Extracting data from a unstructured document especially when it comes without any keys is a real challenge in any of the capturing systems. This problem can be addressed using IBM Datacap Intelligent Extractor solution. Indexes feature available within this solution allows us to capture data from the documents irrespective of its location. Indexes are used to help validate data and retrieve value from data file.
Example1: Lets take Vendor Name field as an example. In many of the document types like Commercial Invoices, Packing List etc., Vendor details in most of the cases will be either on the header or footer part of the page. We will not have a key associated for that in-order to extract it based on the annotations. Extracting VendorName based on its pure location is an another challenge as its position may vary. This problem can be solved by configuring Indexes in IBM Datacap accelerator annotator.xml file. Below example shows how to configure indexes to extract Vendor Name using Vendor VAT.
annotator.xml configuration:Indexes are defined in the indexes element and referred by entity in the <entities> element in annotator.xml configuration file.

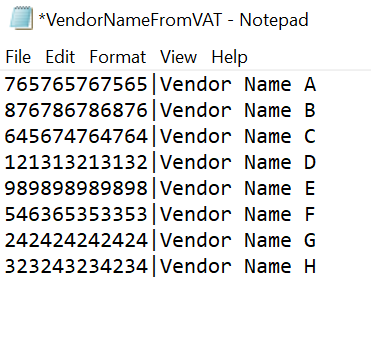
 Index file:
Index file:
Each line in the file represents one Vendor data. First column represents the Vendor VAT and 2nd column is its corresponding Vendor Name. Both the columns has to be separated by pipe symbol.
 How it Works:
How it Works:
Text on the incoming document will be compared with the index file. When incoming document finds a match with specific Vendor VAT entry, its corresponding Vendor Name will be populated as the extraction output for VendorName field.
Example2: Lets take Country field as an another example. If the invoice sample contains Country and the downstream system is expecting Country code, in that case, instead of using the database lookups, we can straight away use the index file to configure the Country and its country codes.
annotator.xml configuration:Indexes are defined in the indexes element and referred by entity in the <entities> element in annotator.xml configuration file.

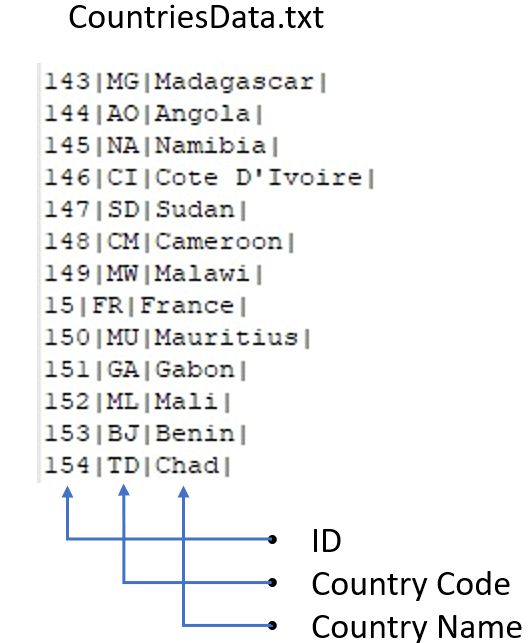
 Index file:
Index file:
Each line in the file represents one Country data.
How it Works:
Text on the incoming document will be compared with the index file. When incoming document finds a match with specific Country entry, its corresponding Country Code will be populated as the extraction output.