IBM Process Miningのデータ・ストリームを使ってSalesforceのデータを取り込んでみる
IBM Process Miningのデータ・ストリームの詳細については、下記の記事を参照してください。
IBM Process Miningのデータ・ストリームによるIBM Event Streams(Kafka)との連携
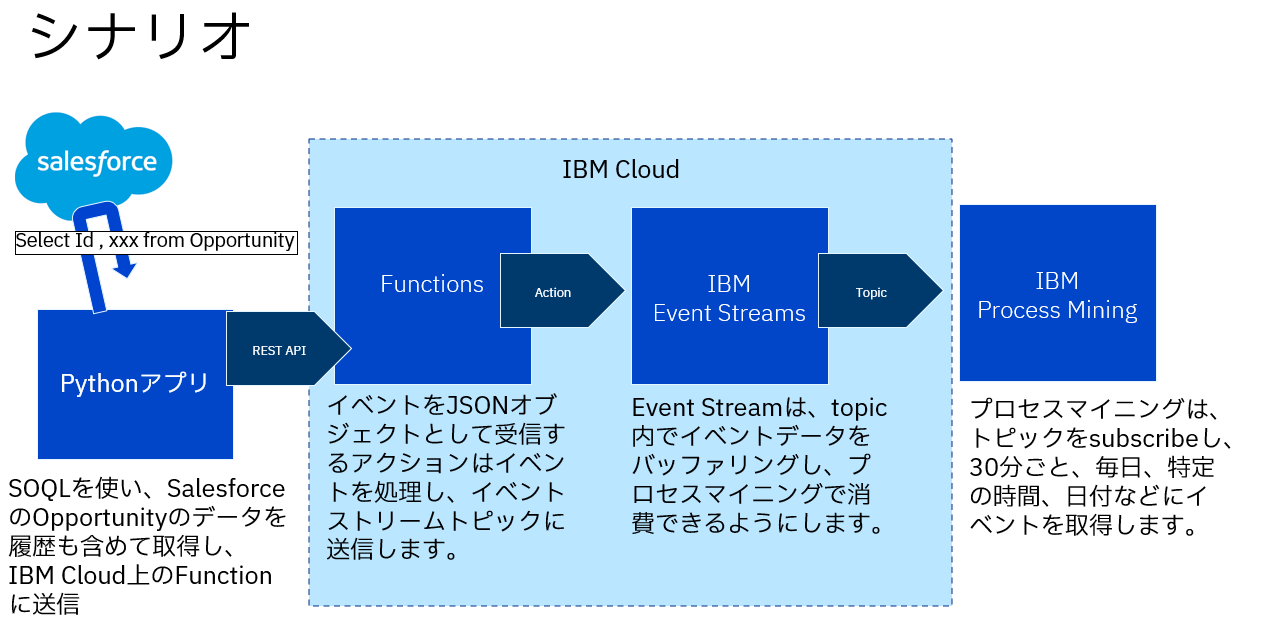
下記の図のように、Pythonのアプリケーションから、SalesforceのREST APIを呼び出し、SOQLを使って、Opportunityに関する情報を取得します。
取得した結果は、IBM Cloud上のFunctionsを呼び出して、IBM Event StreamsにメッセージをPublishします。
IBM Process Miningは、データ・ストリーム機能を使って、IBM Event StreamsのTopicから、Salesforceより取得したOpportunityに関するデータを自動的に取得します。
準備するもの
- Salesforceの接続アプリケーションを作成して、Consumer Key,Consumer Secretを作成
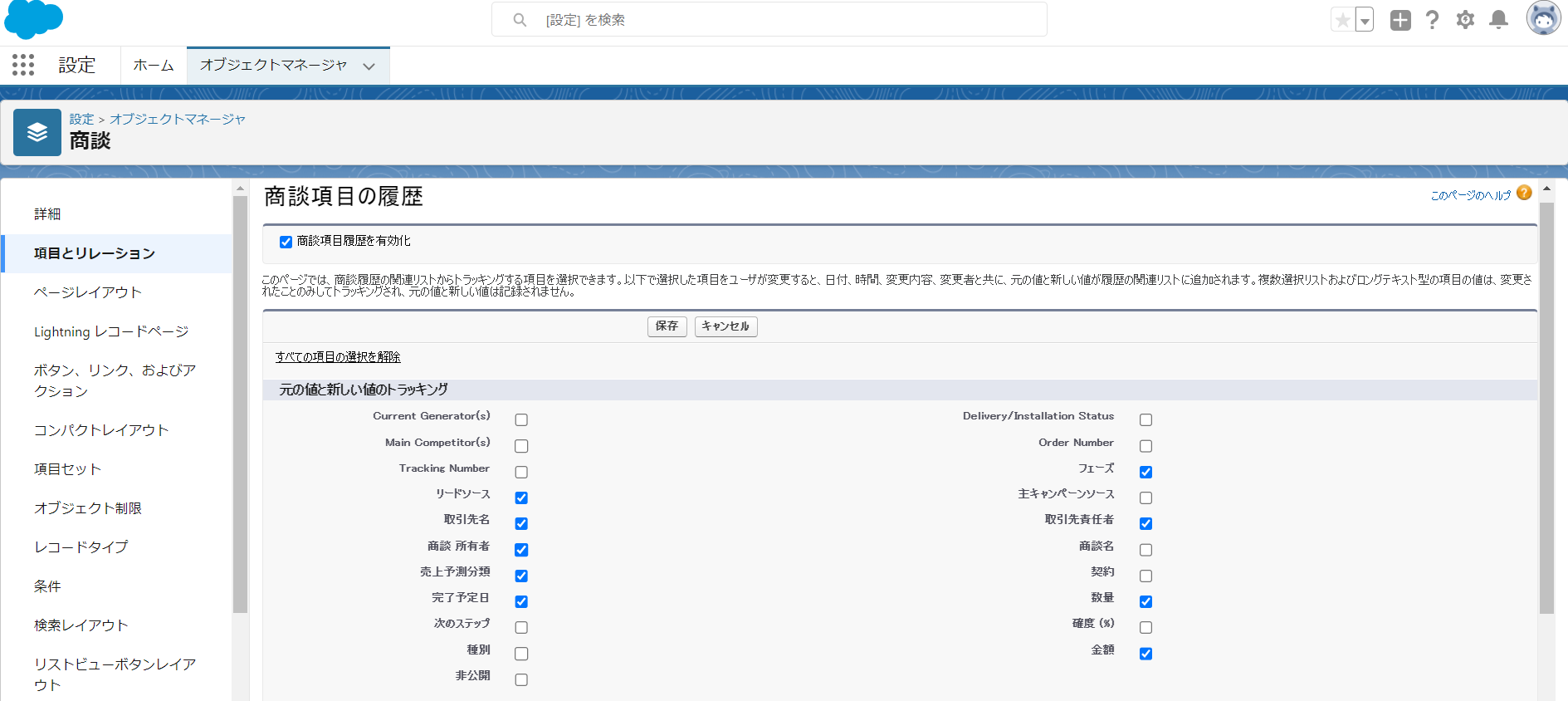
- SalesforceのOpportunityに対する変更履歴を追跡できるように、商談項目履歴を有効化し、取得する項目にチェックを入れる
- IBM Cloud上にIBM Event Streamのインスタンスを構成してTopicを作成しておく
- IBM Cloud上にFunctionsのアクションを定義し、IBM Event StreamsにデータをPublishするPythonコードを定義する
- Pythonアプリケーションを作成して、Salesforceを呼び出し、取得したデータをFunctionsに送信するコードを定義する
- IBM Process Miningのプロジェクトにデータ・ストリームの定義を行う
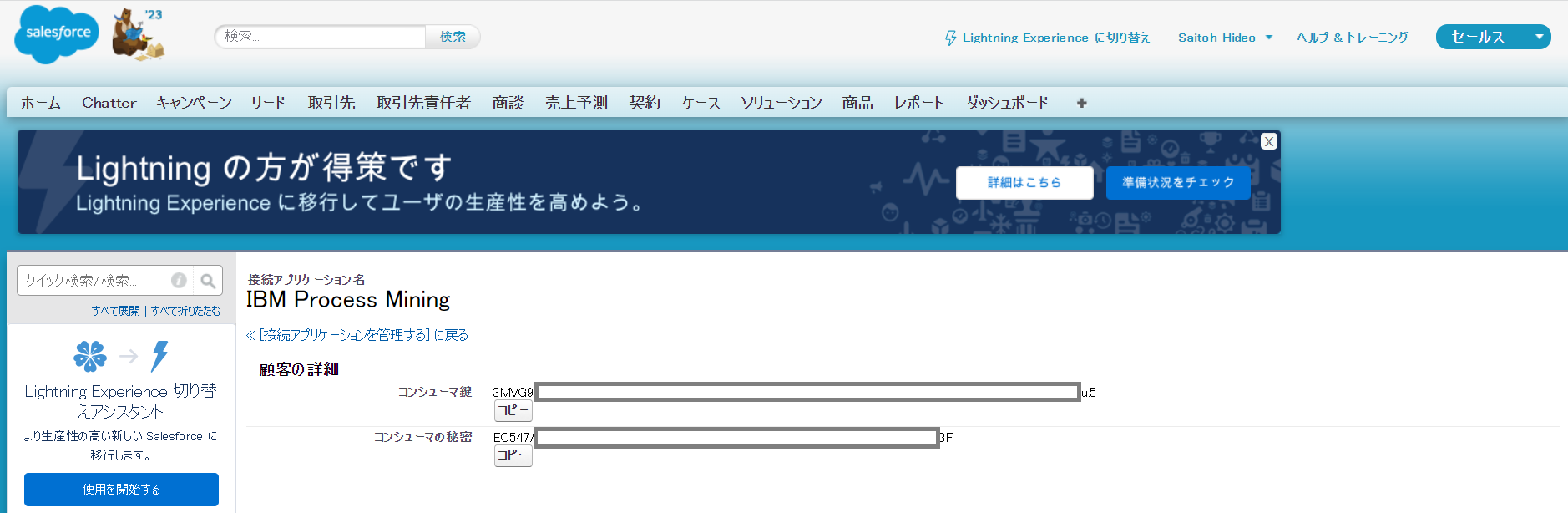
