It should come as no surprise that business leaders will risk compromising their competitive edge if they do not proactively implement Generative AI (GenAI). The technology is predicted to significantly impact our economy, with Goldman Sachs Research expecting GenAI to raise global GDP by 7% within 10 years. As a result, there is an unprecedented race across organizations to infuse their processes with artificial intelligence (AI): Gartner estimates 80% of enterprises will have deployed or plan to deploy foundation models and adopt GenAI by 2026.
Though, businesses scaling AI face entry barriers, notably data quality issues. Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled data quality challenges. According to IDC, stored data is set to increase by 250% by 2025, with data rapidly propagating on premises and across clouds, applications, and locations with compromised quality. This situation will exacerbate data silos, increase costs, and complicate governance of AI and data workloads.
Traditional approaches to addressing these data management challenges, such as data warehouses, excel in processing structured data but face scalability and cost limitations. Modern data lakes offer an alternative with the ability to house unstructured and semi-structured data, but lack the organizational structure found in a data warehouse, resulting in messy data swamps with poor governance.
The solution: modern data lakehouses
The emerging solution, the data lakehouse, combines the strengths of data warehouses with data lakes while mitigating their drawbacks. With an open and flexible architecture, the data lakehouse runs warehouse workloads on various data types, reducing costs and enhancing efficiency.
There are many modern data lakehouses currently available to customers, one of them being watsonx.data, IBM’s fit for purpose data store, one of three watsonx products that help organizations accelerate and scale AI. Built on an open lakehouse architecture, watsonx.data combines the high performance and usability of a data warehouse with the flexibility and scalability of a data lake to address the challenges of today’s complex data landscape and scale AI.
Foundation of a data lakehouse: the storage layer
One of the key layers in a data lakehouse, and specifically wastonx.data, is the storage layer. In this layer, the structured, unstructured, and semi-structured data is stored in open-source file formats, such as Parquet or Optimized Row Columnar (ORC), to store data at a fraction of the cost compared to traditional block storage. The real benefit of a lakehouse is the system’s ability to accept all data types at an affordable cost.
See the below picture to view the different layers of the watsonx.data architecture. The bottom layer is the storage layer of the lakehouse.
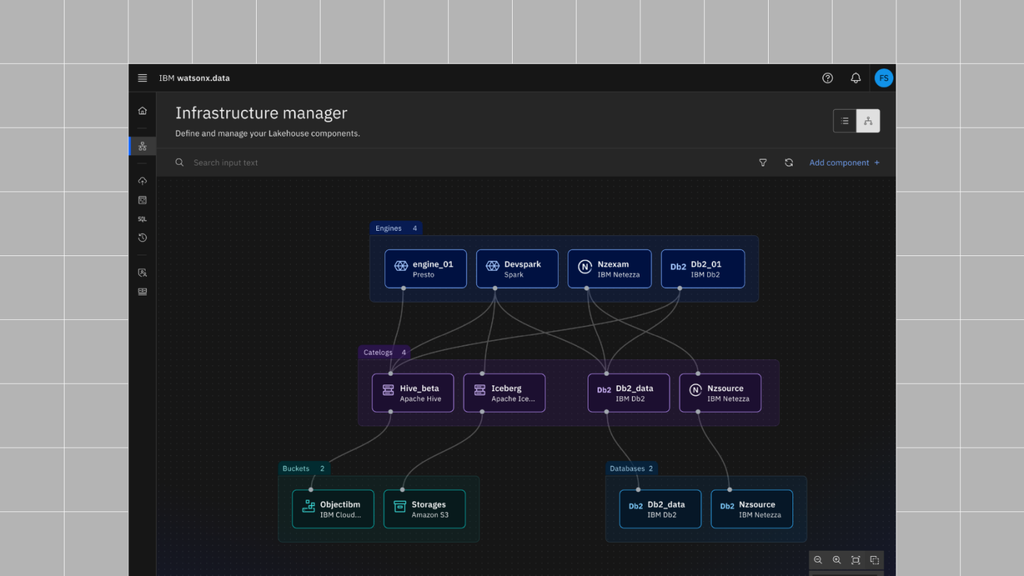
Populating lakehouses with IBM DataStage
To begin leveraging the full functionality set of lakehouses, data must be efficiently migrated and loaded into the storage layer, also know as a data store. Users can accomplish this by utilizing IBM DataStage, the premier data ingestion tool to populate prepared, actionable data into the storage layer of a lakehouse, including watsonx.data. DataStage is an industry-leading data integration solution that is purpose-built for ingesting data from any source - whether that be on-premises or on any cloud. Users can load data directly using 300+ connectors, capitalize on an intuitive low-code/no-code pipeline designer, and ensure their mission-critical workloads contain reliable data all while using DataStage’s built-in parallel engine for scalability and best in class performance. DataStage is built specifically to establish a strong framework for accessible and trusted data so that enterprises can be confident when scaling their AI initiatives.
As a continuation of IBM’s investments towards supporting the modern data stack, users of DataStage can now ingest data into a lakehouse storage layer in Apache Iceberg and Delta Lake table format through the S3 and HDFS connectors. Iceberg and Delta Lake tables are two emerging table formats for integrating with data lakes and efficiently organizing and querying all types of data. Both formats have similar attributes, but Delta Lake is tightly integrated with the Databricks data lake whereas Iceberg is an open-source Apache format known to be portable with a wide array of support for other file formats and data tools. Moreover, as a user, you may wonder why these table formats are so crucial.
Deep dive into Iceberg and Delta Lake table formats
Data lakes are ideal locations for storing large volumes of semi-structured, and unstructured data in native file formats, however these files do not contain the information needed by query engines, creating challenges when managing and querying large scale data storage systems.
Metadata layer
Iceberg and Delta Lake table formats solve this challenge with a layer of metadata that manages collections of file formats, including Apache Parquet, Apache Avro, Apache Orc, and CSV files. Rather than providing proprietary storage and compute layers, the inserted layer of metadata comprises a fine-grain picture illustrating how the underlying storage is organized to ensure correctness and coordination of table data across diverse file formats and constant changes. Additionally, Iceberg tables offer vendor-agnostic functionality like that of traditional SQL tables, allowing multiple engines to simultaneously operate on the same dataset.
Additional table benefits
Iceberg and Delta Lake tables offer several helpful features, such as:
Flexible SQL commands to make it easier to work with structured and unstructured data within data lakes and lakehouses
Schema evolution to unlock schema updates that only affect metadata, leaving data files unchanged
Partition evolution, enabling access to pertinent partitions of data, decreasing read and load times
Time travel and rollback for easy debugging, inspecting changes, and reverting to previous versions
ACID (Atomicity, Consistency, Isolation, and Durability) transactions at scale, enabling concurrency
Faster querying to leverage data compaction and relevant files to enable faster querying speeds
Ultimately, without the manual burden of converting tables from file formats to table formats to populate data lakehouses, including watsonx.data, data engineers can focus on more strategic, high-value work for their organizations.
***
Building an open and trusted data foundation is core to scaling and accelerating AI. DataStage, along with the rest of components of IBM’s Data Fabric architecture, enhance the quality of organizations’ data to produce trustworthy outputs. With newly added support for Iceberg and Delta Lake table formats within DataStage’s S3 and HDFS connectors, data users can optimize their modern data workloads and scale analytics and AI with prepared quality data through seamless integration with data lakehouses.
Learn more:
-
Watch the technical demo video for an in-depth guide on how to leverage DataStage to populate data into Iceberg table format
-
Book a meeting with our sales team
-
Try DataStage for free