IBM Storage Ceph Meets IBM Storage Deep Archive: Simplifying Data Archival with Cost-Effective, Policy-Based Retrieval

Introduction
Data management has become increasingly complex and costly, particularly in the context of long-term archival storage. Organizations frequently grapple with challenges such as escalating storage costs, complexity in managing archival tiers, and high expenses associated with cloud-based solutions due to unpredictable egress fees. IBM addresses these pain points through an integrated solution that combines the robust flexibility of IBM Storage Ceph with the ultra-low-cost archival capabilities of IBM Storage Deep Archive.
Why Combine IBM Storage Ceph and IBM Storage Deep Archive?
IBM Storage Ceph is a leading software-defined storage solution that offers scalable, secure, and resilient object storage, highly compatible with Amazon S3 APIs. It is widely deployed in hybrid cloud environments due to its ability to scale seamlessly from terabytes to petabytes and even exabytes. IBM Storage Ceph excels in environments demanding the right balance between performance and cost-effective storage, high availability with first-class multisite replication, and straightforward lifecycle management through sophisticated policy-driven data handling.
On the other hand, IBM Storage Deep Archive offers unprecedented cost efficiency to on-premises archival storage. Leveraging tape infrastructure behind a familiar S3 Glacier-compatible interface, Deep Archive eliminates traditional hurdles associated with tape storage, such as the need for specialized SAN infrastructure and dedicated tape expertise. IBM Storage Deep Archive significantly lowers costs—up to 85% compared to AWS S3 Glacier Deep Archive and 94% compared to AWS S3 Glacier Flexible Retrieval—while eliminating unpredictable egress fees and operational complexity. Even more importantly, Tape is inherently designed as the ultimate protection against ransomware. Datasets on tape are not executable, tape is off-line even when attached to the server, and all system datasets cannot be “erased” or encrypted with a single command.
The synergy between IBM Storage Ceph and IBM Storage Deep Archive is compelling. Together, these technologies create a seamless, integrated data archival solution, allowing organizations to apply flexible, automated policies for data lifecycle management. Data moves transparently from hot or warm tiers within Ceph directly into Deep Archive's cost-effective cold storage, all managed through standardized S3 APIs and S3 lifecycle rules.
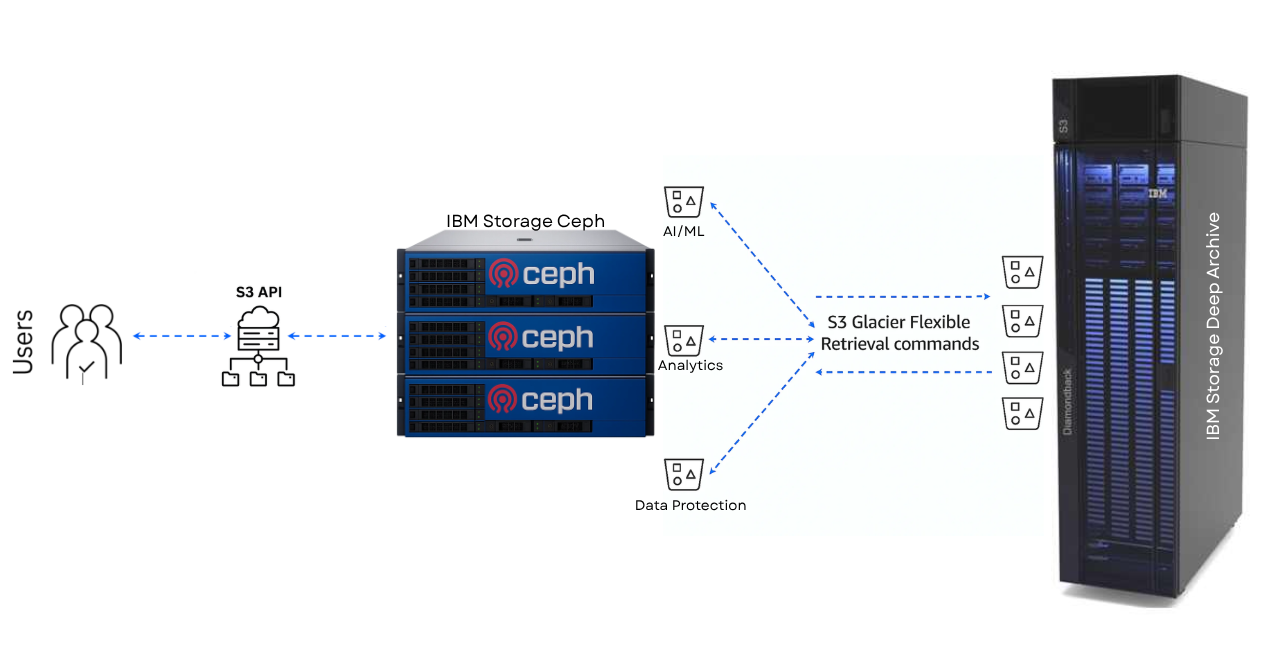
Technical Overview and Integration
IBM Storage Ceph's recent policy-based data archival and retrieval enhancements further streamline its integration with S3 archival storage targets, such as IBM Storage Deep Archive. Ceph now supports policy-based transitions of data to external S3-compatible storage tiers, including those that present Glacier Retrieval classes. This capability enables precise control over data management based on business requirements, compliance standards, or cost considerations. For more information, refer to this blog post series.