Salesforceの接続アプリケーションを作成して、Consumer Key,Consumer Secretを作成
IBM Process Miningという名前で、接続アプリケーションを作成して、Consumer KeyとConsumer Secretを作成しておく
SalesforceのOpportunityに対する変更履歴を追跡できるように、商談項目履歴を有効化し、取得する項目にチェックを入れる
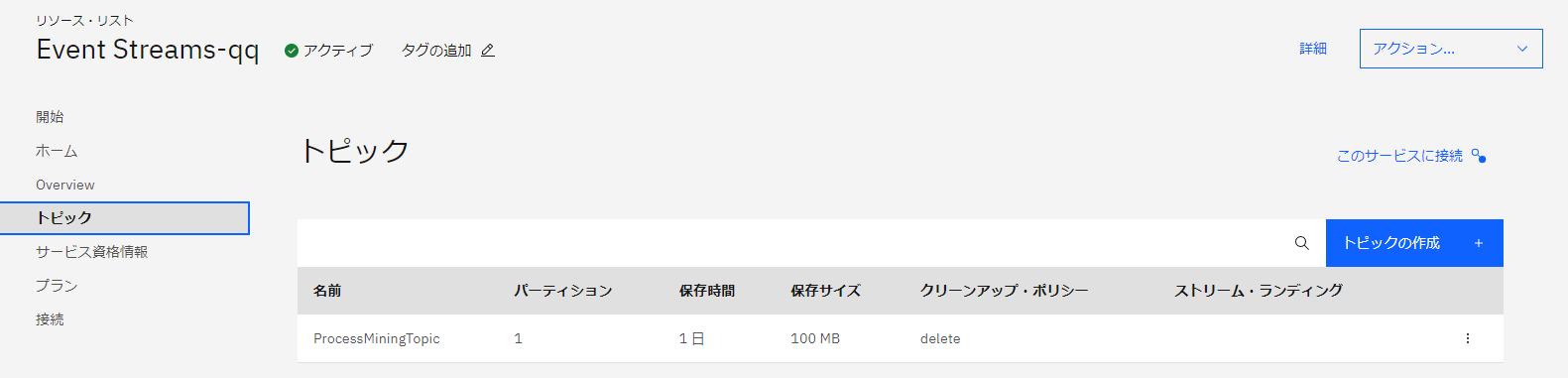
IBM Event Streamsのトピック
IBM Event Streamsに”ProcessMiningTopic”というトピックを作成します。
Functionsの設定
アクションを作成(SFDCという名前のアクション)し、Pythonで、IBM Event StreamsのトピックにメッセージをPublishするコードを記述します。
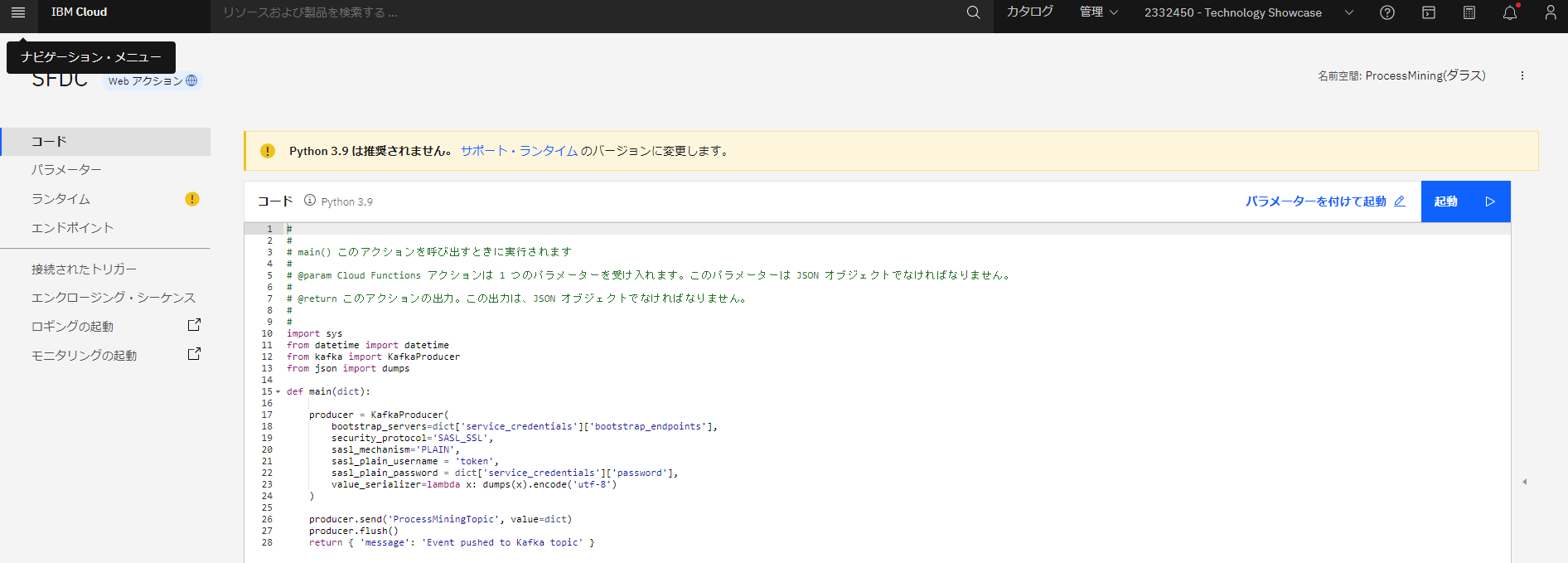
Pythonアプリケーションを作成して、Salesforceを呼び出し、取得したデータをFunctionsに送信するコードを定義する
import requests
import json
from datetime import date
def main():
# reading data from accelerator config
consumerKey = 'consumerKey'
secret = 'consumerSecret'
username = 'username'
password = 'password'
if consumerKey=='' or secret =='' or username =='' or password =='':
raise ProcessAppException('configuration not valid')
