Process Mining is the discipline that allows you to gain visibility on the way business and operational processes are conducted, starting from real-life data produced during process execution. These data generally reside in logs and databases – in most situations, you will need to extract and cleanse the information that’s relevant so that Process Mining tools can ingest it and analyze it.
Why process mining?
There are various motivations behind Process Mining, including:
- Process discovery – in many cases, organizations don’t quite understand exactly how certain processes are carried out. Process Mining allows you to reconstruct and visualize those process flows.
- Validation and compliance – since Process Mining works from real-life data, you can evaluate whether processes are being executed according to organizational guidelines or regulations.
- Process optimization – Process Mining can help you identify areas of rework or process steps that can be streamlined, automated, or even removed.
One of the recent acquisitions of IBM involved the company MyInvenio, which operates in the area of Process Mining. The capabilities offered by MyInvenio are now offered as part of the IBM Cloud Paks and are called IBM Process Mining.
Here we show you how you can combine IBM Process Mining and Business Automation Workflow (BAW) to gain visibility and insights on business processes. We also demonstrate how IBM Process Mining can compare the results of its analysis against a process model defined in BlueworksLive, which – in this scenario – represents the business analysts’ view of how the process should be executed.
Our process mining scenario
The diagram that follows illustrates how we set up our scenario:
As shown in the diagram, we deployed two different Openshift (OCP) clusters:
- The first cluster was used to deploy Cloud Pak for Business Automation (CP4BA). We deployed Business Automation Workflow and Business Automation Insights, following the steps required to create a “demo” deployment.
- The second cluster was used to deploy IBM Process Mining. The installation is straightforward. IBM Process Mining is part of the IBM Automation Foundation component that is common to several IBM Cloud Paks. You can find the steps to install IBM Process mining here.
Note: it is not necessary to have a separate cluster for IBM Process Mining – we could have co-located it alongside CP4BA on a single cluster.
The diagram above shows how BAW populates an ElasticSearch database with events, generated during process execution. Those events are then used by BAI to visualize dashboards and metrics about the processes. We are going to make use of those same events to provide input to IBM Process Mining – the events contain all the information that is required by IBM Process Mining.
The diagram shows also that we intend to export a process model from IBM BlueWorkslive and feed that into IBM Process Mining. By doing so, as we mentioned, we enable IBM Process Mining to compare the structure and behavior of the process derived from the real-life events with the model crafted by business analysts – and highlight overlaps or discrepancies.
The business process used in the scenario
We used the sample business process (the Hiring Sample) that comes with the demo deployment of BAW to create data for IBM Process Mining.
