Every business has much to accomplish in a short period of time. It causes employees to multitask, and unfortunately that means mistakes have to be made to get tasks completed. Employees end up having to juggle between delighting customers, processing approvals, filling out forms, and reading many documents and emails – to name a few – in order to keep business operations going.
We want to get back to our customers and provide them with a great experience, but we need to extract the information contained in the content we receive each day to be able to do that. This is particularly stressful this year for time-sensitive information that needs to be used to process medical claims or emergency loan applications. Some businesses are simply trying to keep basic daily operations running so that employees can actively focus on problem-solving.
The IBM Datacap team has been learning about how our customers have been adapting to the changing circumstances mentioned above, and more, so that we could deliver Datacap 9.1.8 to remedy your pain points.
Overall: An Improved User Experience
With this release of Datacap, we focused on intelligent recognition. We learned that you not only need higher recognition accuracy with machine print and handwriting, but also need to glean more extensive results (more complex information, less reading). We delivered OCR improvements, as well as integrations with IBM’s Automation Document Processing and Watson Knowledge Studio, wrapping them all up in an easy upgrade process from Datacap 9.1.7 to 9.1.8.
We also consolidated our add-ons into a more simplified licensing structure, because we want to keep you headache-free while you’re implementing the new upgrades we’ve made.
Improve All of Your Handwriting Use Cases – Reading handwriting isn’t easy. There tends to be lots of squinting and head-tilting involved, and this difficulty extends into having software do that reading and extraction for you. We updated our recognition engines to improve the quality of Datacap’s handwriting extraction. If you work in an industry with specific terminology, you can add vocabulary files of common field inputs that you’re looking for. If you’re still worried about an error occurring, you can validate the written information on the document you’re processing against a database. For instance, you could validate a zip code against a postal database to ensure that an inventory item is being shipped correctly.
Leverage the power of Automation Document Processing: IBM’s new Automation Document Processing brings deep-learning based extraction and classification to your Datacap applications. Imagine a system that you can teach to recognize fields. That system can apply that knowledge to all the documents it encounters, regardless of whether it has worked with that document before. For example, once the system has been trained to know, “Invoice #,” it can recognize that on invoices, purchase orders, packing lists, etc. The system will also know that, “Invoice #,” is the same as, “Invoice No.,” or, “Inv. #.” A system like this that is truly intelligent brings unprecedented efficiencies and scale. To make it easier to expand your current use cases, we’ve added a new Automation Document Processing action library and an out-of-the-box Application Template.

Use Datacap for documents with a wide range of formats, like contracts, correspondence, or loan / mortgage agreements: We wanted to make it easier to extract information from documents that aren’t consistently formatted – without needing to configure zones or lookup areas. What if the information you needed wasn’t in the same place from one document to the next? Our new integration with IBM Watson Knowledge Studio empowers you to bring Natural Language Processing into your Datacap applications, so you don’t need to worry about zones. Pre-built extractors are available in the Datacap Action Library, and you can also build, customize, and export your own through the Watson Knowledge Studio web-based design tool.

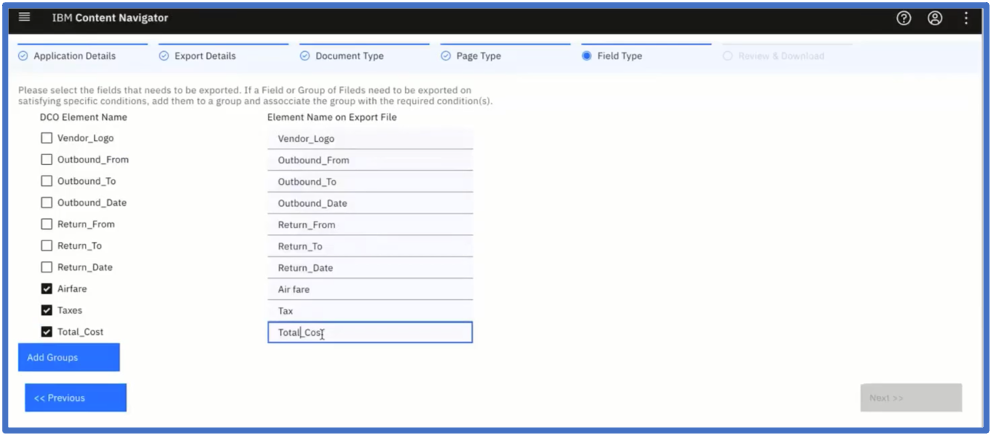
You can worry less about creating complex functions in Datacap to export your data: Smart Export, available as open source on GitHub, will walk you through the export configuration process step by step. This is ideal for extracted data that needs to be updated in an external application like SAP or Salesforce. It’s as simple as defining which information you want to extract, and in what format.
As you continue adapting your business to different types of documents, forms, and scenarios, we are continuing to make Datacap better. From integrating with the latest intelligent recognition technology to ensuring that you have less to think about during the upgrade process, we’re excited to see you leverage Datacap 9.1.8.