# login to salesforce
loginParams = {'client_id': consumerKey,'client_secret': secret, 'grant_type': 'password','username':username, 'password':password}
req = requests.PreparedRequest()
req.prepare_url('https://login.salesforce.com/services/oauth2/token', loginParams)
loginResponse = requests.post(req.url)
if loginResponse.status_code != 200 :
raise ProcessAppException('cannot log to salesforce account')
data = loginResponse.json()
accessToken = data.get('access_token')
instanceUrl = data.get('instance_url')
events = []
importOpportunityCreation(accessToken, instanceUrl, events)
importOpportunityChange(accessToken, instanceUrl, events)
print(json.dumps(events, indent=2))
def runSOQLQuery(query, accessToken, instanceUrl, nextRecordsUrl=None):
req = requests.PreparedRequest()
if nextRecordsUrl != None:
req.prepare_url(instanceUrl+nextRecordsUrl, {} )
else:
req.prepare_url(instanceUrl+'/services/data/v57.0/query/', {'q' : query})
queryResponse = requests.get(req.url, headers={'Authorization': 'Bearer ' + accessToken})
if queryResponse.status_code != 200 :
raise Exception('cannot perform SOQL query to salesforce account')
return queryResponse.json()
def formatDate(date):
return date[0: date.find('.')].replace('T', ' ')
def importOpportunityCreation(accessToken, instanceUrl, events, nextRecordsUrl=None):
req = requests.PreparedRequest()
req.prepare_url('https://us-south.functions.appdomain.cloud/api/v1/web/f5dbe13c-b378-4080-a177-c545ff8a0ba3/default/SFDC', {})
queryResults = runSOQLQuery('Select Id, Amount, StageName, CreatedBy.Name, CreatedDate from Opportunity', accessToken, instanceUrl, nextRecordsUrl)
records = queryResults.get('records')
for record in records:
dictobj = dict()
resource = record.get('CreatedBy').get('Name')
createDate = formatDate(record.get('CreatedDate'))
amount = record.get('Amount')
dictobj["opportunityId"] = record.get('Id')
