The Turbonomic-Datadog integration combines application performance data with infrastructure data that Turbonomic collects from Datadog to generate full-stack aware, automatable actions that optimize application performance and reduce cost.
This FAQ guide will help the field team and Turbonomic-Datadog integration users to troubleshoot the most common issues that might occur.
- What are the API keys required to add Datadog as a target in Turbonomic?
A valid Datadog user account with read-only API key and Application key access are required to add Datadog as a target in Turbonomic.

- Why are virtual machines missing in the supply chain after the Datadog target has been successfully discovered?
Virtual machines in Turbonomic are discovered by the Cloud targets (AWS, Azure, GCP) or On-prem targets (like VMWare, Hyper-V). These targets that host the virtual machines need to be added as targets in Turbonomic.
- How can I ensure that the Datadog target has been effectively linked to the Cloud or On-prem targets?
When virtual machine entities identified by the Datadog target are stitched with virtual machine entities discovered by the cloud or On-prem target, you will be able to observe the link between the virtual machines and the application components within the supply chain.
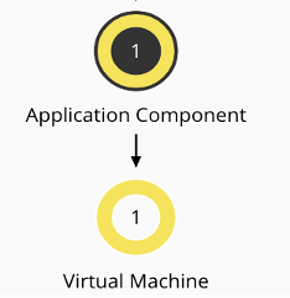
- Why are Datadog services and application components missing in the Turbonomic supply chain, while they are visible in the Datadog UI?
Currently, Turbonomic-Datadog support is focused on servlet-based applications and services. If your application components utilize technologies other than servlets (Tomcat, Websphere and Weblogic are examples of servlet based apps), they will not be visible in the supply chain within the Turbonomic UI.
- Why is the link between services and application components missing in the Turbonomic supply chain?
To establish the link between an application component and service, it is essential to specify the service name and environment value using tags labelled that are labelled as 'service' and 'env' respectively.
These tags can be configured in two ways-
At the application level: In the case of Tomcat application, a dedicated configuration file for Tomcat can be found under the Datadog agent installation folder at "/etc/datadog-agent/conf.d/tomcat.d/conf.yaml"
At the host level: The tags can be set in the Datadog agent configuration file located in the Datadog Agent installation folder at "/etc/datadog-agent/datadog.yaml"
Here is a sample tags element:

Subsequently, while enabling tracing in the environment variable configuration file, it is crucial to provide identical service name and environment value as virtual machine arguments.
Here is an example in the case of a Tomcat application where the virtual machine arguments are specified in the environment variable configuration file (/opt/tomcat/bin/setenv.sh) as

- Why am I unable to view the business application component within the Turbonomic supply chain?
For the Datadog target to be able to identify and establish link between business applications and the underlying entities in the supply chain, it is necessary to specify application tag at the host level in the Datadog.yaml file (/etc/datadog-agent/datadog.yaml).
Business application tag in Datadog.yaml file is specified as 'app-name-tag'.

BUSINESS APPLICATION DATADOG TAG in Turbonomic target configuration page (also refers to app-name-tag)

- Why does the business application appear orphaned in the Turbonomic supply chain?
Currently, Turbonomic-Datadog support is limited to servlet-based apps and services. If a business application relies on technologies other than servlet-based ones (Tomcat, Websphere and Weblogic are examples of servlet-based apps), it will be displayed as orphaned.
- Why am I unable to view the response time and TPS for business applications, business transactions and services despite all of the entities being successfully discovered and displayed in Turbonomic supply chain?
There could be two reasons to not show these metrics in Turbonomic:
If an application has not received any activity within the last 10 minutes
If there are differing environments or host tags configured for a service in the Datadog configuration file
Here is an example of configuring different values for the 'env' tag , one in the application-specific configuration file and the other in the Datadog Agent configuration file:
In Datadog Agent configuration file (/etc/datadog-agent/datadog.yaml)

In application specific configuration file for Tomcat (/etc/datadog-agent/conf.d/tomcat.d/conf.yaml)
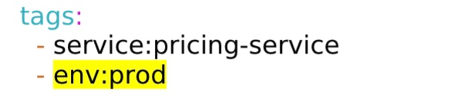
Here is an example of different host tags where the user has explicitly configured the hostname as 'abc', while the actual system hostname provided by the cloud provider could be 'xyz'.

- Why are heap resize actions not being generated for the application component, despite heap usage values falling outside the configured thresholds?
Cloud hosting platforms (AWS, Azure, GCP) or on-prem targets (Like VMWare, Hyper-V) that host the virtual machine must be added as targets in Turbonomic.
- Why am I unable to see all the containers in the Turbonomic supply chain?
Currently, Turbonomic-Datadog integration supports containers deployed through Kubernetes. Containers deployed through alternate methods (Like Rancher, Docker, Swarm, etc) will not appear in the Turbonomic supply chain.
- How do I request support for applications that are currently not supported by Turbonomic-Datadog integration?
Kindly submit an idea on IBM's ideas portal-IBM Idea's Portal
In case you run into an issue not listed above, please open a support ticket - Turbonomic Support