Originally posted by: Th. Mühge
In general Storage Area Networks (SAN) and Multipathing Software can cope with permanent errors quite well.
For example if one specific path stops working due to a permanent cable or SFP error, the system will switch over to the alternative redundant path.
In turn the defective path will be taken offline. Now if the system detects later that the offline path is available again, the path will be set online again.
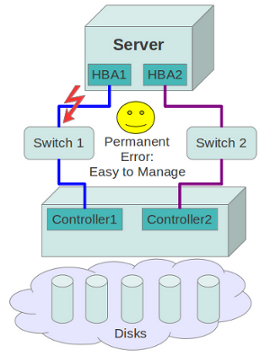
However with increasing complexity of modern SAN infrastructure additional failures might occur that are much more difficult to manage:
Temporary failures that constantly repeat over time.
This might be called a "sick but not dead" condition.
There are multiple possible causes for such a condition:
-
toggling SFP
-
marginal components showing only intermittent error (e.g. bit errors / CRC errors from time time)
-
insufficient sizing of SAN components that are temporarily overdriven
-
Secondary conditions:
-
increase in network traffic leading to congested ports
-
problems on one port effecting other ports due to sharing of CPU
Such intermittent repeating failures can have a severe impact to the overall infrastructure, because the SAN and multipath components might not detect such an error type immediately. This could lead to:
-
performance degradation
-
access loss
IBM's new multipathing software introduces advanced management techniques, that offer a much better management of such
"sick but not dead" failure conditions.
For further details please read the following IBM RedBook article:
http://www.redbooks.ibm.com/abstracts/redp4928.html
For intelligent monitoring of the SAN health the following link might be helpful:
http://www.brocade.com/downloads/documents/data_sheets/product_data_sheets/brocade-fabric-watch-ds.pdf
#DS8000