Originally posted by: TinaLangridge
 IBM Spectrum Conductor with Spark provides data analytics by integrating the Elastic Stack as system services. With this integration, IBM Spectrum Conductor enables you to search, analyze, and visualize Spark application data for efficient monitoring.
IBM Spectrum Conductor with Spark provides data analytics by integrating the Elastic Stack as system services. With this integration, IBM Spectrum Conductor enables you to search, analyze, and visualize Spark application data for efficient monitoring.
This blog highlights enhancements made to the Elastic Stack integration in IBM Spectrum Conductor with Spark 2.2.1 to improve performance, to support scale, and to promote cluster stability within the Elastic Stack.
Upgraded Elastic Stack
IBM Spectrum Conductor with Spark 2.2.1 now integrates the Elastic Stack 5.4.2, which includes:

New dedicated Elasticsearch system services
IBM Spectrum Conductor with Spark 2.2.1 now supports dedicated system services for Elasticsearch:
- Elasticsearch client node: Co-ordinates query/aggregations and takes load off of the data nodes
- Elasticsearch data node: Focuses on indexing and querying requests
- Elasticsearch master node: Focuses on cluster health management and keeping master responsibilities isolated from the load (maximum 1)
The Elasticsearch client and data nodes can be scaled independently to satisfy different workload patterns (heavy indexing vs. heavy querying). The Elasticsearch master node has at most one instance running, removing the prior IBM Spectrum Conductor with Spark 2.2.0 installation requirement for a minimum of two management nodes to establish quorum.
Improved Elastic Stack system services
The Elastic Stack system service monitors have been improved to automatically manage a list of Elasticsearch client, data, and master nodes in the Elasticsearch cluster when the Elastic Stack services scale up or down. The Elastic Stack system service monitors automatically update configurations in the Elastic Stack when the list is modified to ensure index and query requests are forwarded to available hosts only within the Elastic Stack pipeline. The hosts in the list act as gossip routers to re-establish the Elasticsearch cluster and/or to elect a new master host during Elasticsearch master node failover.
The Elastic Stack system services have been improved to automatically stop new indexing requests from Filebeats when the Elasticsearch cluster is unavailable (RED). In addition, Logstash 5.4 has the built in ability to return pressure on inputs to stall data flowing into Logstash when the queue is full. A combination of these two improvements relieve pressure on the Elasticsearch, resulting in greater Elasticsearch cluster stability.
Revised indices to avoid data sparsity
The data collected in IBM Spectrum Conductor with Spark 2.2.1 is now indexed into new indices where all documents in an index have similar characteristics and a similar set of fields.
Index templates are now defined to automatically apply to new indices as they are created. The templates include settings and mappings to ensure that the proper data types are applied to all fields within an index.
Improved pipelines to get data into Elasticsearch
The data loaders and Elastic Stack pipeline in IBM Spectrum Conductor with Spark 2.2.1 were revised to streamline background workloads that extract, transform, and load data into Elasticsearch. The modifications include the removal of ongoing background queries for running drivers and executors in Elasticsearch, the removal of Elasticsearch document upserts, and streamlining data that is indexed into Elasticsearch while keeping the fine grain detail that is required for visualizations.
Enhanced performance and scale
The enhancements made to the Elastic Stack integration have several enhancements in IBM Spectrum Conductor with Spark 2.2.1 including:
- Disk usage: Reduction in the log disk usage by over 70%
- Throughput: Improvements of getting log data through the Elastic Stack and into Elasticsearch
- Search rate: Performance improvements for both task and application intensive workloads
These improvements are observed by comparing performance test results for task intensive and application intensive workloads executed on similar installs of IBM Spectrum Conductor with Spark 2.2.0 and IBM Spectrum Conductor with Spark 2.2.1 (same hardware, network, etc.), and using the same versions of the Elastic Stack (prior to the Elastic Stack upgrade to 5.4.2). This translates to performance improvements resulting directly from the enhancements made to the Elastic Stack integration in IBM Spectrum Conductor with Spark 2.2.1 vs. an Elastic Stack upgrade.
Figure 1 below captures the Elasticsearch indexing performance results for a workload pattern that submits a SparkIO Batch Application over a 4 hour duration across 30 Spark instance groups, for 1 node on an Elasticsearch cluster with 4 nodes. Each Spark instance group submits the SparkIO Batch Application (with 1,000 tasks) every minute, repeated 240 times. A total of 7,200 applications and 7.2 million tasks are submitted across the 4 hour span. In IBM Spectrum Conductor with Spark 2.2.1, the following results are generated:
- A reduction in data indexed into Elasticsearch while keeping the fine grain level of details required for visualizations.
- A reduction in log disk usage that correlates to a reduction in the size of Elasticsearch indices (both primary and replica indices), while keeping the the fine grain level of details required for visualizations.
- A reduction in Elasticsearch documents deleted avoiding unnecessary segment management to clean up deleted documents, allowing the segment management to focus on segment merging resulting from indexing documents.
