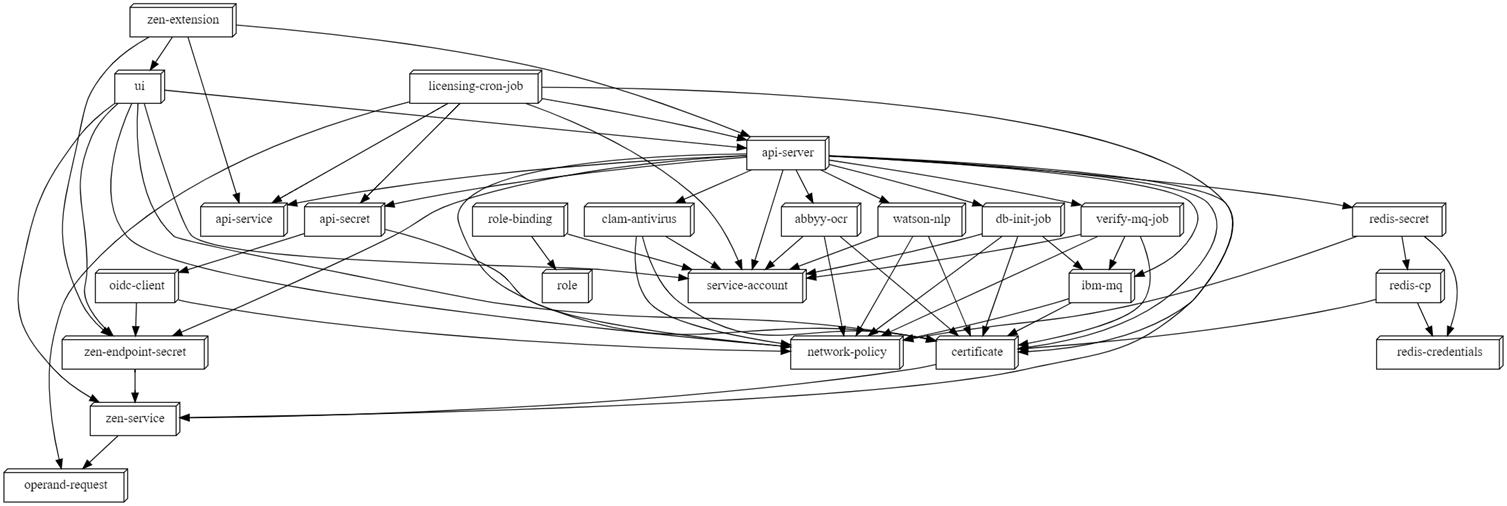
The following graph is the new RPA operator’s DAG model, where boxes are a component node and arrows point to dependencies.
The following screenshot shows a sample of the new operators’ conditions, the AwaitingVerify condition contains an array of components which are currently being deployed in the cluster in parallel.

If you are interested in implementing something similar yourself, or just curious how it works, IBM maintains an open-source Python implementation of this algorithm called oper8.
Serviceability
The new operator introduces a collection of new serviceability features to simplify the process of maintaining the instance.
Shutdown
A new CR attribute .spec.shutdown can put the RPA instance into a shutdown state to save consuming cluster resources without uninstalling the operand. This can be useful over periods where RPA usage isn’t expected but will need to be scaled back up at a moment’s notice.
Setting the value to “true” or “force” will scale down all Deployments to 0 replicas, effectively turning off the instance without uninstalling it.
Setting the value to “halt” will stop the reconcile loop on the operator controller pod so RPA will remain running, but the operator won’t continue rollout or update resources. This can be useful to maintenance and serviceability, where sweeping changes can be made to the RPA operator without interference from the operator’s reconcile loop. See the following section for a better way of disabling reconciliation on specific resources.
Setting the value to “false”, or removing entirely, will stop the shutdown and return the instance to a deployed state.
Hands-off!
The new operator introduces the rpa.automation.ibm.com/hands-off: ‘true’ annotation which can be applied to any resource the RPA instance is reconciling. This annotation stops the operator from updating/changing the resource, allowing for customisation of any resource deployed by the operator, even if it’s not supported directly through the RPA CR.
Simplified Scaling
We’ve introduced the idea of T-shirt size scaling into the operator, using the new CR attribute .spec.size will control the replica count for all components in the RPA instance. A full breakdown of the resource requirements can be found in the CR documentation, as well as fine-tuning configuration to change the replica or resource constraints of individual components.
Setting the value to “small” will deploy a single replica of all components, this is not recommended for production environments.
Setting the value to “medium” or “large” will scale the replicas of all components to 2 or 3 respectively.
It’s worth noting that these scaling parameters to not apply to the system queue provider, IBM MQ, which must be configured for high availability separately. Please refer to the CR documentation for how to configure.
Zen Service Management
We’ve redefined the relationship between RPA and the shared user-management component, the Zen Service, to remove the ambiguity over which IBM product is managing the Zen Service instance. Only one Zen Service instance should be installed in the namespace to allow for multiple IBM products to use it as a unified user-management service.
Previously, the operator would attempt to serialise and read the Zen Service resources, if it existed in the cluster, to determine if it was created by the RPA operator or another product. This would lead to problems where the Zen Service could have unexpected attributes which would break the serialisation step. To address this, the new operator takes a different approach by requiring the user to specify if the Zen Service is managed by the current instance or not. This is under the .spec.zen.managed attribute where the expected value is “true” or “false”, where “true” is the default value.
When set to “true”, the RPA instance will deploy a minimal Zen Service CR which is just enough for RPA to deploy. If you would like to manually configure the Zen Service, outside of the default CR created by RPA, this value should be set to “false”. This can be done after the RPA product is deployed, if required.
Setting the value to “false” will configure the RPA instance to not deploy a Zen Service instance, this is intended to streamline integrating RPA with other products and Cloud Paks, like Cloud Pak for Data and Cloud Pak for Business Automation. In these configurations, the RPA instance will expect the other product to be installed first in the namespace, as it will search for a Zen Service instance before it deploys without one.
Migration
The migration from the v1beta1 RPA operator is not seamless due to the complete re-architecture of the operator, as well as the new requirement for both a block and file storage class type to be present in the cluster. We’ve streamlined the migration process by providing a step-by-step guide, as well as deploying a conversion webhook to convert the exiting v1beta1 CR API into the new v1 API. Please refer to the migration guide in the RPA documentation for how to perform this process.