Introduction
So, you've been testing BAI in your demo environment and now you want to go to production with it?
There are several things that you may have to consider, such as:
- High Availability,
- Security,
- Large data storage requirements
In this article we demonstrate in a step-by-step manner how to achieve superior performance under heavy loads, such as ODM sending 1000 events of 10 KB per second to BAI.
Architecture of BAI
Let's quickly review BAI architecture for version 21.0.2 to better understand what we can do to make BAI even better.
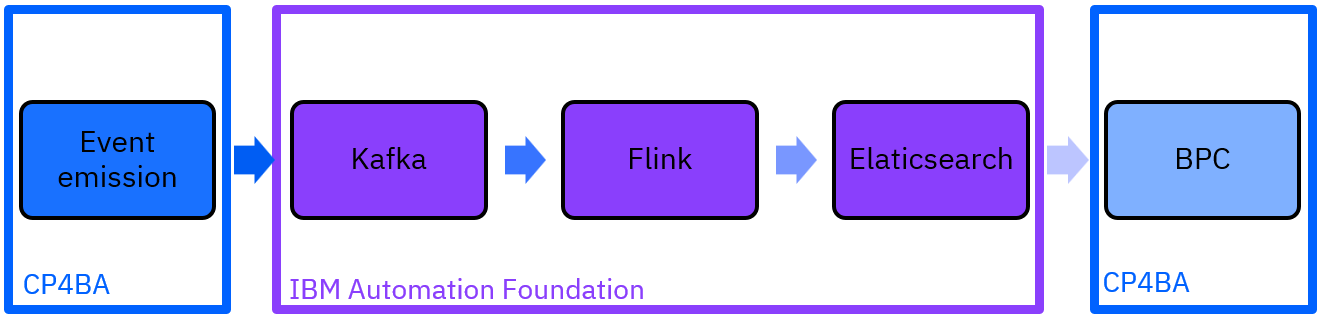
In this release, you'll have the new IBM Automation Foundation (IAF) along with the CloudPak for Business Automation (CP4BA).
The pipeline is the following: each CP4BA components, is sending its own events into Kafka topics. The events are then processed (and transformed if necessary) by Flink, which puts the results into a Elasticsearch. Finally, you can visualize the data in Business Performance Center.
This article will help you to solve the potential bottlenecks of the pipeline.
For instance, if you see a lot of Offset lag (the difference between the total number of messages inside Kafka and the number of messages that remain to be processed), you can tweak Flink & Elasticsearch to avoid this lag. If you see that there are event delays in Kafka, then you should review your Kafka configuration.
1) Set the ideal number of Kafka partitions per topic
Kafka is now installed automatically for you when you install the CloudPak for Business Automation.
However, here are some tuning that you should apply when using the ODM pillar.
We recommend creating the Kafka topic before installing BAI. This way, you'll have full control of the topic properties instead of using BAI pre-defined setting. This allows you to tailor the Kafka settings up to your needs.
Here is an example showing how to manually create a Kafka topic that BAI needs to perform with ODM:
apiVersion: ibmevents.ibm.com/v1beta2
kind: KafkaTopic
name: icp4ba-bai-odm-ingress
spec:
config:
retention.ms: 7200000
partitions: 12
replicas: 3
topicName: icp4ba-bai-odm-ingress
- Use at least 3 partitions per topic (one per broker) x number of parallelisms. In our case, we'll pick 12 partitions (3*4 flink job).
- For the retention, it's up to you to figure out the best compromise between safety and disk usage.
- 3 Replicas, so that if a Kafka broker is down, the 2 others are going to be able to handle the load.
- Each topic should have the same settings as the other.
By using those settings, you'll gain performance from the client Kafka side, which in our case are the CP4BA pillars.
2) Choose the optimal number of Flink parallelism
For each component, you can manually set the number of Flink processing jobs that are going to read the related Kafka topics. "Parallelism" is constrained by the number of partitions in the Kafka topics (parallelism is less than or equal to the number of Kafka Topic partitions).
It is configured in each component's CR file.