dictobj["activity"] = "Create Opportunity"
dictobj["startTime"] = createDate
dictobj["resource"] = resource
dictobj["opportunityAmount"] = '0' if 'null' == amount else amount
dictobj["opportunityStage"] = record.get('StageName')
events.append([dictobj])
requests.post(req.url, json.dumps(dictobj),headers={'Content-Type':'application/json'})
if queryResults.get('nextRecordsUrl') != None :
importOpportunityCreation(accessToken, instanceUrl, events , queryResults.get('nextRecordsUrl'))
def importOpportunityChange(accessToken, instanceUrl, events, nextRecordsUrl=None):
req = requests.PreparedRequest()
req.prepare_url('https://us-south.functions.appdomain.cloud/api/v1/web/f5dbe13c-b378-4080-a177-c545ff8a0ba3/default/SFDC',{})
queryResults = runSOQLQuery('Select OpportunityId, CreatedBy.Name, CreatedDate, Field, NewValue, OldValue from OpportunityFieldHistory', accessToken, instanceUrl, nextRecordsUrl)
records = queryResults.get('records')
#print(json.dumps(records, indent=2))
for record in records:
dictobj = dict()
resource = record.get('CreatedBy').get('Name')
opportunityId = record.get('OpportunityId')
createDate = formatDate(record.get('CreatedDate'))
field = record.get('Field')
dictobj["opportunityId"] = opportunityId
dictobj["startTime"] = createDate
dictobj["resource"] = resource
dictobj["opportunityAmount"] = 0
dictobj["opportunityStage"] = ""
if field == "StageName":
activity = "Set Opportunity to " + record.get('NewValue')
dictobj["activity"] = activity
events.append([ dictobj ])
elif field == "Owner":
activity = "Change opportunity Owner"
dictobj["activity"] = activity
events.append([ dictobj ])
elif field == "AccountId":
activity = "Change opportunity Account"
dictobj["activity"] = activity
events.append([ dictobj ])
elif field == "Amount":
activity = "Change opportunity Amount"
dictobj["activity"] = activity
