Introduction
Hello everyone! We’re team Code Catalysts - winners from the IBM Z Datathon hosted last October. We’re here to discuss our amazing experience of building an AI/ML solution on enterprise servers - IBM Z systems before, during, and after the datathon.
But first, some background information. Before the datathon, IBM mentors hosted several workshops to familiarise everyone with how popular AI/ML frameworks can be used on IBM Z servers. We were given actual hands-on access to IBM Z systems running Ubuntu Linux and Docker containers in a lab environment of IBM LinuxONE Community Cloud (L1CC). Thanks to the pretty straightforward tutorials, we got our L1CC instance up and running a pre-built docker image with TensorFlow, PyTorch, SciKit Learn, and all our favourite machine learning libraries installed. The tutorials were a good cross-reference but otherwise we were positively surprised that these were the same open frameworks and tools familiar from other labs. This was convenient and amazing at the same time to see the same Python code was running on a powerful IBM Z server with unique architecture - s390x.
The Problem
With that established, let’s get straight into our project on the L1CC cloud: a hate speech detector.
Why make a hate speech detector? The answer is simple. Hate speech is a huge problem today. With more and more people interacting with online platforms, there is more data created every instant than ever before. Amidst all that data, there’s guaranteed to be hurtful, hateful, or otherwise harmful content. Unfortunately, manually going through all that data is impossible even with an army of people. Worse yet, traditional approaches to content moderation fail to capture the nuances of everyday speech, often flagging normal content or overlooking hateful content.
Ok, but how many people care about that? Turns out, way more than you might think. Individual users suffer when they encounter hateful content. It ruins their experience on an online platform, leading to users that either engage less with the platform or leave it altogether. Businesses suffer for that very same reason. Less active users means less revenue for businesses. In other words, hateful content is a problem for users and businesses alike.
Data Science to the Rescue
So what did we do then? We used machine learning to prototype a solution to this problem.
The dataset
Like every good machine learning solution, we started with data. Luckily for us, there were tons of existing datasets out there. We eventually decided on a hate speech dataset on Kaggle because it seemed to have everything we needed. It had human-labelled data — the gold standard when it comes to supervised learning tasks. It had modern-day slang — exactly what we needed for an up-to-date model. Best of all, there were 25 thousand examples in the dataset.
To use the dataset, we applied a bit of preprocessing. Because there was a slight imbalance in our dataset, we weighted labels, weighting normal speech more than hate speech. We also made a custom dataset object to relabel tweets labelled as “offensive” as “hate speech” to make this a binary classification problem.
class CustomDataset(Dataset):
def __init__(self, df):
self.df = df
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
text = row["tweet"]
outputs = np.array([0, 0], dtype=np.float32)
# if it's offensive or hate speech, mark it as flaggable
if int(row["class"]) <= 1:
outputs[0] = 1
else: # else, it's shouldn't be flagged
outputs[1] = 1
return text, outputs
ds = CustomDataset(df)
Custom dataset object that combines “hate speech” and “offensive” tweets into one class
def loss_function(y_pred: torch.Tensor, y_true: torch.Tensor, ce = torch.nn.BCELoss(reduction="none")):
temp = ce(y_pred, y_true).sum(dim=-1)
weights = torch.where(y_pred[:, 1] == 1, 1, .1)
return (temp * weights).mean()
Weighted BCE loss that allows us to combat dataset imbalance
The Language Model
To understand our huge corpus of text, we employed a language model based on transformer architecture: BERT. BERT, which stands for Bidirectional Encoder Representations from Transformers, is a model which quickly became popular for NLP once it was introduced a few years ago. It is a deep learning model with outputs connected to inputs as per the transformer architecture, an architecture especially suited for sequences, to effectively understand human language. Best of all, it’s 100% open source, meaning that using it in our project was as easy as downloading its weights from HuggingFace.
