As the digital economy continues to evolve, the volume of data being generated is reaching unprecedented levels. IDC (International Data Corporation) estimates that the global datasphere will grow to 175 zettabytes by 2025. For banks, this surge in data brings both significant challenges and meaningful opportunities. Managing such vast amounts of information is no longer enough. Success now depends on the ability to extract timely, actionable insights. Whether it’s enhancing customer experiences or meeting complex regulatory demands, the effective use of data has become a critical differentiator. IBM Cloud Pak for Data helps banks turn data into a trusted and strategic asset, enabling them to drive innovation, operate with agility, and build long-term trust at scale.
Real-World Challenges
Despite rapid digital transformation, many Indian banks still operate with fragmented legacy systems. Customer data, transaction records, loan applications, and compliance documents are often siloed across disparate platforms. This fragmentation makes it difficult to build a complete view of the customer, personalize services, or identify risks early.
At the same time, regulatory expectations continue to rise. Compliance with frameworks such as KYC, AML, and other region-specific banking regulations demands strict adherence. Fraud detection must be immediate and precise, not reactive. Meanwhile, customers expect fast, seamless, and digital-first banking experiences that leave no room for delays or inefficiencies.
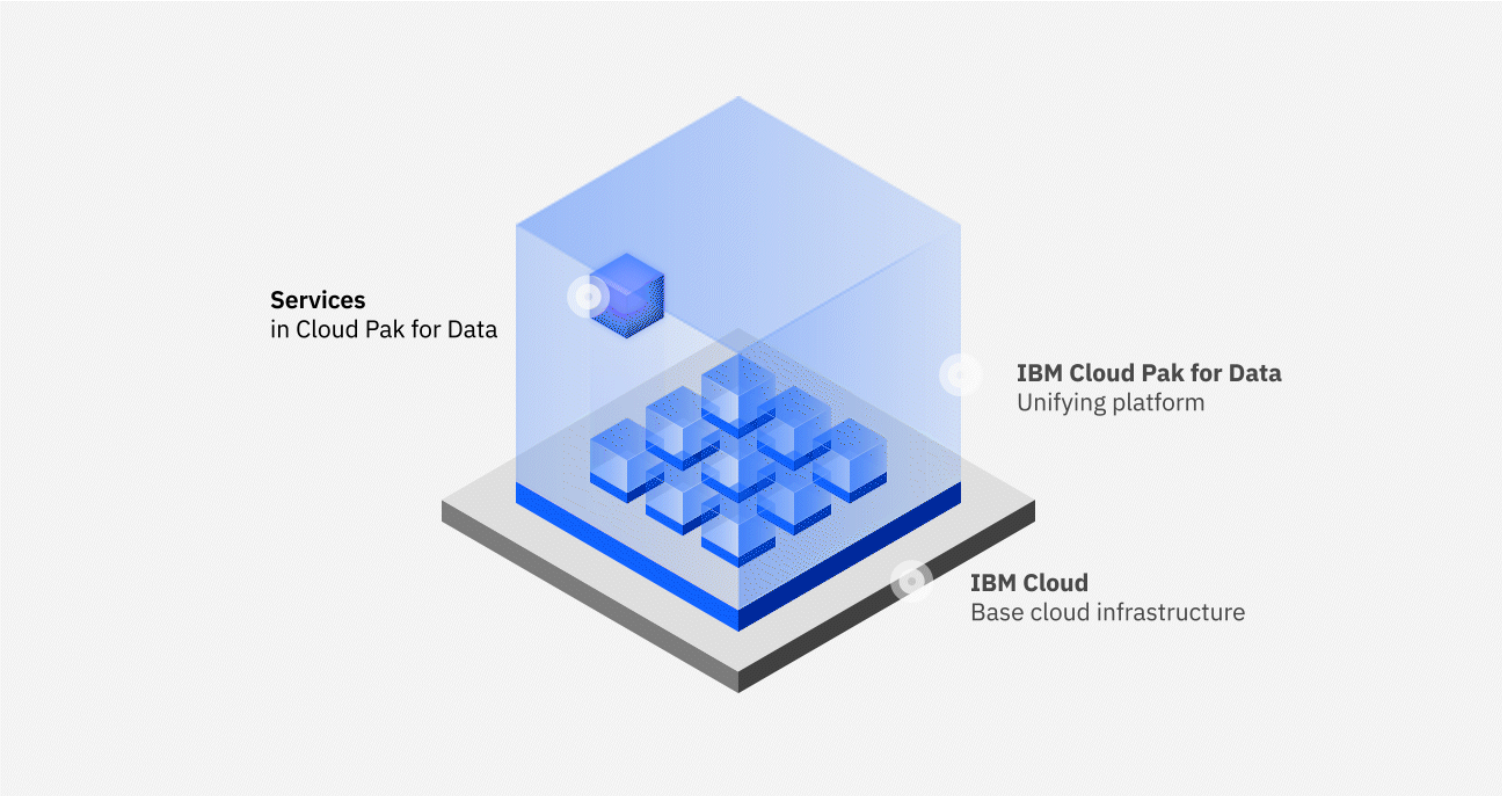
The Smarter Way to Handle Data and AI: IBM Cloud Pak for Data
IBM Cloud Pak for Data is designed to help organizations tackle these challenges. It is a unified data and AI platform that works across on-premises, private cloud, and public cloud environments. This makes it especially suitable for regulated industries like banking.