events.append([ dictobj ])
requests.post(req.url, json.dumps(dictobj),headers={'Content-Type':'application/json'})
if queryResults.get('nextRecordsUrl') != None :
importOpportunityChange(accessToken, instanceUrl, events, queryResults.get('nextRecordsUrl'))
if __name__ == "__main__":
main()
IBM Process Miningのプロジェクトにデータ・ストリームの定義を行う
データ・ストリームの定義を行うプロジェクト(既存のもの)を開き、管理のタブのデータストリームを開きます。
データ・ストリームの追加で、データ・ストリームの定義を行います。
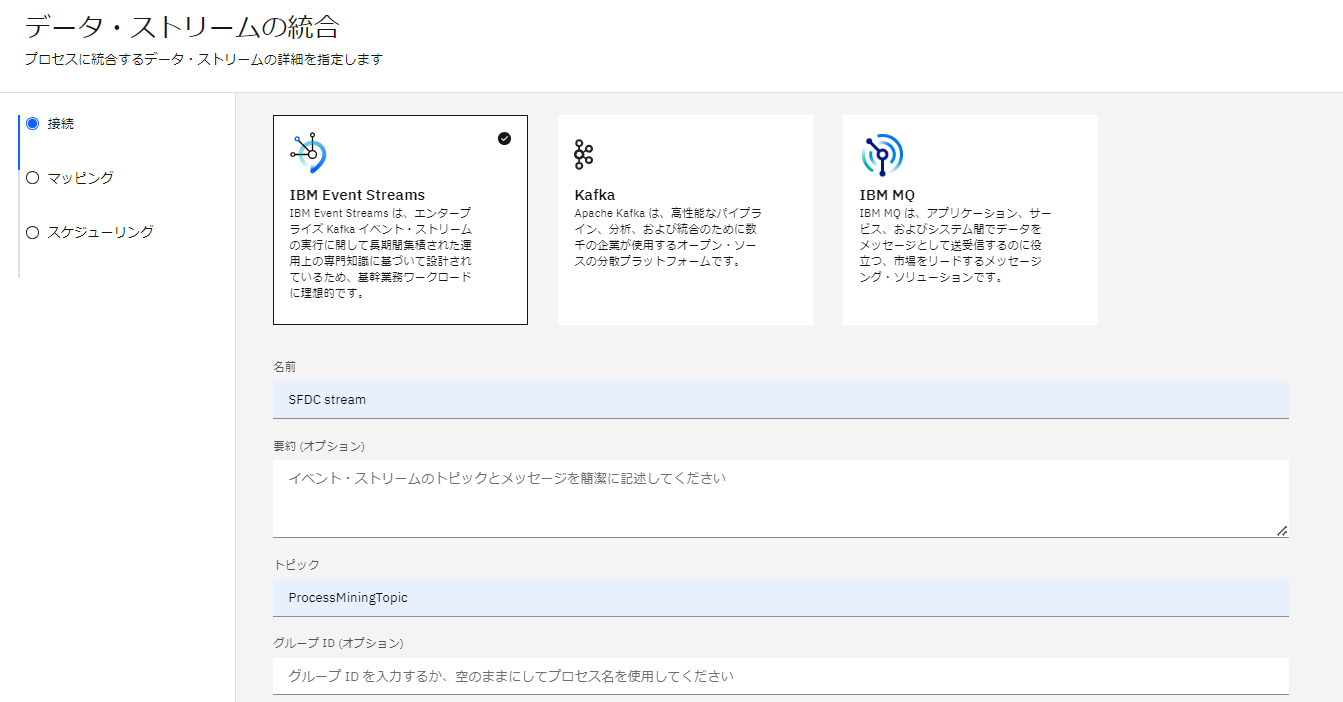
名前:SFDC Stream
トピック:ProcessMiningTopic
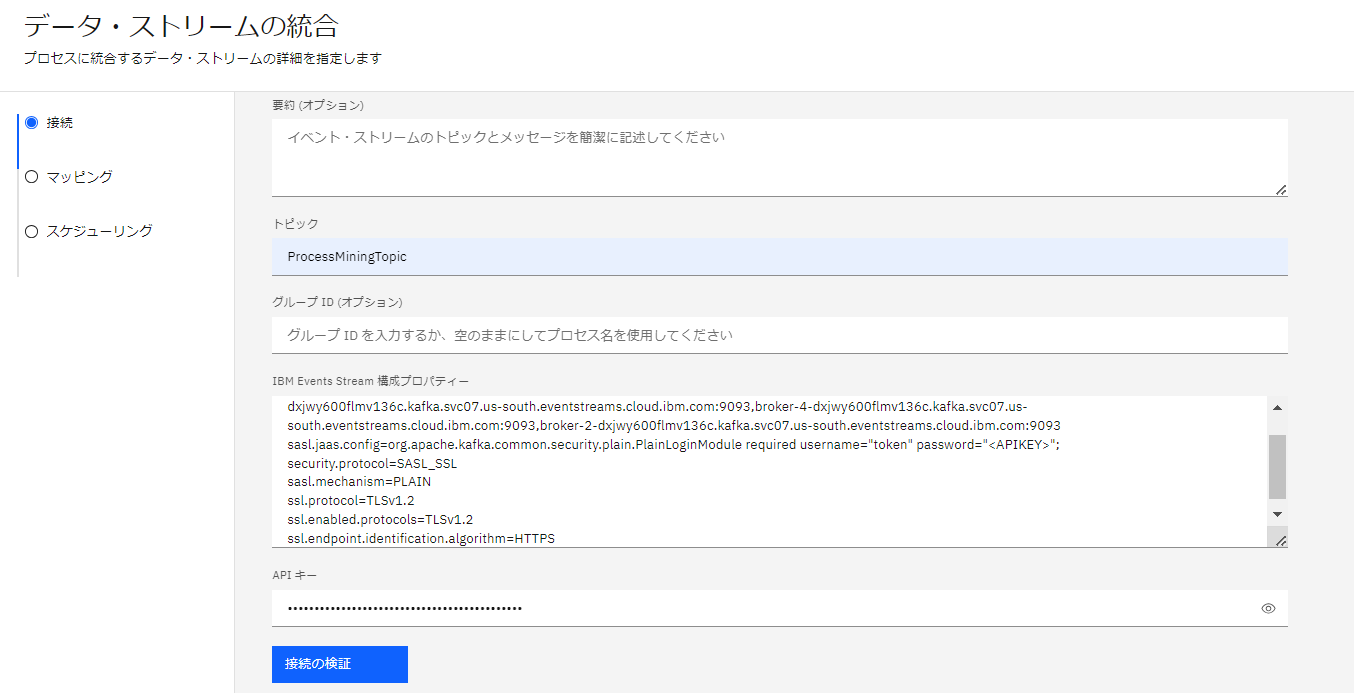
Event Streamsの構成プロパティは、IBM Event Streamsのサンプル構成プロパティよりコピーしたものを設定します。
APIキーについても、IBM Event Streamsの資格情報に設定されている、API Keyをコピーしたものを設定します。
データのマッピングを行いますが、Salesforceから取得できた、JSONのデータを張り付けてマッピングを行います。
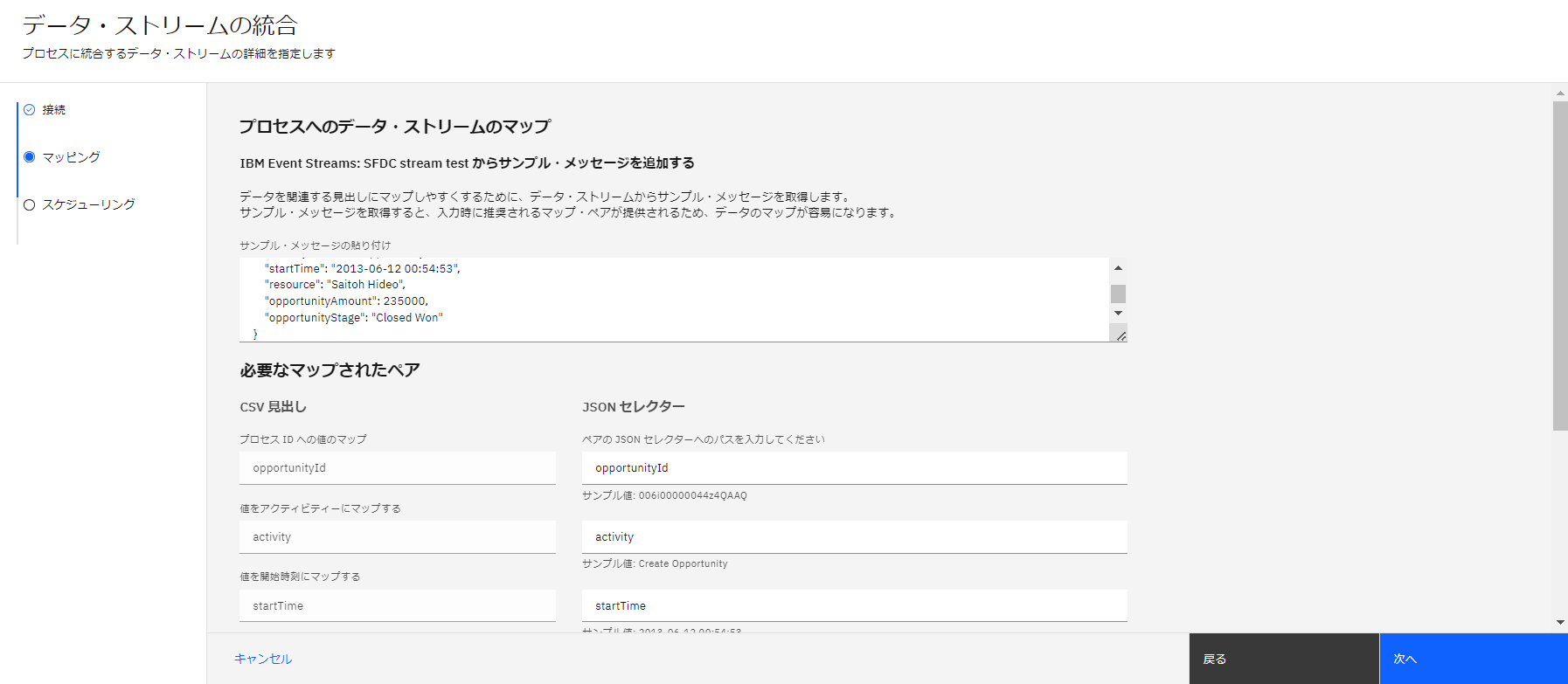
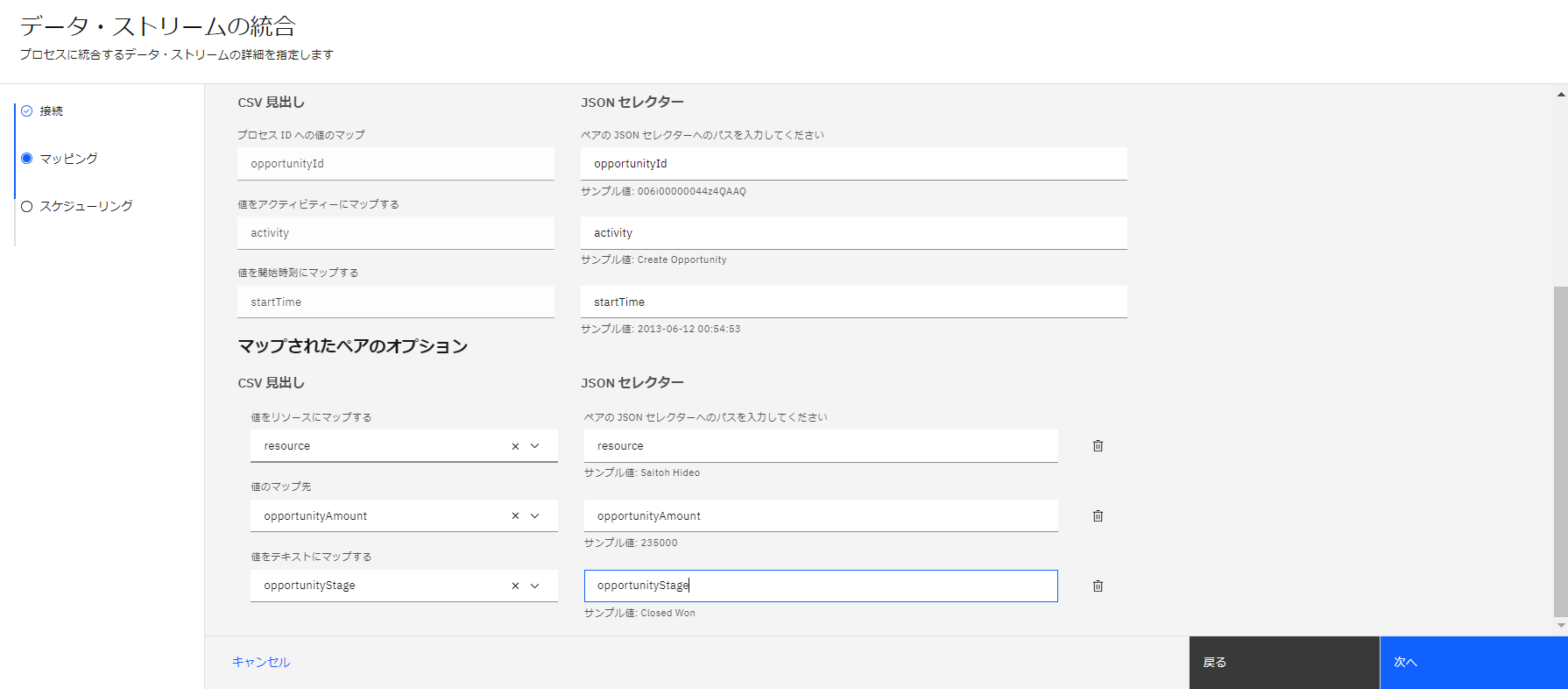
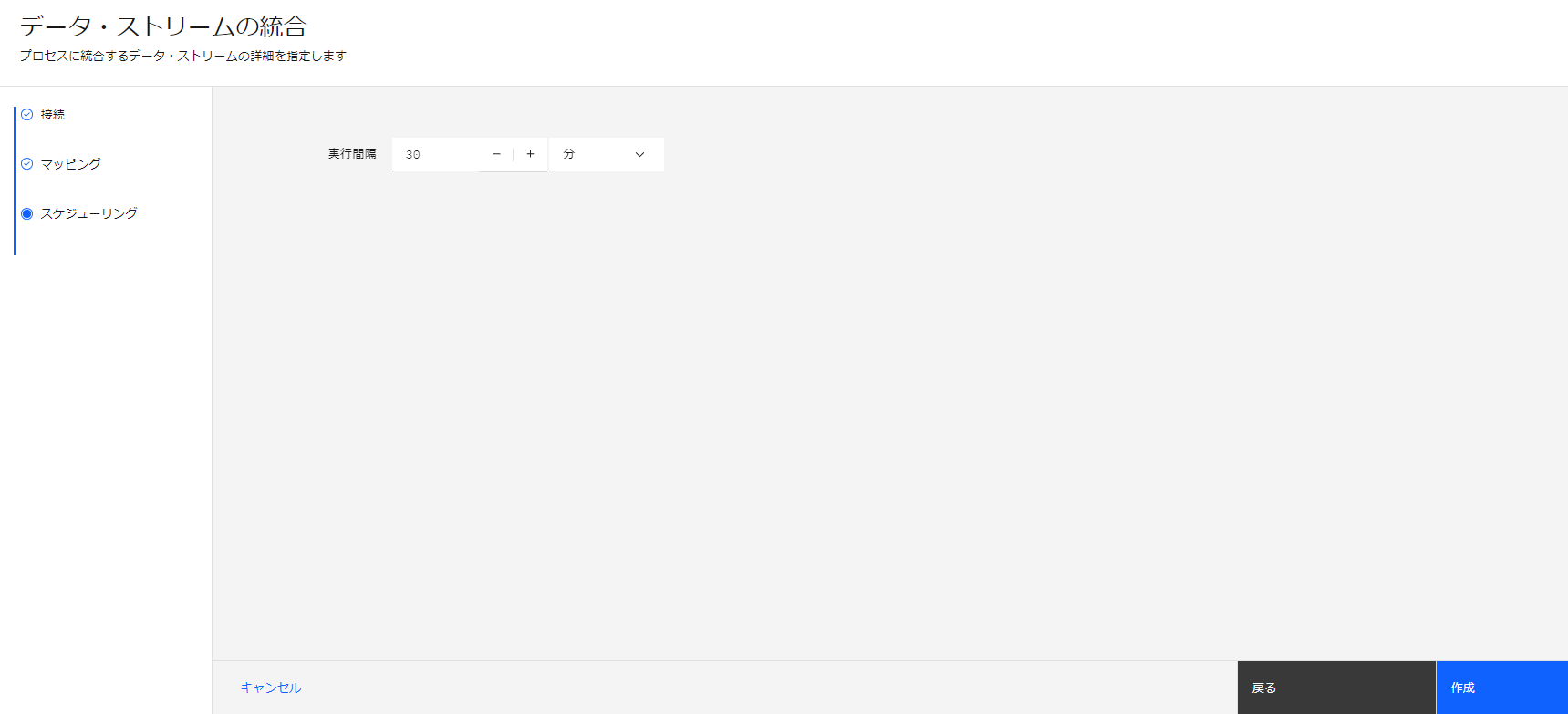
データの取得間隔を設定してデータ・ストリームの定義が完了
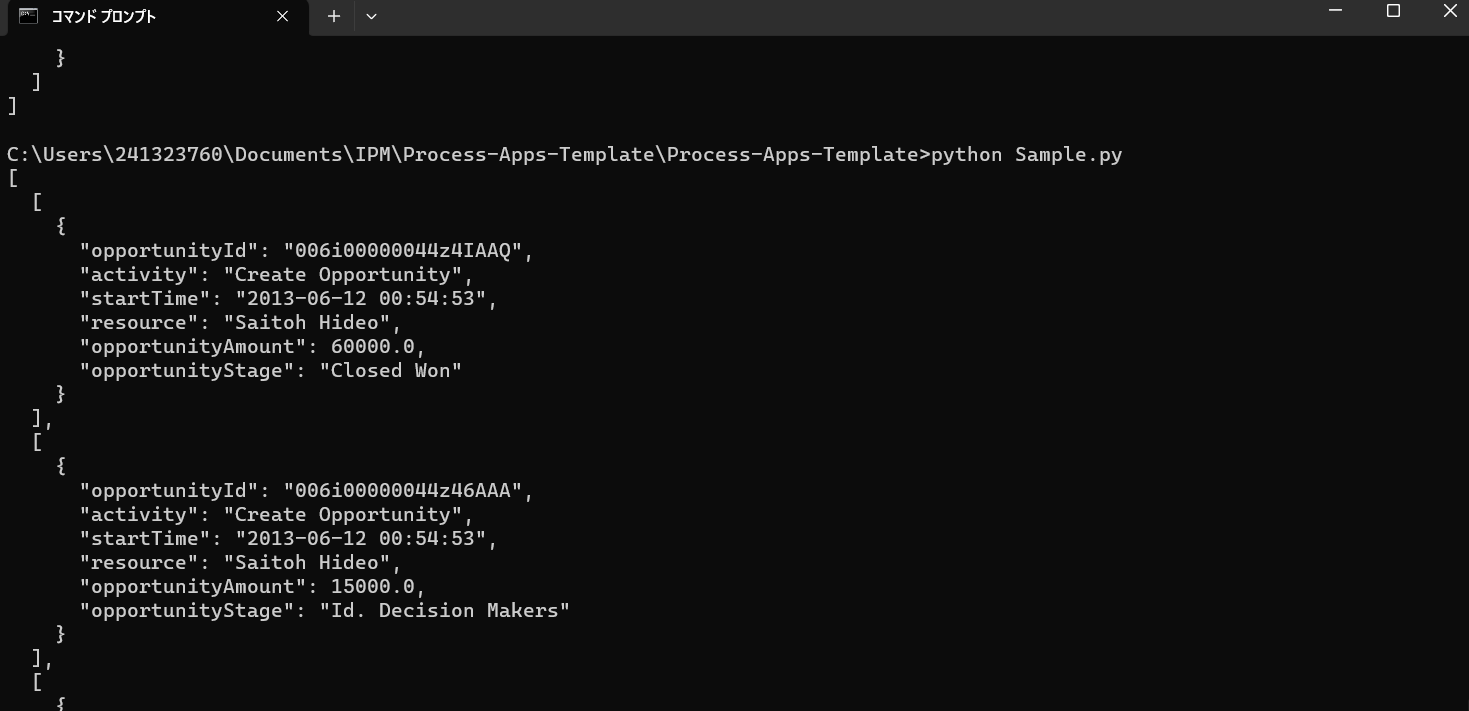