from transformers import AutoModelForSequenceClassification
class HateDetector(torch.nn.Module):
def __init__(self):
super(HateDetector, self).__init__()
self.text_model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2).to(device).train()
self.output_func = torch.nn.Softmax(dim=-1)
def forward(self, tokens: torch.Tensor, token_attention_mask: torch.Tensor):
return self.output_func(self.text_model(tokens, attention_mask=token_attention_mask).logits)
Hate Detector module
So how does our model work? The input to our model is a collection of tokens, each representing a “word.” We then prepend a classification token to these tokens. BERT then processes our input sentence, producing a rich representation of the text. We use that representation to calculate the probability that the given sentence is hate speech.
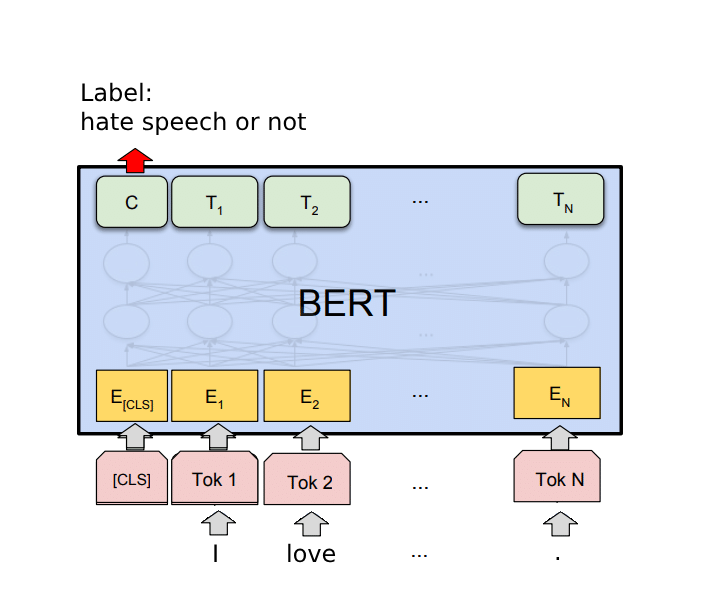
Model diagram. Our model takes sequences of words and outputs a label
Training
Probably the hardest part of an ML engineer’s job is waiting for a model to train. For us, this was definitely true. If we had trained on our local CPU, it would’ve taken forever. Luckily, we had a GPU available, reducing our training time to a couple of minutes.
Deploying to L1CC
Now that we had our trained model, it was time to deploy it. This was IBM Z time to put it to work. Thanks to the open standards supported by IBM Z Enterprise computing system, we were able to take the model that we had trained on our local machine, upload it to our L1CC instance, and watch it run. That’s the best part of the L1CC environment; models can be trained anywhere and deployed on IBM Z and IBM LinuxONE for inference at a scale previously unthinkable.
Now, there was a slight hiccup that we should mention. When we first tried to upload our weights, we found out that the model was outputting nonsense values on our L1CC instance. After much digging, we eventually figured out that the byte order had been swapped. So, we actually had to save our model in big-endian form, which is what the L1CC uses, in order for it to run. After the datathon, our mentors showed us that later versions of PyTorch became aware of endianness and added support for big-endian architectures. We could use a different Docker image with a higher version of PyTorch in order to solve this problem without any byte-order swapping on our side. This was a nice discovery to realise that there is actually a growing support for this platform in open source communities.
Anyway, that’s beside the point. Once our model was on the L1CC instance, we were surprised by how quickly we could perform inference. Unlike our local CPUs, which took seconds to perform inference, the L1CC instance performed inference in under a second! It also had incredibly low latency and immensely large bandwidth — perfect for an enterprise-grade solution that needs to scale to thousands of transactions per second.