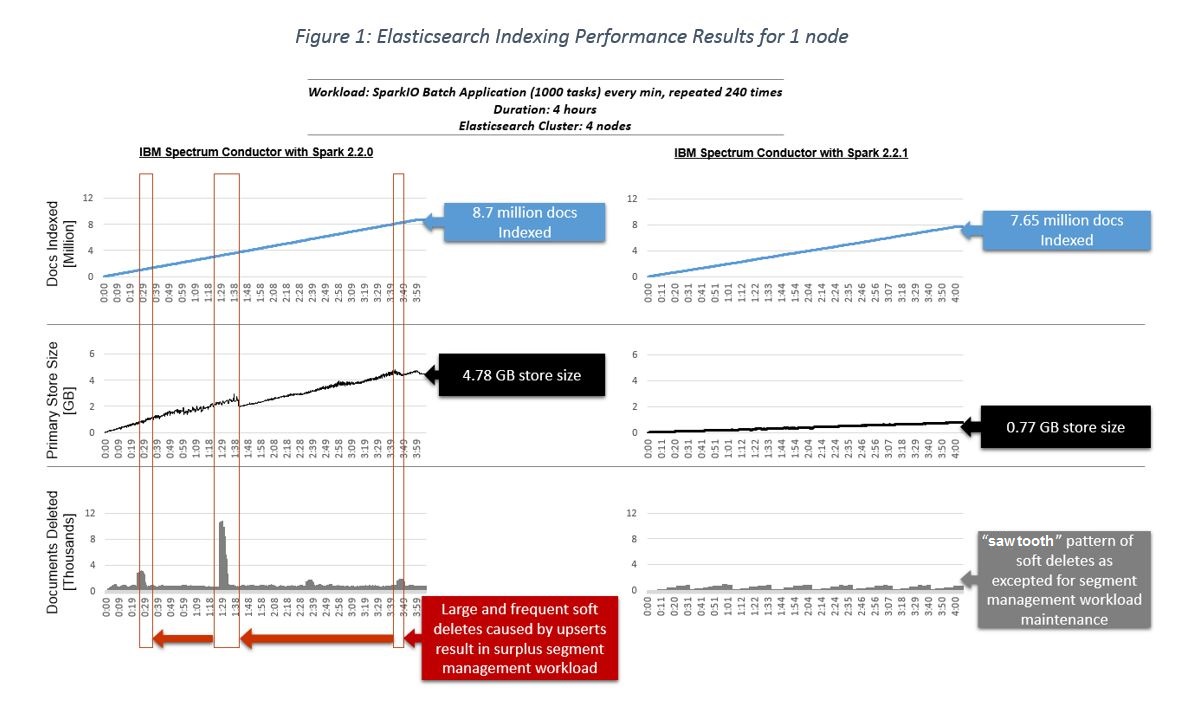
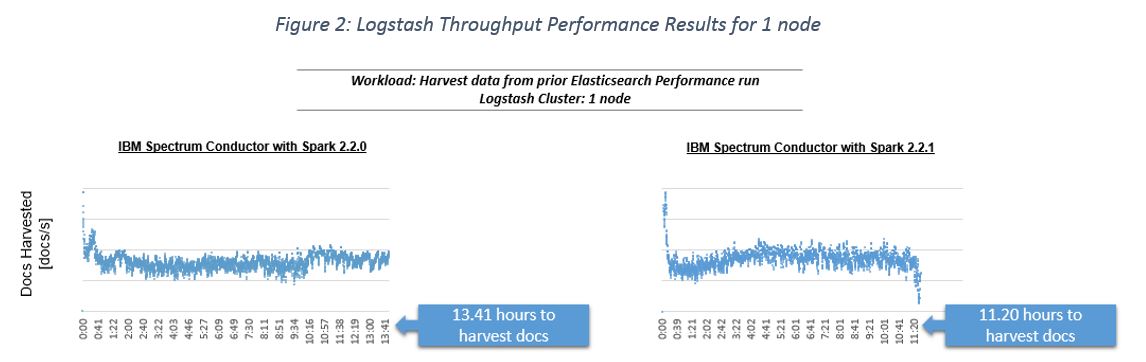
Figure 2 below captures the Logstash throughput performance results to harvest the data that is created from the prior SparkIO workload for the 4 hour duration, for 1 node on a Logstash cluster with 1 node. The Logstash registry is deleted to allow Logstash to re-harvest the data from the beginning as fast as it can. In IBM Spectrum Conductor with Spark 2.2.1, the following results are generated:
- An increase in Logstash throughput resulting in more documents harvested per second by a single Logstash node.
- A reduction in Logstash run time to harvest and tokenize the data to index into Elasticsearch.
If you want to try out IBM Spectrum Conductor with Spark 2.2.1, you can download the evaluation version here! If you have any questions about the Elastic Stack enhancements, or any general inquiries, post them in our forum or join us on Slack!
#SpectrumComputingGroup