Here’s how it delivers value in real-world scenarios.
- Bringing Order to Data Chaos
Let’s take the KYC process in Indian banking as an example. While documents like PAN and Aadhaar are stored in centralized systems, other important data such as income details, mobile verification, and credit history may be scattered across internal platforms or third-party services. IBM Cloud Pak for Data helps bring all this information together.
Using Match 360, banks can create a unified and trusted customer profile by linking data from different sources. Data Refinery cleans and prepares the data. Watson Studio identifies suspicious patterns, and Watson Natural Language Understanding automatically verifies document details. Additionally, IBM Knowledge Catalog (IKC) plays a key role by tagging and classifying customer data, ensuring sensitive information is properly identified and governed. Together, these tools make KYC faster, more accurate, and fully compliant.
- Smarter Decisions with AI
Traditionally in banking sector, personal loan approvals were based on credit scores alone, but AI can factor in behavioural data like spending habits and transaction patterns. This allows banks to offer fairer, more personalized approvals, ensuring responsible borrowers aren’t overlooked just because of a lower credit score. With Watson Studio and AutoAI, financial institutions can build AI models that continuously refine lending criteria, reducing bias and improving accuracy without needing manual intervention.
- Real-Time Analytics That Matter
In banking, trust and transparency are critical, especially when AI is involved in decision-making. IBM OpenScale ensures that AI models remain fair, explainable, and compliant over time. It monitors for demographic bias and provides clarity on why decisions are made.
For instance, if a model begins to disproportionately flag transactions from a specific demographic, OpenScale alerts analysts to investigate and adjust the model. This transparency helps banks maintain regulatory compliance, build customer trust, and ensure ethical AI practices.

- Customer Service Insights
Banks often struggle to deliver quick and personalised customer service because data is spread across different systems. Information about account activity, support tickets, and marketing interactions is rarely in one place.
Data Virtualization in IBM Cloud Pak for Data creates a virtual layer that integrates data from multiple sources in real time. This gives customer service teams a holistic view of each customer’s journey. Moreover, IBM Knowledge Catalog (IKC) ensures that sensitive data is masked or redacted, and Data Virtualization respects these policies. This enables secure, compliant, and insightful customer interactions.
- Portability and Flexibility for Hybrid Environments
Modern banks operate in complex IT environments that blend legacy systems with private and public clouds. IBM Cloud Pak for Data, built on Red Hat OpenShift, supports this hybrid model. It allows banks to modernize incrementally by running containerized applications across any cloud environment without vendor lock-in.
This portability ensures that banks can scale efficiently, manage costs, and maintain high performance while meeting stringent security and compliance requirements.