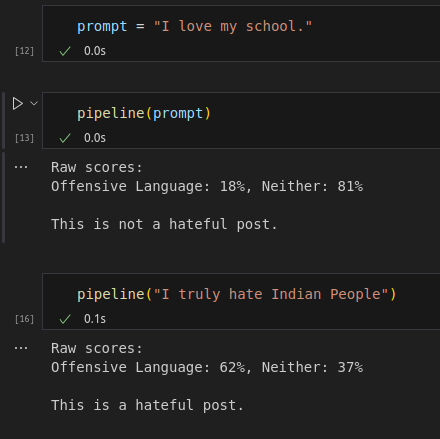
Example model outputs when run in a Jupyter notebook connected to an IBM Z instance
Because of that low latency and high bandwidth, we decided to continue on our project after the datathon, building a REST API around our model. Now, we can say that we have truly utilised the amazing features of the IBM LinuxONE Community Cloud.
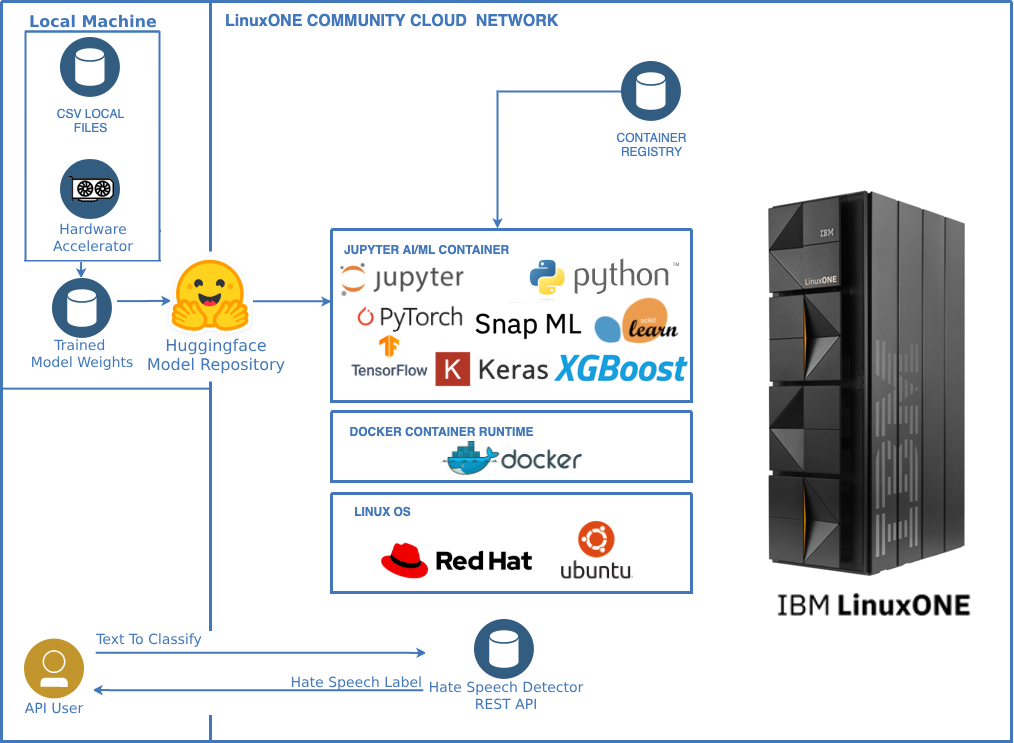
Workflow diagram of our project
Overall, working with IBM Z these past few months has been a great experience. With both top-notch hardware and flexible software, the IBM Z truly is the ultimate enterprise solution that combines qualities of security, scalability, resilience with open standards and popular open source frameworks such as REST APIs, Tensorflow, PyTorch. In the future, we may try extending our solution with features of data pipeline, model serving, database and testing our instance to push it closer to a real-world production deployment. Of course, that’s an experiment for another time. For now, we’d like to send our thanks again to our mentor Dr. Alex Osadchyy for guiding us through this process and to the IBM representatives who initially got us set up on the L1CC cloud.
Until next time,
Eliot Hall and the Team Code Catalysts