The Hiring Sample is accessible as you log in to the CP4BA dashboard as shown below:
After you click on the tile, you can open the process definition in the Process Designer. The process definition is called Standard HR Open New Position, and it is shown in the diagram below.
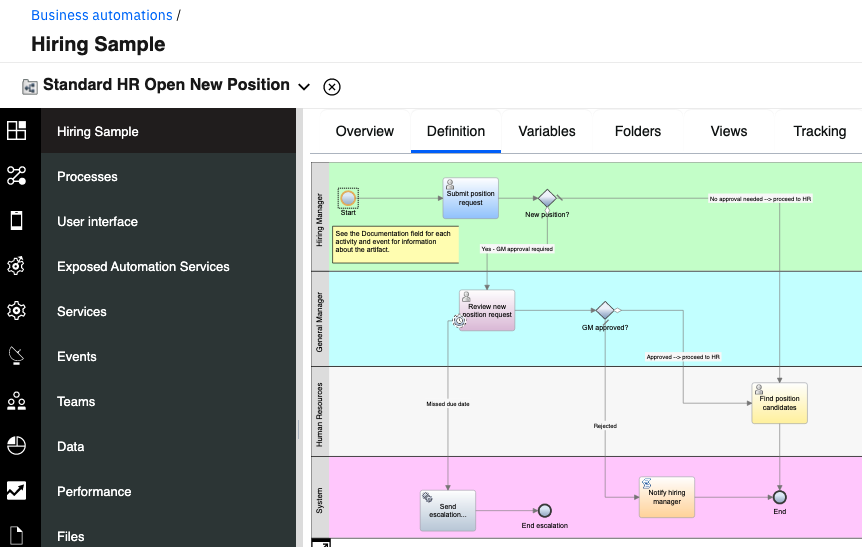
The process is simple:
- A hiring manager creates a requisition for a position in the company
- The requisition – if it is for a brand-new position – goes to the General Manager for approval. If the approval doesn’t occur within a certain timeframe, the process sends an escalation notification.
- The General Manager can reject or approve. In case of rejection, the hiring manager is notified. In case of approval, HR will receive the task of filling the position with candidates.
We drove a few instances of the process to completion and used the BAI dashboard to verify that events had been generated for the various process instances, as shown below.
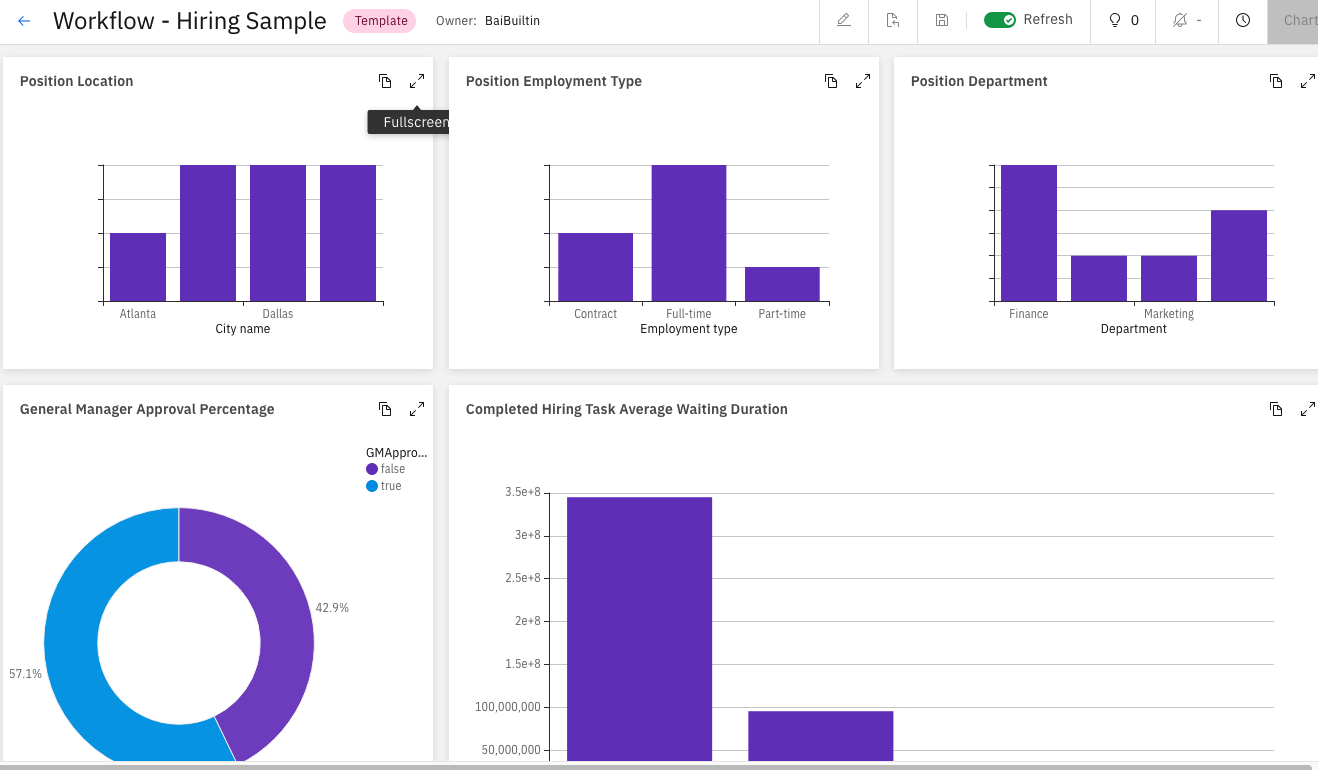
Providing input to IBM Process Mining
Now that we have a number of process instances available for mining, we need to extract the relevant information so that it can be fed into the IBM Process Mining analysis engine.
IBM Process Mining requires you to provide data about the process flow, containing at least these pieces of information:
- A process id – information that uniquely identifies a specific instance of a process. In our case, we can use the process instance id that is generated by BAW.
- An activity id – something that identifies what type of activity was performed during the process execution. We can use the name of the individual tasks.
- The activity start time - this is provided also in the BAW events.
Optionally, IBM Process Mining can consume these additional fields and provide additional insights:
- Activity end time. This is available in the BAW events.
- Role – the actor that performed the activity. This corresponds to the participant who claimed a BAW task.
- The resource associated with the activity – we are not going to provide this information in this scenario.
In addition, IBM Process Mining can use up to 100 “custom fields” of different types (numeric, date, string, …) which can be populated from business data. We are not going to show that here – however, that capability provides a powerful way to correlate process behavior with business information.
This information needs to be supplied to IBM Process Mining as either a CSV file or in an XES format. Since we are extracting the information from an ElasticSearch database, which stores JSON documents, it’s natural for us to convert JSON to CSV and provide the CSV data to IBM Process Mining. Let’s see how.
- First, you need to gain access to the ElasticSearch database that is used by BAW and BAI. In the CP4BA demo deployment, this information is readily available in the ConfigMap called icp4adeploy-cp4ba-access-info located in the namespace where the Cloud Pak is installed:
Elasticsearch URL: https://iaf-system-es-cp4ba.apps.cp4ba-invenio.cp.fyre.ibm.com
Elasticsearch Username: icp4ba
Elasticsearch Password: <password>
- With that information, you can query the indices that are available on ElasticSearch:
curl -k -u icp4ba:<password> https://iaf-system-es-cp4ba.apps.cp4ba-invenio.cp.fyre.ibm.com/_cat/indices
- The output will look like:

- We have highlighted the index that contains the information about completed business processes. Let’s extract the content of that index into a file called completed.json:
curl -k -u icp4ba:<password> https://iaf-system-es-cp4ba.apps.cp4ba-invenio.cp.fyre.ibm.com/icp4ba-bai-process-summaries-completed-idx-ibm-bai-2021.08.13-000001/_search\?pretty&size=10000 > completed.json
- Notice that we set the result set size to a max of 10,000 documents – you may need to change the syntax or use pagination if you have a larger data set in ElasticSearch. Inspecting the output, you notice that it contains all the data elements we need. We are going map performerId to the Role, the name of the task to the activity id, the processInstanceId to the Process id, the startTime to the Start time, and the completedTime to the End time:

- Let’s now narrow down the output to include just the information we need. This can be done easily with jq:
cat completed.json |jq '[.hits.hits[]._source | select(.type!="process")| {"processId": .processInstanceId, "activityId": .name, "startTime": .startTime, "endTime": .completedTime, "role": .performerName}]' > miningdata.json
- Notice how we filtered out some of the entries (those of type equal to process). Those entries are created when a process instance starts and are not related directly to any activity in the process itself. The result is an array of JSON data elements that looks as shown below:

- We can now convert that JSON array into a CSV, using another jq command:
cat miningdata.json| jq -r '(map(keys) | add | unique) as $cols | map(. as $row | $cols | map($row[.])) as $rows | $cols, $rows[] | @csv'|sed 's/"//g' > miningdata.csv
We now have the miningdata.csv file that we can import into IBM Process Mining.
Importing the data into IBM Process Mining
Let’s now log in to IBM Process Mining and import the data we just obtained.
- On the second cluster, access the Cloud Pak dashboard. To do so, you need to hit the cpd route located in the namespace where you installed IBM Process Mining. The user is admin and the password can be retrieved by running the following command against the cluster itself:
oc -n ibm-common-services get secret platform-auth-idp-credentials -o jsonpath='{.data.admin_password}' | base64 -d && echo
- Once you are logged in to the dashboard, click the “hamburger” icon on the top left corner, and then click Analyze > Process mining:

- This will bring you to the IBM Process Mining Processes page. If this is the first time you use the tool, you shouldn’t have any processes yet. Click Create Process to create one:

- Give the process a name and select or create a new organization – then click Create process:

- You should now see the process listed on the main page, and a tile created for it. Click on the tile to open it. You’ll be directed to the Datasource page:

- This is where you can import the data we obtained in the previous section. Under Upload your data source, click Select datasource file and pick the CSV file that was generated. Don’t forget to also click Upload once you’ve made the pick. The data gets uploaded and it will appear under Map relevant data columns:

- Let’s now map the columns. To do so, you click on each column header, and then on the corresponding item at the top. For example, click activityId and then Activity to make the association. Once you’ve mapped all the available columns, your page should look as follows:

Viewing the process mining results
At this point, you can already visualize your process and look at various stats.
- Click the Visualize your process button on the right, and you will be displayed the process graph:

- The graph shows the state transitions (the thicker the arrow, the more frequent the transition) and provides a “heat map” of the various activities (darker boxes represent more common activities). There is a plethora of statistics and other information that you can derive – we encourage you to read the user guide to find out more.
- Let’s now compare “reality” (i.e. the process as it was discovered from the events generated during its execution) with “theory” (i.e. the process as it was modeled by the business analyst). We created a process model in BlueworksLive. You could also use IBM Process Mining to model and simulate your processes, using its BPA capabilities. In BlueworksLive, we have the process model depicted in the following diagram:
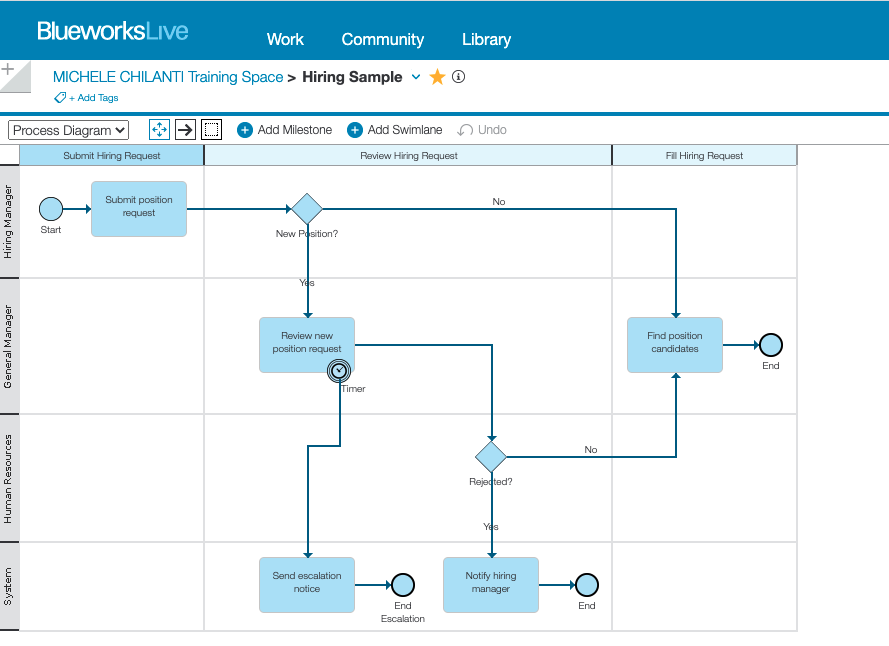
- The model matches faithfully what you saw in BAW. Export the process, as shown below:

- Choose to export the BPMN version of the process. You will download a zip file, which you should expand. Now, back in IBM Process Mining, switch to the Datasource tab again. This time, click Select reference model file:

- Navigate to the directory where you unzipped the process model and then to the subdirectory named “Hiring Sample - <id>” (where the id is a random hex string). Select the Hiring Sample.bpmn file within it. Don’t forget to click Upload at the end.
- Once you imported the model, click Visualize your process again, and then click the “eye” icon on the right hand side:

- The resulting page shows the level of overlap between what happened in reality and the model as defined by the process analyst:

- Notice that the imported model (“Reference model”) has introduced a couple of activities that aren’t present in the detected model (one is the “End” activity – which can be ignored, the other one is the “Timer” that causes the escalation to go off). The two non-conformant cases are – in reality – cases where the escalation occurred. Since the Timer activity is fictitious (it only exists in the reference model), those process instances seem to deviate from the reference model. The remaining 6 instances are in perfect conformance – as expected, since the reference model overlaps perfectly with the execution model.
Here we only show 8 total cases (process instances) – in a real-life situation, you may be dealing with thousands of those. Therefore IBM Process Mining provides the ability to filter and analyze the process instances, so that you can focus on those that interest you. This is done through the Process filter as shown in the screen shot below:
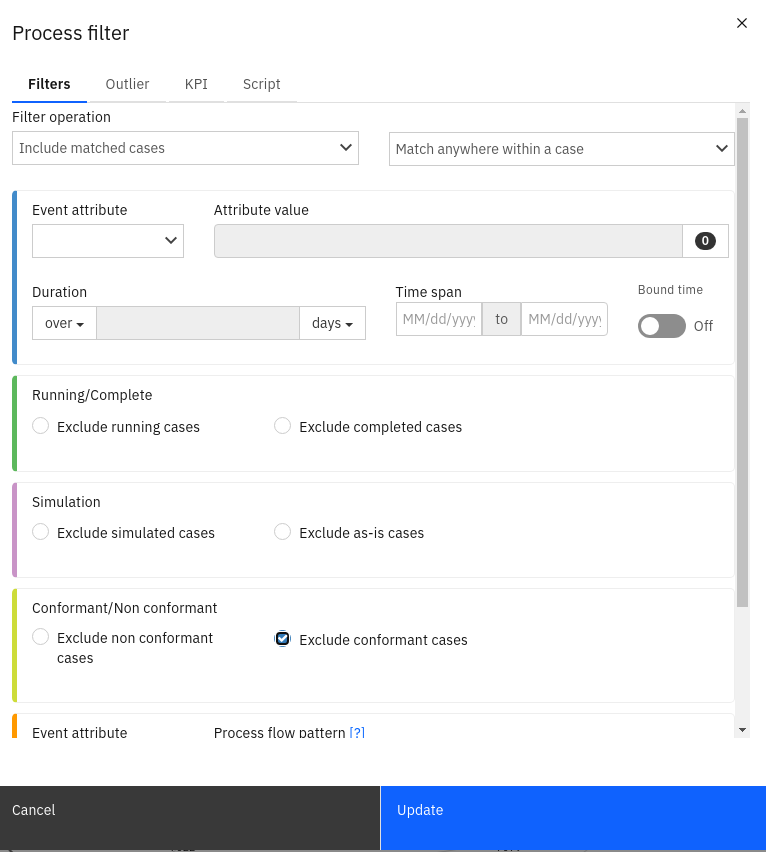
It goes without saying that these results may need some interpretation (as in the case of the non-conformant cases detected above), depending on the quality of the data fed into the tool and of the reference model.
Summary
Hopefully you now understand how you can collect and manipulate data produced by applications (in this case, a BAW business process) and feed it into IBM Process Mining to derive insights into your business processes. It must be stressed that BAW processes are just one of the potentially endless sources of process and task information that can be fed into IBM Process Mining. As long as you can identify and extract the key pieces of information required by IBM Process Mining in your application logs or data repositories (whether they pertain to cloud-native apps, ERPs, legacy applications, and so on), IBM Process Mining allows you to visualize, discover, and inspect how processes are conducted in your enterprise.
#processmining
#myInvenio