Using WML APIs to save, deploy and score models in Cloud Pak for Data 3.5Many data engineers, business analysts and data scientists are developing data models and analyzing data in the containerized enterprise AI and Data platform IBM Cloud Pak for Data. It provides two very important components Watson Studio and Watson Machine Learning for data science projects. Watson Studio is the comprehensive toolkit for data engineers and data scientists to develop models with the popular tools like Jupyter notebook, SPSS modeler, AutoAI, Data Refinery etc. Watson Machine Learning (WML) is the advanced model deployment toolkit with deployment space management and easy model deployment capabilities. Meanwhile, each component provides broad range of RESTful APIs for uses to access and integrate with Cloud Pak for Data.
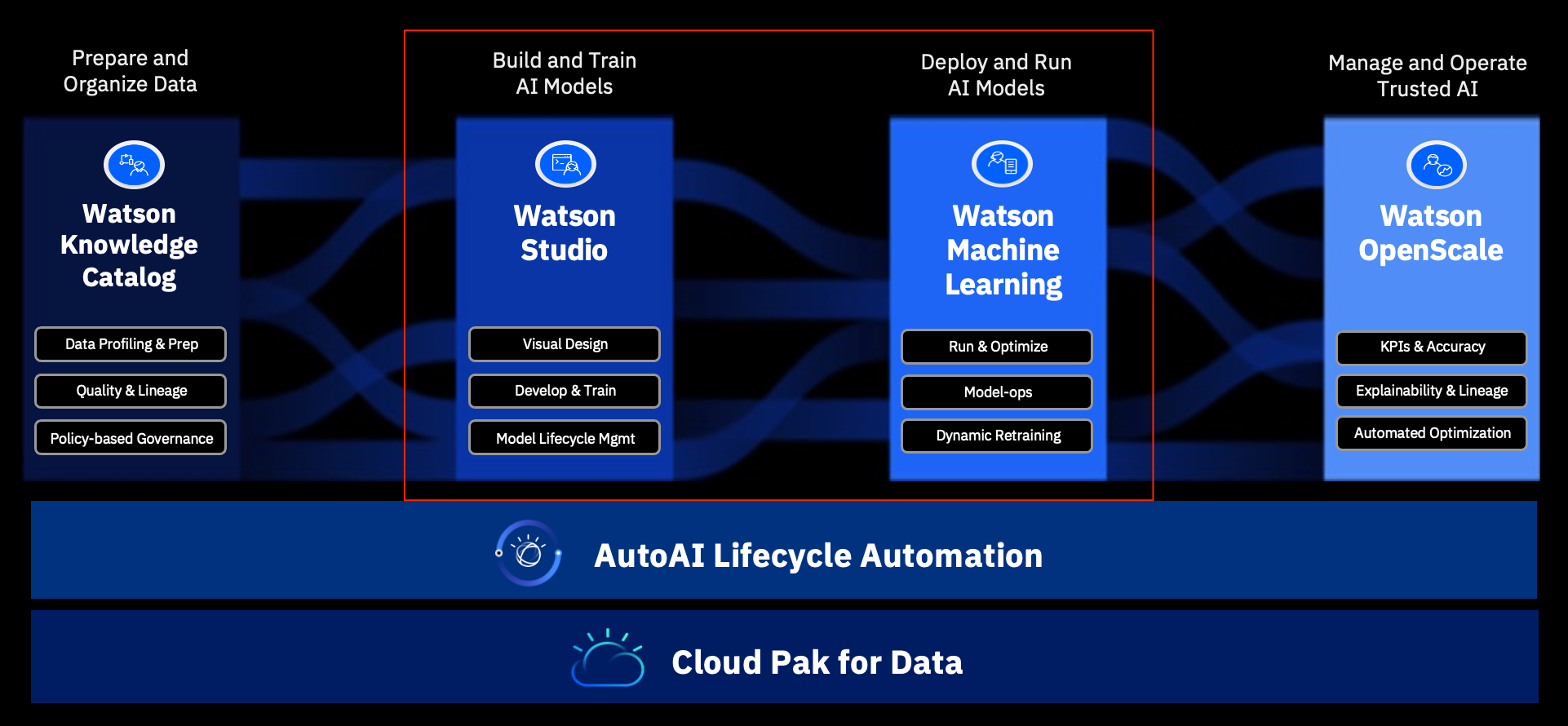 This blog shows the very often used WML APIs of Cloud Pak for Data 3.5 to save model, deploy model and score model in Python notebook. The model used as example is developed in Watson Studio with Scikit-Learn for customer churn prediction classification model, you can get the training procedure from the previous blog "Using Scikit-Learn training a customer churn model in Cloud Pak for Data 3.5" via link https://community.ibm.com/community/user/cloudpakfordata/blogs/harris-yang1/2021/05/26/scikit-learn-churn-model-cpd351. Save model to WML1.1 Initiate WML client
This blog shows the very often used WML APIs of Cloud Pak for Data 3.5 to save model, deploy model and score model in Python notebook. The model used as example is developed in Watson Studio with Scikit-Learn for customer churn prediction classification model, you can get the training procedure from the previous blog "Using Scikit-Learn training a customer churn model in Cloud Pak for Data 3.5" via link https://community.ibm.com/community/user/cloudpakfordata/blogs/harris-yang1/2021/05/26/scikit-learn-churn-model-cpd351. Save model to WML1.1 Initiate WML client
from ibm_watson_machine_learning import APIClient
from project_lib.utils import environment
url = environment.get_common_api_url()
import sys,os,os.path
token = os.environ['USER_ACCESS_TOKEN']