IBM Storage Deep Archive uniquely complements Ceph’s capabilities by offering an S3 Glacier-compatible interface without the traditional overhead associated with tape systems. It's a fully managed, plug-and-play deployment that simplifies the integration process, ensuring quick and straightforward adoption by existing IT teams with S3 expertise. Data archived in the Deep Archive can be restored temporarily or permanently, seamlessly and transparently, based entirely on policy-defined parameters.
Recent validation tests confirm this interoperability, demonstrating successful lifecycle transitions from IBM Storage Ceph’s active storage buckets into Deep Archive’s S3 Glacier Flexible Retrieval storage class. Retrieval functionalities, including temporary and permanent restore options and read-through retrievals, operated flawlessly during extensive internal testing. These results underscore the reliability and ease of use inherent in this integrated solution. IBM Storage Ceph allows one destination target bucket per storage class; there is no technical limitation, but we initially validated with 3 million objects per IBM Deep Archive bucket/Storage Class. We have a blog series with all the low-level details on how the policy-based archive is implemented in IBM Storage Ceph.

Real-World Benefits
Organizations adopting the combined IBM Storage Ceph and IBM Storage Deep Archive solution realize immediate and substantial benefits. Firstly, storage costs are dramatically reduced, thanks to Deep Archive’s ultra-low-cost, tape-backed infrastructure. Moreover, organizations can eliminate the unpredictability and burden of egress fees that are typically associated with public cloud archival solutions.
Operational simplicity is another critical advantage. Since IBM Storage Deep Archive utilizes familiar S3 Glacier APIs, IT staff require no specialized knowledge of tape storage. This significantly reduces administrative overhead, allowing for more efficient resource allocation within IT departments. Consequently, organizations gain not only cost savings but also improved operational agility and reduced complexity.
Common use-cases where this integrated approach excels include:
-
Long-term archival for regulatory compliance
-
Cost-effective backup and disaster recovery solutions
-
Data preservation for scientific research and media archives
-
Storage optimization in hybrid-cloud deployments
-
Efficient archival of large-scale analytics data
Configuration Guide: Integrating IBM Storage Ceph RGW with IBM Diamondback (Deep Archive)
This section provides detailed, step-by-step guidance on integrating IBM Diamondback with IBM Storage Ceph’s S3 Object Gateway (RGW) to facilitate automated object lifecycle transitions to tape-backed Deep Archive storage.