Pythonコードを実行してSalesforceのデータを取り込みます
コマンド・プロンプトから、python Sample.pyを実行して、データの取得とFunctionsへの送信が行われます。
IBM Event Streamsのチュートリアルにあるサンプルコードを使って、ProcessMiningTopicに格納されているデータを参照してみます。
チュートリアルの手順は、こちら
http://localhost:8080を開くと下記のような画面が出てきます。右側の、Start consumingをクリックして、データを参照してみます。
データが取得されると、下記のように出力されます。
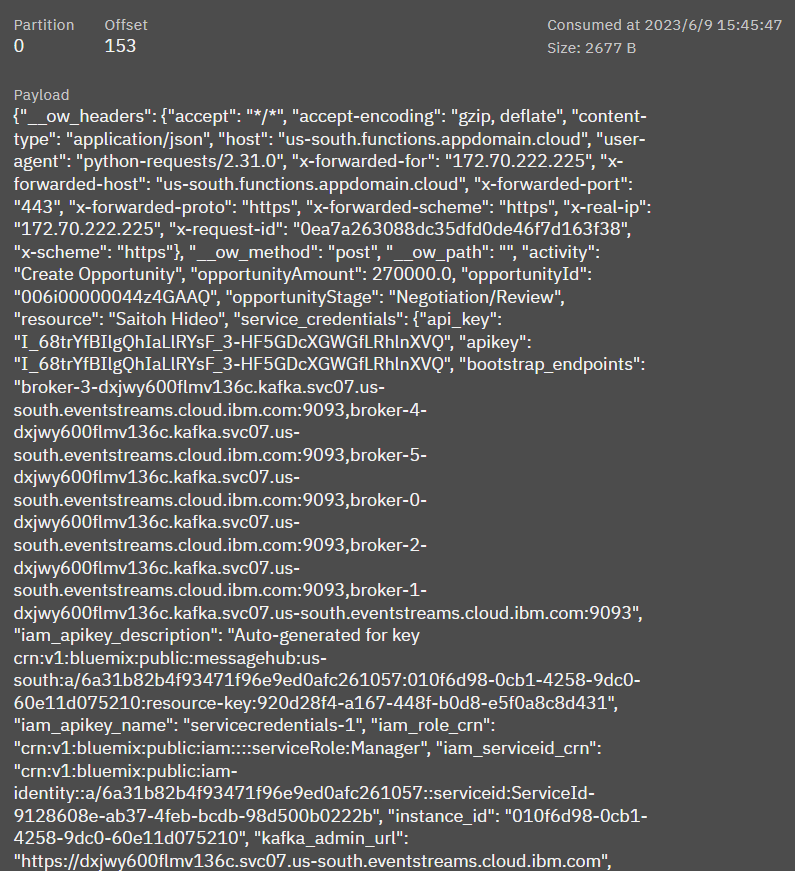
Offset 153のデータを見てみると、opportunityIdやopportunityStageなどのSalesforceから取得したデータであることがわかります。
IBM Event Streamsにデータが取り込まれたので、次は、IBM Process Miningのデータストリームを使って、データを取得します。
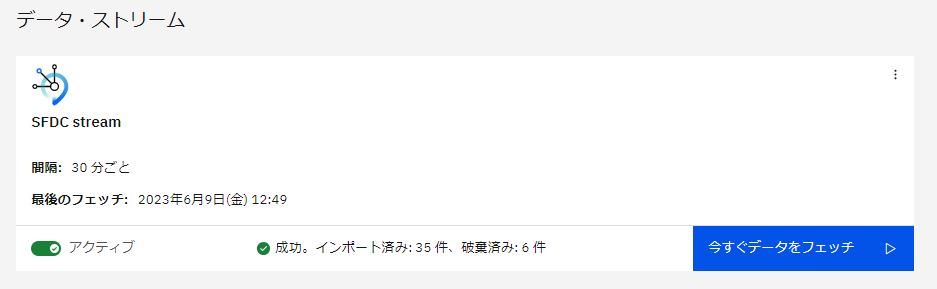
データ・ストリームより、アクティブに設定し、今すぐデータをフェッチします。
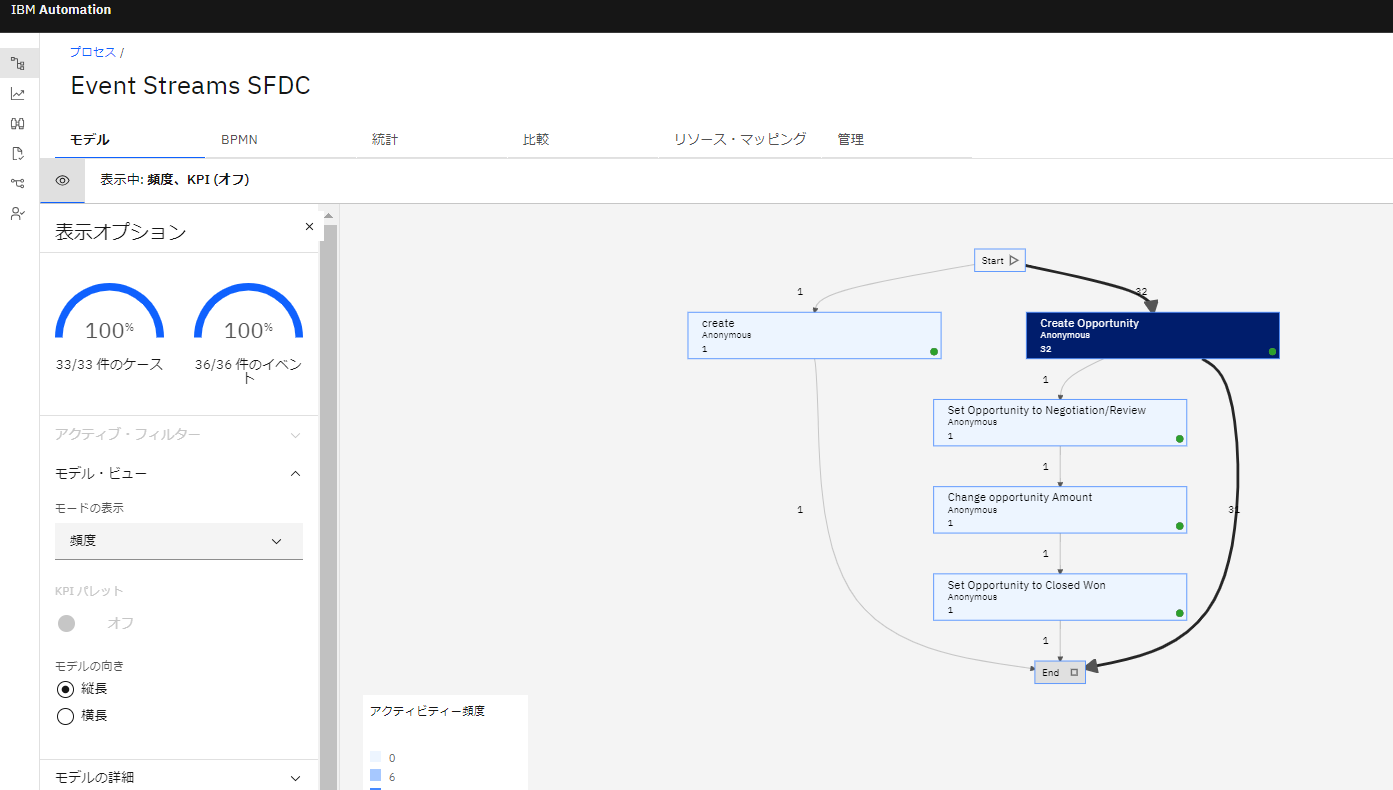
モデル画面を開くと、Salesforceのアクティビティが可視化されていることがわかります。
まとめ
SalesforceのデータをPythonを使って、取得してIBM Event Streamsに格納することで、IBM Process Miningのデータ・ストリーム機能が自動的にデータを取得して、可視化できることがわかりました。
データの抽出・加工は手間のかかる処理ですが、データ・ストリームを使うことで比較的簡単に自動的にデータの取得が可能になります。
#IBM #CloudPakforBusinessAutomation #IBMEventStreams
#ProcessMining#IPM