wml_credentials = {
"instance_id": "openshift",
"token": token,
"url": url,
"version": "3.5"
}
client = APIClient(wml_credentials)
1.2 Create deployment space if it does not exist
space_name = 'churn-analysis-space'
space_uid = ''
for space in client.spaces.get_details()['resources']:
if space['entity']['name'] ==space_name:
space_uid=space['metadata']['id']
if space_uid == '':
space_meta_data = {
client.spaces.ConfigurationMetaNames.NAME : space_name
}
stored_space_details = client.spaces.store(space_meta_data)
space_uid = stored_space_details['metadata']['id']
space_uid
1.3 Save model
client.set.default_space(space_uid)
# Model Metadata
software_spec_uid = client.software_specifications.get_uid_by_name('default_py3.7')
meta_props={
client.repository.ModelMetaNames.NAME: "churn-sklearn-model",
client.repository.ModelMetaNames.SOFTWARE_SPEC_UID: software_spec_uid,
client.repository.ModelMetaNames.TYPE: "scikit-learn_0.23"
}
model_artifact = client.repository.store_model(logreg_pipe,
meta_props=meta_props,
training_data=X_train,
training_target=y_train)
model_uid = client.repository.get_model_uid(model_artifact)
print("Model UID = " + model_uid)
2. Deploy model
# deploy the model pipeline
metadata_fields = X_train.columns.tolist()
meta_props = {
client.deployments.ConfigurationMetaNames.NAME: "churn-sklearn-model",
client.deployments.ConfigurationMetaNames.ONLINE: {},
client.deployments.ConfigurationMetaNames.CUSTOM: metadata_fields
}
# deploy the model
deployment_details = client.deployments.create( artifact_uid=model_uid, meta_props=meta_props)
3. Score model with a sample data
deployment_uid=client.deployments.get_uid(deployment_details)
fields = ["AGE", "ACTIVITY", "EDUCATION", "NEGTWEETS" , "INCOME", "SEX", "STATE"]
values = [(30, 1, 1, 12, 30000, 'M', 'TX'), (40, 2, 3, 2, 80000, 'F', 'TX')]
payload_scoring={"input_data": [{"fields": fields,"values": values}]}
payload = {
client.deployments.ScoringMetaNames.INPUT_DATA: [payload_scoring]
}
# Pass the payload to wml client to predict churn for the sample records
scoring_response = client.deployments.score(deployment_uid, payload_scoring)
scoring_response
#CloudPakforDataGroup