Test Environment Overview
The environment used for testing includes:
-
A single Ceph site
-
3 RGW daemons deployed with SSL-enabled frontend (Beast) on port 445
-
An ingress service terminating SSL on port 443
-
Backend connectivity established with the IBM Storage Deep Archive network
-
Target bucket (testbucket2) hosted on the IBM Storage Deep Archive endpoint
Step 1: Configure SSL-Based IBM Storage Ceph RGW and Ingress Services
Sample Object Gateway Cephadm Spec File(rgw.spec):
service_type: rgw
service_id: ssl.vim_445
service_name: rgw.ssl.vim_445
placement:
hosts:
- ceph1
- ceph2
- ceph3
networks:
- 9.x.x.0/23
spec:
generate_cert: true
rgw_exit_timeout_secs: 120
rgw_frontend_port: 445
rgw_frontend_type: beast
rgw_realm: vim-realm
rgw_zone: vim-zone
rgw_zonegroup: vim-zg
ssl: true
Sample Ingress Spec File (ingress.spec):
service_type: ingress
service_id: ssl_gencert.ceph2
service_name: ingress.ssl_gencert.ceph2
placement:
hosts:
- ceph1
spec:
backend_service: rgw.ssl.vim_445
first_virtual_router_id: 50
frontend_port: 443
generate_cert: true
monitor_port: 1969
ssl: true
verify_backend_ssl_cert: true
virtual_ip: 9.x.x.x/23
Apply your RGW and Ingress Service Spec files:
$ cephadm apply -i rgw.spec
$ cephadm apply -i ingress.spec
Create a target bucket testbucket2 on the Diamondback S3 endpoint. This bucket receives objects transitioned from the Ceph Object Gateway (RGW).
Step 2: Configure Ceph RGW for Tiering to Diamondback
Disable SSL Verification (optional): If the CA doesn’t verify SSL certificates for IBM Deep Archive:
$ ceph config set client.rgw.rgw_verify_ssl false
$ ceph orch restart rgw.ssl.vim_445
Configure Deep Archive Tier in Zonegroup: Edit current zonegroup configuration:
$ radosgw-admin zonegroup get --rgw-zonegroup vim-zg
Add the following tier target Storage Class configuration to your zonegroup:
$ radosgw-admin zonegroup placement add --placement-id default-placement --storage-class=ibm-deep --tier-type=cloud-s3-glacier --rgw-zonegroup vim-zg --rgw-realm vim-realm
$ radosgw-admin zonegroup placement modify --placement-id default-placement --storage-class=ibm-deep --tier-type cloud-s3-glacier --tier-config=endpoint=https://diamondback-endpoint.com,access_key=xxx,secret=xxx,retain_head_object=true,target_storage_class=GLACIER,target_path=testbucket2,restore_storage_class=STANDARD,glacier_restore_days=5,glacier_restore_tier_type=Expedited,region=default --rgw-zonegroup vim-zg --rgw-realm vim-realm
Commit your changes:
$ radosgw-admin period update --commit --rgw-realm vim-realm
Step 3: Create Bucket and Lifecycle Policy in Ceph RGW
Here is an example with the s3cmd S3 cli tool as the end user, creating a new bucket:
$ s3cmd mb s3://testibm2
Create and apply a lifecycle policy (lifecycle_ibmdeep.xml):
<LifecycleConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<Rule>
<ID>LC_Rule_3</ID>
<Prefix/>
<Status>Enabled</Status>
<Transition>
<Days>3</Days>
<StorageClass>ibm-deep</StorageClass>
</Transition>
<NoncurrentVersionTransition>
<NoncurrentDays>3</NoncurrentDays>
<StorageClass>ibm-deep</StorageClass>
</NoncurrentVersionTransition>
</Rule>
</LifecycleConfiguration>
Apply the policy:
$ s3cmd setlifecycle lifecycle\_ibmdeep.xml s3://testibm2
Step 4: Upload and Transition an Object
Upload a test object:
$ s3cmd put testfile.txt s3://testibm2/
Verify transition after 3 days as per the LC rule
$ aws s3api head-object --bucket testibm2 --key testfile.txt
Step 5: Restore Objects
Restore an archived object:
$ aws s3api restore-object --bucket testibm2 --key testfile.txt --restore-request {Days=10}
Retrieve the Object once restored from IBM Deep Archive:
$ s3cmd get s3://testibm2/testfile.txt
Conclusion
Integrating IBM Storage Ceph with IBM Storage Deep Archive presents a compelling solution for organizations looking to optimize their data archival strategies. The combination delivers substantial cost efficiency, operational simplicity, air gap resiliency, and policy-driven flexibility. As validated through rigorous internal testing, this integrated approach promises reliability and ease of management, allowing businesses to securely archive vast amounts of data without compromising accessibility or incurring exorbitant costs.