Here is an example for ODM:
bai_configuration:
odm:
# The number of parallel instances (task slots) to use for running the processing job.
# For High Availability, use at least 2 parallel instances.
parallelism: 4
In our case, we chose a parallelism value of 4 to have around 250 transactions per second per Flink job.
If you are changing parallelism after installing BAI, you must delete the old Kubernetes job so that it will be recreated with the new configuration.
There is one job per component. For ODM the job is named <cr_instance_name>-bai-odm; just delete it and wait for the CP4BA operator to recreate it.
You will then see new pods named <cr_instance_name>-bai-flink-taskmanager-<number_of_the_pod>.
Having multiple Flink jobs running in parallel on the same Kafka topic will help speed up the ingestion of events from Kafka.
3) Elasticsearch mapping explosion risk
If you are using too many rulesets, you will hit Elasticsearch limitations and BAI will run into issues.
4) Configure your CR to not recreate the automationbase
We are going to modify Elasticsearch pods configuration, but first we need to modify the CR. By this way, the CP4BA operator will not scratch your configuration
Add in the shared_configuration the following flag:
sc_install_automation_base: false
5) Tuned Elasticsearch pods configuration
Inside the same namespace than BAI, you have a resource named "foundation-iaf" of kind "AutomationBase"
You can change the Elasticsearch, Kafka, Zookeeper pods size by modifying this resource.
Increase the Elasticsearch RAM to use 4GB of heap size by following this example:
spec:
elasticsearch:
nodegroupspecs:
- config:
template:
pod:
spec:
containers:
- name: elasticsearch
resources:
limits:
memory: 8Gi
requests:
memory: 8Gi
6) Set the number of shards per index
Now that you have installed BAI, you have to increase the number of shards for Elasticsearch indexes.
The number of shards depends on the number of events per day that you expect to process (event rate).
In our case, we have ODM sending 1000 events per second during a typical workday (8H) and each message is 10KB.This gives us a total of ~28.8 GB per day * (nb replicas - 1). According to the Elasticsearch reference, it's best to have less than 20 GB per active shard. We also want at least 1 shard per data node so that they are all used when making queries on the data; so, we pick 3 shards in our case.
To do this, after BAI has been installed, you will find a Kubernetes ConfigMap inside the same namespace than BAI, named "bai-odm".
Edit that ConfigMap to change the Elasticsearch configuration.
Inside "processing-conf.json", add the index settings like this
{
[... ]
{
"type": "elasticsearch",
"index": {
"settings": {
"index.number_of_shards": 12
},
From now on, for the new indexes created by BAI, you should now have the correct number of shards. Note that due to an Elasticsearch limitation, you cannot edit the number of shards for an already existing index. So, either delete the already created indexes if you don't care about the data that they contain, or re-index all the indexes.
7) Increase Flink processing speed
For ODM, here is how you can boost your Flink processing speed.
Much like the Elasticsearch shard configuration, you need to edit the same file inside the same ConfigMap, add a new "settings" block at the end like the following:
{
"ingresses": [
{
}
],
"egresses": [
}
],
"settings": {
"elasticsearch": {
"bulk.flush.max.actions": 128,
"bulk.flush.interval.ms": 2000
}
}
}
8) Configure Business Performance Center with UMS teams
You can set fine permissions on the data presented in BPC. By default, a team of BPC administrator users is already created for you. You can then map and admin user that will be allowed to set the permissions for the rest of your company.
- Open UMS Teams ( IBM Docs ), then add an user into the team named "BPC Admins".
This means that you now have an administrator user for BPC.
- Finally, log into BPC with an administrator account and set the permissions for the other users by following the Knowledge center procedure: Setting up data permissions - IBM Documentation
Summary
In summary, here is what we've done to tune our pipeline:
We hope that this guide will help you achieve your BAI performance and scalability goals in your production environment.
I couldn't write this article without the collective effort of Johanne Sebaux, Nicolas Peulvast, Pierre-Andre Paumelle, Lionel Peron, Jose De freitas, Peter Gilliver and the whole BAI team.
If you still have some questions or issues, you can post here, we'll try to answer to your questions.
Anthony Damiano