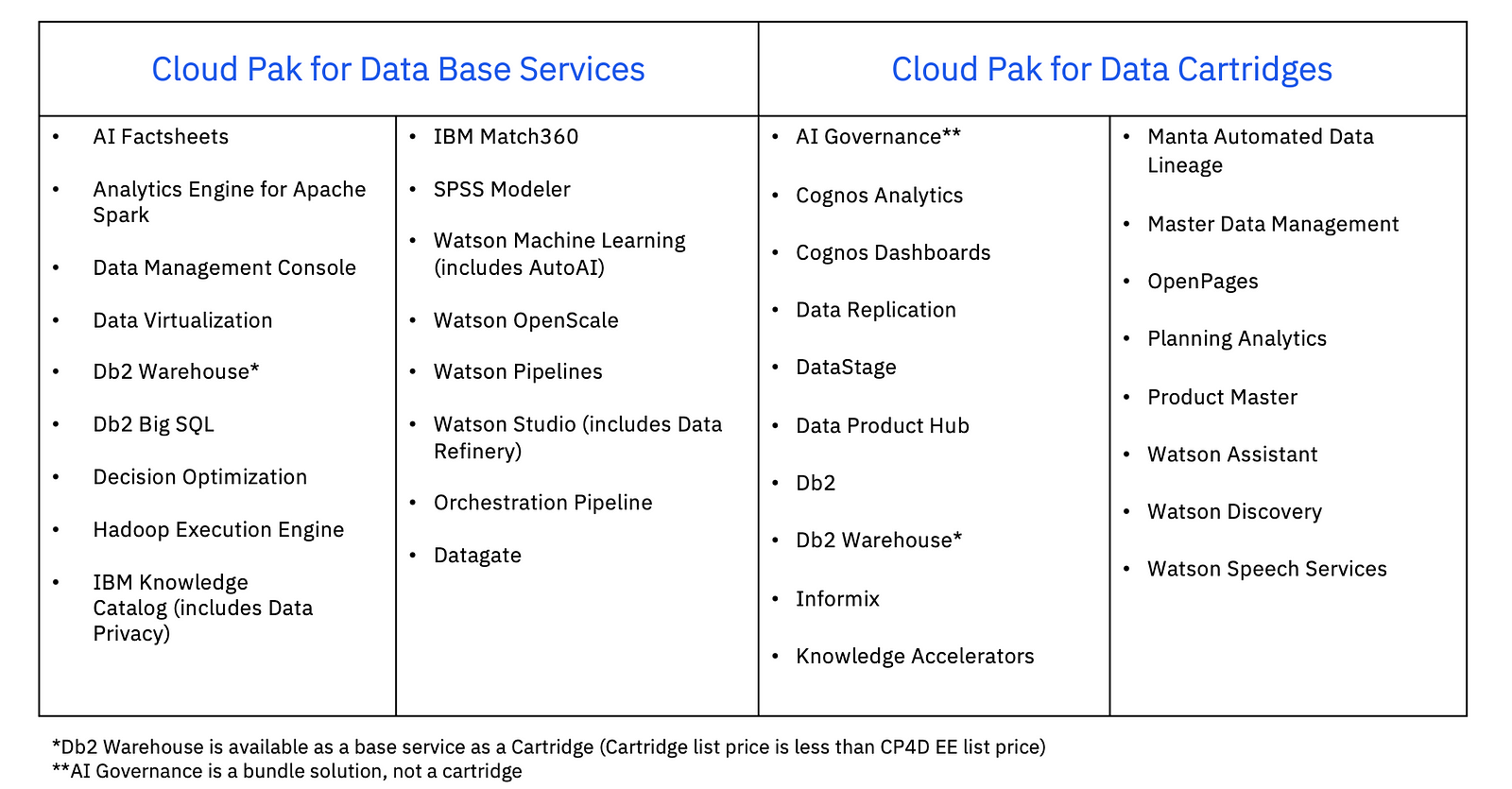
A Platform Built for Flexibility and Scale
The table below highlights the breadth of services available within IBM Cloud Pak for Data. While the platform supports a wide range of use cases, banks can selectively adopt the components that align with their specific goals, whether it’s improving customer insights, streamlining compliance, or scaling AI responsibly.
Final Thoughts
In today’s banking landscape, data can either slow progress or become a powerful driver of innovation. IBM Cloud Pak for Data helps ensure it’s the latter. Whether it’s enabling banks to detect fraud more quickly, streamline compliance, or deliver more personalised customer experiences, the platform empowers financial institutions to trust their data, act on insights, and innovate with confidence. It brings together the tools needed to stay competitive, all while maintaining the highest standards of security, scalability, and efficiency.